

1 Summary Develop a competitive AI for the game Mancala Demonstrate your understanding of...
Fantastic news! We've Found the answer you've been seeking!
Question:












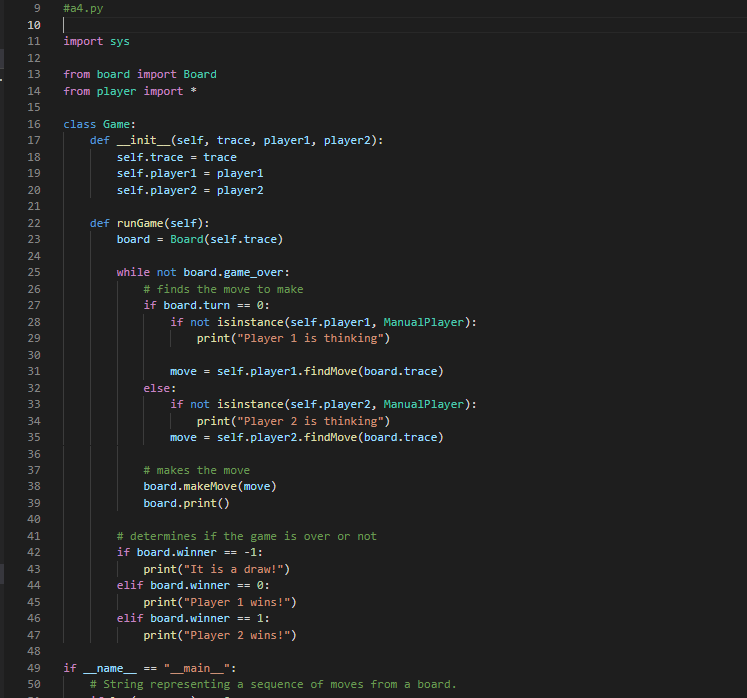
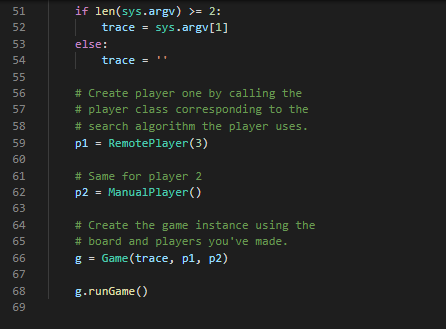
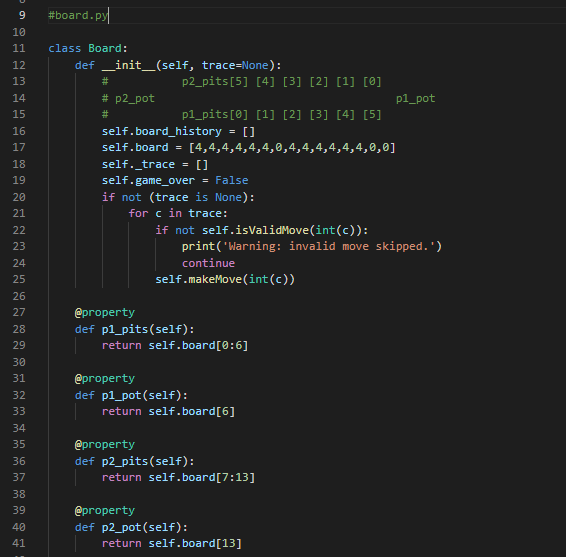
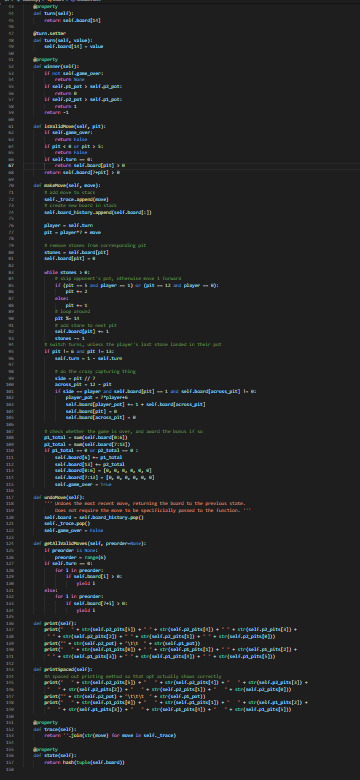
Transcribed Image Text:
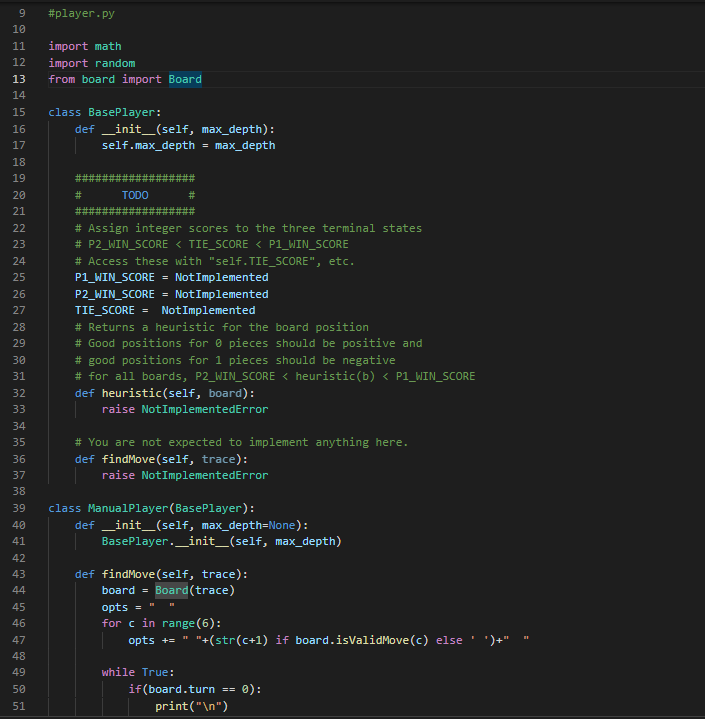
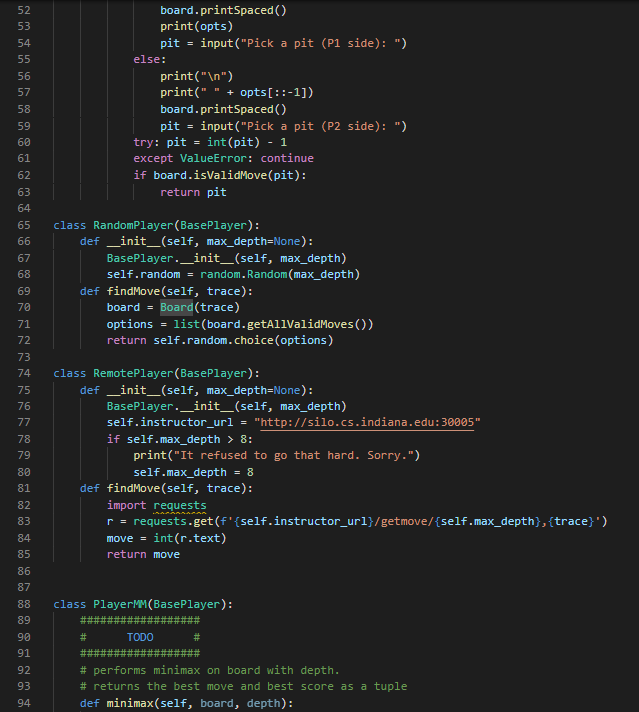
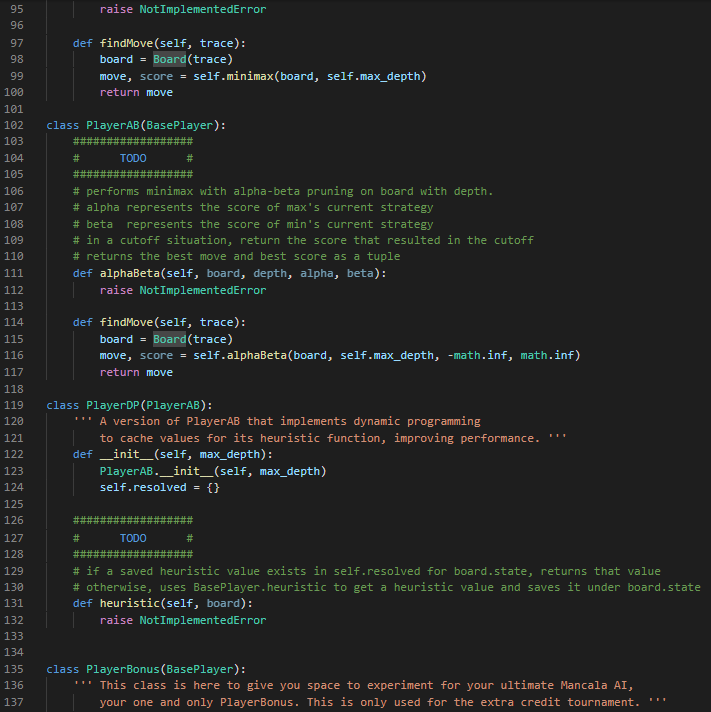
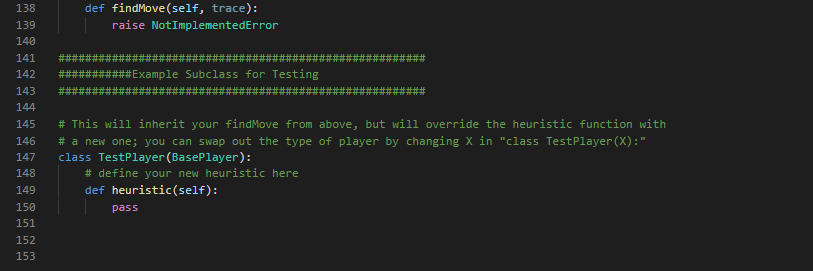
1 Summary • Develop a competitive AI for the game Mancala • Demonstrate your understanding of the MiniMax search algorithm, alpha- beta pruning, and dynamic programming We will be using Python 3 so be sure you aren't using older versions. Code that will compile in Python 2.7 may not compile in Python 3. See our installation guide for help removing old versions and installing Python 3. To run your completed programs against our instructor AI, you may want to install the requests module. You will do utilizing pip and using your terminal to execute the command python -m pip install requests. If your code still does not run due to missing modules, please come by office hours. 2 Background Mancala is a two-player, turn-based strategy game where the objective is to collect the most pieces by the end of the game. To play a game, you need a Mancala board, which is a board made up of two rows of six pockets, also known as pits, and two "stores" located at the ends of these pits. 2.1 Rules 1. Each