

Speech recognition systems need to match audio streams that represent the same words spoken at different speeds.
Question:
Speech recognition systems need to match audio streams that represent the same words spoken at different speeds. Suppose, therefore, that you are given two sequences of numbers, X = (x1, x2,...,xn), and Y = (y1, y2,...,ym), representing two different audio streams that need to be matched. A mapping between X and Y is a list, M, of distinct pairs, (i, j), that is ordered lexicographically, such that, for each i ∈ [1, n], there is at least one pair, (i, j), in M, and for each j ∈ [1, m], there is at least one pair, (i, j), in M. Such a mapping is monotonic if, for any (i, j) and (k,l) in M, with (i, j) coming before (k,l) in M, we have i ≤ k and j ≤ l. For example, given
X = (3, 9, 9, 5) and Y = (3, 3, 9, 5, 5),
one possible monotonic mapping between X and Y would be
M = [(1, 1),(1, 2),(2, 3),(3, 3),(4, 4),(4, 5)].
The dynamic time warping problem is to find a monotonic mapping, M, between X and Y , that minimizes the distance, D(X, Y ), between X and Y , subject to M, which is defined as
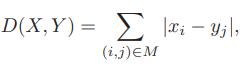
where this minimization is taken over all possible monotonic mappings between X and Y . For instance, in the example X, Y , and M, given above, we have D(X, Y )=0. Describe an efficient algorithm for solving the dynamic time warping problem. What is the running time of your algorithm?
Step by Step Answer:
Define a cost function Ci j which is the best way to match the first i numbers in X to the f...View the full answer



Algorithm Design And Applications
ISBN: 9781118335918
1st Edition
Authors: Michael T. Goodrich, Roberto Tamassia
