

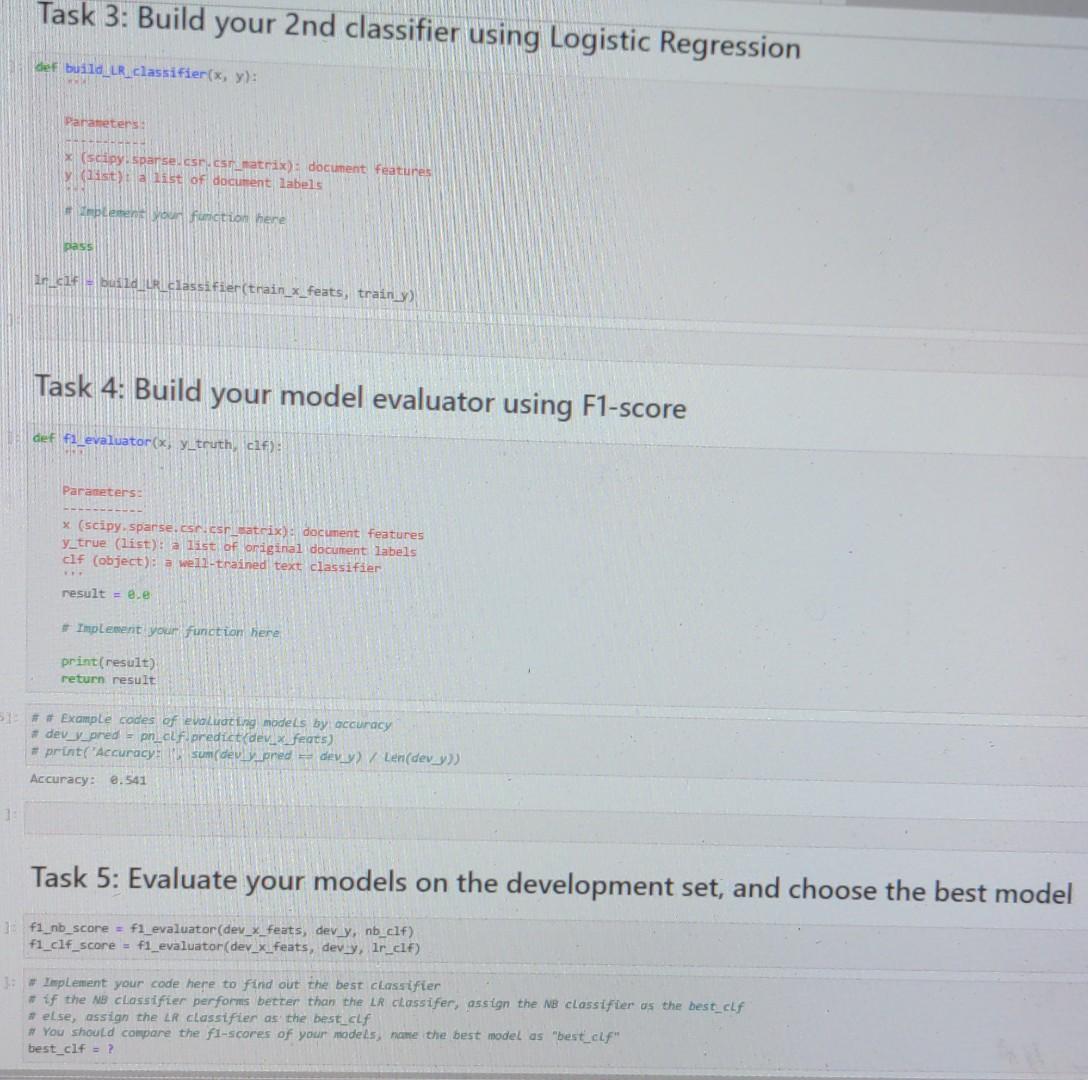
[ ]: 1. Extract features using TF-IDF vectorizer with a feature size 10000 and a ngram...
Fantastic news! We've Found the answer you've been seeking!
