

We can convert all load/store instructions into register-based (no offset) and put the memory access in parallel
Question:
We can convert all load/store instructions into register-based (no offset) and put the memory access in parallel with the ALU. What is the clock cycle time if this is done in the single-cycle and in the pipelined datapath? Assume that the latency of the new EX/MEM stage is equal to the longer of their latencies.
Each pipeline stage in Figure 4.33 has some latency. Additionally, pipelining introduces registers between stages, and each of these adds an additional latency. The remaining problems in this exercise assume the following latencies for logic within each pipeline stage and for each register between two stages:
Figure 4.33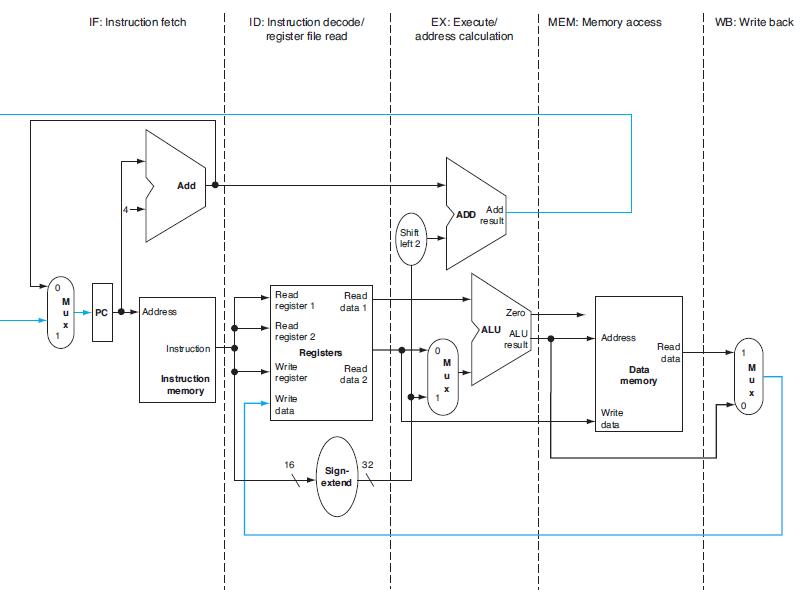
Fantastic news! We've Found the answer you've been seeking!
Step by Step Answer:
For the pipelined datapath each stage operates in paral...View the full answer

Answered By
Fahmin Arakkal
Tutoring and Contributing expert question and answers to teachers and students.
Primarily oversees the Heat and Mass Transfer contents presented on websites and blogs.
Responsible for Creating, Editing, Updating all contents related Chemical Engineering in
latex language
8+ Reviews
22+ Question Solved
Related Book For 

Computer Organization And Design The Hardware Software Interface
ISBN: 9780123747501
4th Revised Edition
Authors: David A. Patterson, John L. Hennessy
Question Posted:
