

Since instruction-level parallelism can also be effectively exploited on in-order superscalar processors and very long instruction word
Question:
Since instruction-level parallelism can also be effectively exploited on in-order superscalar processors and very long instruction word (VLIW) processors with speculation, one important reason for building an outof-
order (OOO) superscalar processor is the ability to tolerate unpredictable memory latency caused by cache misses. Thus you can think about hardware supporting OOO issue as being part of the memory system. Look at the floorplan of the Alpha 21264 in Figure 2.36 to find the relative area of the integer and floating-point issue queues and mappers versus the caches. The queues schedule instructions for issue,
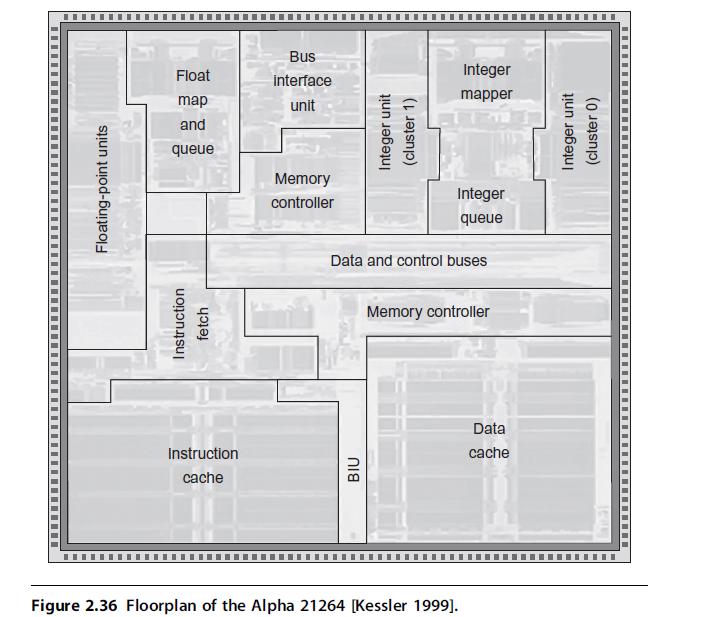
and the mappers rename register specifiers. Therefore these are necessary additions to support OOO issue. The 21264 only has L1 data and instruction caches on chip, and they are both 64 KB two-way set associative. Use an OOO superscalar simulator such as SimpleScalar (http://www.cs.wisc.edu/mscalar/simplescalar.html) on memory-intensive benchmarks to find out how much performance is lost if the area of the issue queues and mappers is used for additional L1 data cache area in an in-order superscalar processor, instead of OOO issue in a model of the 21264.
Make sure the other aspects of the machine are as similar as possible to make the comparison fair. Ignore any increase in access or cycle time from larger caches and effects of the larger data cache on the floorplan of the chip. (Note that this comparison will not be totally fair, as the code will not have been scheduled for the in-order processor by the compiler.)
Step by Step Answer:
a These results are from experiments on a 33GHz Intel Xeon Processor X5680 with Nehalem architecture ...View the full answer



Computer Architecture A Quantitative Approach
ISBN: 9780128119051
6th Edition
Authors: John L. Hennessy, David A. Patterson