Question:
![[ ]: 1. Extract features using TF-IDF vectorizer with a feature size 10000 and a ngram_range as 1-3; (20](https://dsd5zvtm8ll6.cloudfront.net/si.experts.images/answers/2023/10/651dc488845b4_672651dc4887c7ec.jpg)
Transcribed Image Text:
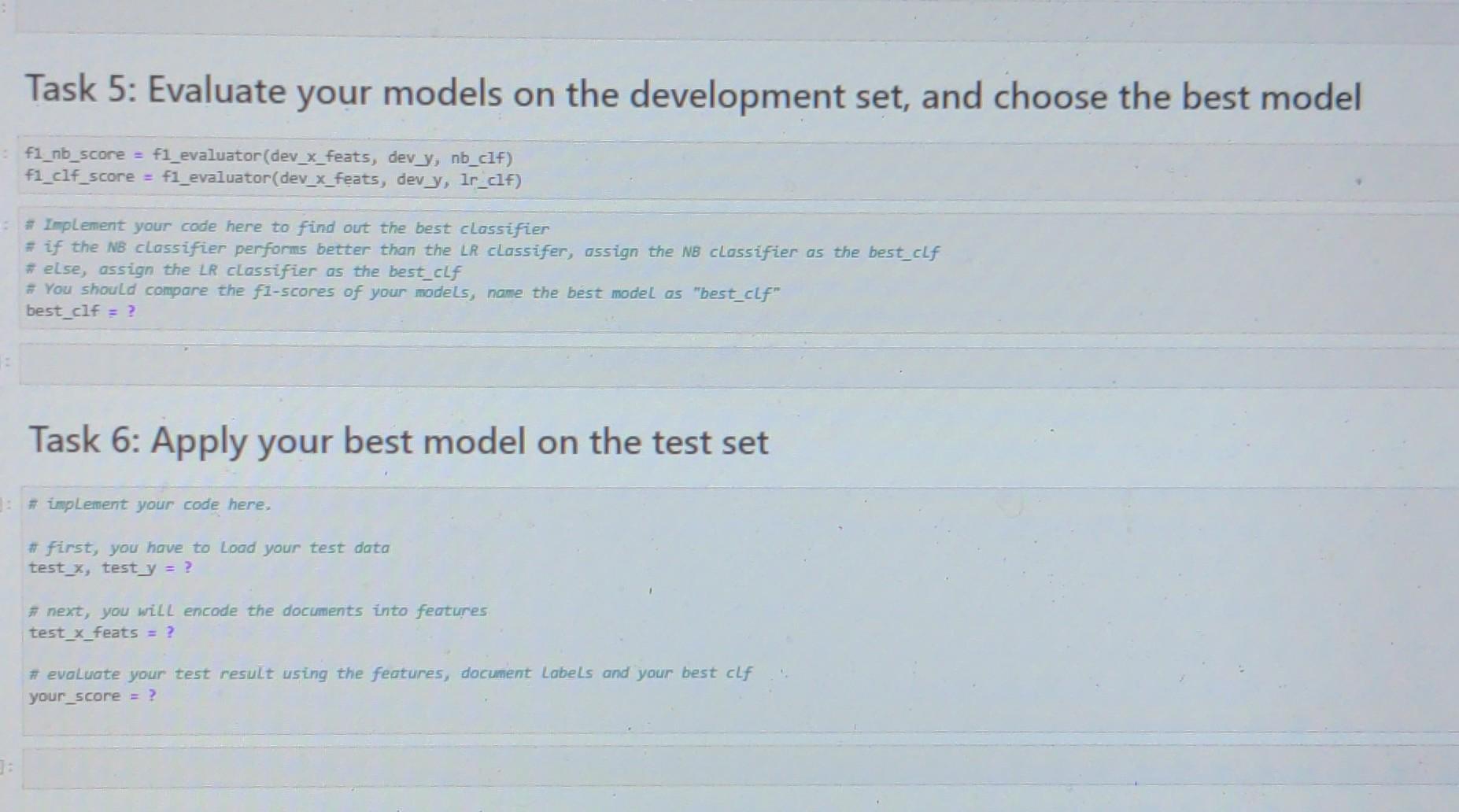
[ ]: 1. Extract features using TF-IDF vectorizer with a feature size 10000 and a ngram range as 1-3; (20 points) 2. Build your 1st classifier using Naive Bayes (20 points) 3. Build your 2nd classifier using Logistic Regression: (20 points) 4. Build your model evaluator using F1-score: (10 points) 5. Evaluate your models on the development set, and choose the best model; (10 points) 6. Apply your best model on the test set and conduct evaluation. (20 points) Note . For this homework, we will use a Python toolkit/package called "scikit-learn. . For the preprocessing, we start with tokenization using NLTKC tokenizer. You may try the other tokenization methods in the last bonus problem. . For the feature extraction, we will use the feature extractors from here scikit-learn. . For the text classifiers, we start with Naive Bayes and Logistic Regression classifiers, but you can explore other classifiers at this page, which has a list of supervised machine learning models. . We will use the evaluation package to evaluate your model performance. Feel free to read through the linked documentation, which will be helpful for you to finish the homework challenges. [1]# you should define all your import packages here from sklearn.linear_model import LogisticRegression, Perceptron from sklearn. feature_extraction.text import CountVectorizer, TfidfVectorizer from sklearn.metrics import f1 score, accuracy_score # Load and preprocess datasets def load_and_preprocess(data_path, test=False): *** Load and preprocess your datasets Parameters: data_path (str): your data path test (bool): if the file is a test file x = [] y = [] with open (data_path) as dfile: cols = dfile.readline().strip().split("\t') review_idx = cols.index('review') rating idx = cols.index( 'rating') for line in dfile: if len(line) < 5: continue line line.strip().split("\t') x.append(line [review_idx]) y.append(int(line[rating idx])) return x, y 0 Python 3 (ipykemel [23:# Load your training, development, and test datasets train_x, train_y= load_and_preprocess('./data/train.tsv') # training set dev_x, dev_y= load_and_preprocess(/data/dev.tsv') # development set test_x, test_y= load_and_preprocess("./data/test.tsv, test-True) # test set Task 3: Build your 2nd classifier using Logistic Regression def build_LR_classifier(x, y): 1: Parameters: x (scipy.sparse.csr.csr_matrix): document features y (list): a list of document labels #Implement your function here pass ir_clf = build_LR_classifier(train_x_feats, train_y) Task 4: Build your model evaluator using F1-score def f1_evaluator(x, y_truth, clf): Parameters: x (scipy.sparse.csr.csr_satrix): document features y_true (list): a list of original document labels clf (object): a well-trained text classifier www result = e.e #Implement your function here print (result) return result 51: ## Example codes of evaluating models by accuracy # dev_y_pred= pn_clf.predict(dev_x_feats) #print("Accuracy: sum(dev_y_pred dev_y) / Len(dev_y)) Accuracy: 0.541 Task 5: Evaluate your models on the development set, and choose the best model 1f1_nb_score= f1_evaluator (dev_x_feats, dev_y, nb_clf) f1_c1f_score= f1_evaluator(dev_x_feats, dev_y, lr_clf) 3:# Implement your code here to find out the best classifier # if the NB classifier performs better than the LR classifer, assign the NB classifier as the best clf #else, assign the LR classifier as the best clf # You should compare the fl-scores of your models, name the best model as "best_clf" best_clf = ? Task 5: Evaluate your models on the development set, and choose the best model :f1_nb_score = f1_evaluator (dev_x_feats, dev_y, nb_clf) f1_c1f_score= f1_evaluator (dev_x_feats, dev_y, lr_clf) # Implement your code here to find out the best classifier # if the NB classifier performs better than the LR classifer, assign the NB classifier as the best clf # else, assign the LR classifier as the best clf # You should compare the f1-scores of your models, name the best model as "best_clf" best_clf = ? Task 6: Apply your best model on the test set 1: # implement your code here, # first, you have to Load your test data test_x, test_y = ? #next, you will encode the documents into features test_x_feats = ? # evaluate your test result using the features, document Labels and your best clf your_score = ? [ ]: 1. Extract features using TF-IDF vectorizer with a feature size 10000 and a ngram range as 1-3; (20 points) 2. Build your 1st classifier using Naive Bayes (20 points) 3. Build your 2nd classifier using Logistic Regression: (20 points) 4. Build your model evaluator using F1-score: (10 points) 5. Evaluate your models on the development set, and choose the best model; (10 points) 6. Apply your best model on the test set and conduct evaluation. (20 points) Note . For this homework, we will use a Python toolkit/package called "scikit-learn. . For the preprocessing, we start with tokenization using NLTKC tokenizer. You may try the other tokenization methods in the last bonus problem. . For the feature extraction, we will use the feature extractors from here scikit-learn. . For the text classifiers, we start with Naive Bayes and Logistic Regression classifiers, but you can explore other classifiers at this page, which has a list of supervised machine learning models. . We will use the evaluation package to evaluate your model performance. Feel free to read through the linked documentation, which will be helpful for you to finish the homework challenges. [1]# you should define all your import packages here from sklearn.linear_model import LogisticRegression, Perceptron from sklearn. feature_extraction.text import CountVectorizer, TfidfVectorizer from sklearn.metrics import f1 score, accuracy_score # Load and preprocess datasets def load_and_preprocess(data_path, test=False): *** Load and preprocess your datasets Parameters: data_path (str): your data path test (bool): if the file is a test file x = [] y = [] with open (data_path) as dfile: cols = dfile.readline().strip().split("\t') review_idx = cols.index('review') rating idx = cols.index( 'rating') for line in dfile: if len(line) < 5: continue line line.strip().split("\t') x.append(line [review_idx]) y.append(int(line[rating idx])) return x, y 0 Python 3 (ipykemel [23:# Load your training, development, and test datasets train_x, train_y= load_and_preprocess('./data/train.tsv') # training set dev_x, dev_y= load_and_preprocess(/data/dev.tsv') # development set test_x, test_y= load_and_preprocess("./data/test.tsv, test-True) # test set Task 3: Build your 2nd classifier using Logistic Regression def build_LR_classifier(x, y): 1: Parameters: x (scipy.sparse.csr.csr_matrix): document features y (list): a list of document labels #Implement your function here pass ir_clf = build_LR_classifier(train_x_feats, train_y) Task 4: Build your model evaluator using F1-score def f1_evaluator(x, y_truth, clf): Parameters: x (scipy.sparse.csr.csr_satrix): document features y_true (list): a list of original document labels clf (object): a well-trained text classifier www result = e.e #Implement your function here print (result) return result 51: ## Example codes of evaluating models by accuracy # dev_y_pred= pn_clf.predict(dev_x_feats) #print("Accuracy: sum(dev_y_pred dev_y) / Len(dev_y)) Accuracy: 0.541 Task 5: Evaluate your models on the development set, and choose the best model 1f1_nb_score= f1_evaluator (dev_x_feats, dev_y, nb_clf) f1_c1f_score= f1_evaluator(dev_x_feats, dev_y, lr_clf) 3:# Implement your code here to find out the best classifier # if the NB classifier performs better than the LR classifer, assign the NB classifier as the best clf #else, assign the LR classifier as the best clf # You should compare the fl-scores of your models, name the best model as "best_clf" best_clf = ? Task 5: Evaluate your models on the development set, and choose the best model :f1_nb_score = f1_evaluator (dev_x_feats, dev_y, nb_clf) f1_c1f_score= f1_evaluator (dev_x_feats, dev_y, lr_clf) # Implement your code here to find out the best classifier # if the NB classifier performs better than the LR classifer, assign the NB classifier as the best clf # else, assign the LR classifier as the best clf # You should compare the f1-scores of your models, name the best model as "best_clf" best_clf = ? Task 6: Apply your best model on the test set 1: # implement your code here, # first, you have to Load your test data test_x, test_y = ? #next, you will encode the documents into features test_x_feats = ? # evaluate your test result using the features, document Labels and your best clf your_score = ?
Expert Answer:
Answer rating: 100% (QA)
It seems like youre working on building and evaluating text classifiers using Naive Bayes and Logistic Regression models Lets go through each task ste... View the full answer

Related Book For 

Artificial Intelligence A Modern Approach
ISBN: 9780134610993
4th Edition
Authors: Stuart Russell, Peter Norvig
Posted Date:
Students also viewed these programming questions
-
What is Financial Forecasting and it's components and importance of Financial Forecasting with example? Explain the advantages and disadvantages of Financial Forecasting?
-
David, an actuary, is explaining that insurance rates should have five characteristics. Which one of the following correctly describes what David means when he says that rates should provide for...
-
Planning is one of the most important management functions in any business. A front office managers first step in planning should involve determine the departments goals. Planning also includes...
-
The input file for this assignment is Weekly_Gas_Average.txt. The file contains the average gas price for each week of the year. Write a program that reads the gas prices from the file into an...
-
The tractor is used to push the pipe of weight W. To do this it must overcome the frictional forces at the ground, caused by sand. Assuming that the sand exerts a pressure on the bottom of the pipe...
-
Q-17:- What will be the total electric flux, o, if charges q = 1.85x10-12 C, q2 = -3.010-12 - C and q3 = 10.0x10-12 C and the constant &o= 8.85x10-12 NmC-2
-
(a) How many variables are included in the scatterplot in Figure 2.84(a)? Identify each as categorical or quantitative. Estimate the range for Variable1 and for Variable2. (b) In Figure 2.84(a), does...
-
In 2010, Amir ante Corporation had pretax financial income of $168,000 and taxable income of $120,000. The difference is due to the use of different depreciation methods for tax and accounting...
-
Tax Optimization Mastery This activity will provide practical insights into tax optimization, demonstrating the importance of the 6 2 5 1 form for individuals with specific income streams and...
-
In 1913, how long did the average worker stay with the plant? What was the average tenure of a worker? Assume the one-millionth vehicle was produced in 1916 at a cost of $8084 (in 2013 US$). By how...
-
Find the derivative. f(x) = 2ln(x + 6) Samples for typing similar answers: 8 For writing 3e*. type 3e^x-8/x X For writing. Question 2 8x x4+2 Find the derivative. In(x) f(x)= 6x type -8x^3/(x^4+2)...
-
Charlie has $10,000 to invest for a period of 5 years. The following three alternatives are available to him: Account 1 pays 4 percent for year 1, 6 percent for year 2, 8 percent for year 3, 10...
-
What words comprise the acronym DCF? Describe/define what it means in 10 words or less.
-
A $3,000 loan is to be made over 5 years with 12 percent interest. Determine how much will be required to pay off the loan plus interest if a. simple interest is used. b. compound interest is used.
-
You are planning to pursue a MS degree in engineering. The program will require 2 years, at which time you will likely go to work in the same city. You have decided to purchase a house and live in it...
-
Sydney just opened a savings account with an initial deposit of $2,500. The interest rate starts at 2 percent compounded annually and doubles every 4 years. a. How much will Sydney have in the...
-
PEJ Determine the angle x in the triangle given below with AB = 9 and BC = 10. Hint: Use the Law of Sines along with a double-angle formula. a) Oz= 1/- - arccos b) O z = arcsin c) Oz = arccos d) z =...
-
By referring to Figure 13.18, determine the mass of each of the following salts required to form a saturated solution in 250 g of water at 30 oC: (a) KClO3, (b) Pb(NO3)2, (c) Ce2(SO4)3.
-
Consider the following scenario: Two players (N = {1, 2}) must choose between three outcomes = {a, b, c}. The rule they use is the following: Player 1 goes first, and vetoes one of the outcomes....
-
Write out a general algorithm for answering queries of the form P(Cause|e), using a naive Bayes distribution. Assume that the evidence e may assign values to any subset of the effect variables.
-
Experiment with online sequence-to-sequence neural machine translation model, such as translate.google.com/ or www.bing.com/translator or www.deepl. com/translator. If you know two languages well,...
-
A diver leaps from a high platform, speeds up as she falls, and then slows to a stop in the water. How do you define the system so that the energy changes are all transformations internal to an...
-
When your hands are cold, you can rub them together to warm them. Explain the energy transformations that make this possible.
-
Figure Q10.24 shows a potential-energy diagram for a particle. The particle is at rest at point A and is then given a slight nudge to the right. Describe the subsequent motion. FIGURE Q10.24 Energy...

Study smarter with the SolutionInn App