turn consists of a player picking up all the pieces in a pit and, moving counter-clockwise, deposit a stone in each pocket until the stones run out. 1 When moving your stones, if you pass your store then you deposit one stone inside it as well, but you skip over your opponent's store. 2. If the last piece you place goes into your store, you take another turn. 3. If the last piece you place is in an empty space on your side, and your opponent has stones in the pit exactly opposite of this empty space¹, then you collect all the stones in your opponent's opposite pit as well as your last placed stone. 4. The game is over when all the stones on one side of the board are gone, and when this happens the other player takes all their stones on their side and puts them in their store. 5. To score the game, each player counts up the total number of stones in their store. The player with the most stones wins! For those of you who have never played Mancala before this might seem like an overload of information. If you are confused about the structure/rules of the game, please visit the following links for more detailed explanations with visuals: https://www.scholastic.com/content/dam/teachers/blogs/ alycia-zimmerman/migrated-files/mancala_rules.pdf and https: //endlessgames.com/wp-content/uploads/Mancala_Instructions.pdf. When designing a heuristic, it is vitally important to understand how the game is played. Because of this, we highly suggest that you play a couple of games to really understand the underlying rules and strategies. The following link will take you to a website where you can play some practice games against a computer which is a great way for beginners to learn the game: https://mancala.playdrift.com/. We also hope to share a brief video of ourselves playing the game to illustrate some of the rules. 3 Programming Component In this assignment's programming component, you will implement an artificial intelligence agent that can competitively play Mancala. To achieve this, you will implement three key algorithms: MiniMax, alpha-beta pruning, and dynamic programming. Additionally, you will develop your own heuristic function to help evaluate maximum depth nodes in your game tree search. Note that this rule differs slightly from the rules linked, which do not require your opponent have stones in their pit to make an "empty capture". However, this is consistent with the interactive website linked, and with how the game is most often played. 2 3.1 Game Data Structures. You will utilize the following classes. You should read and understand this section before embarking on your assignment. 1. Board Class The Board class is the data structure that holds the Mancala, board and the game operations. The data structures that hold the current board state and the historical states are Python lists, but you will primarily be interfacing with them through the pl-pits, p2-pits, pl-pot, p2-pot, and turn properties. pl-pits and p2-pits are both lists which contain integers indexed from 0-5 representing how many stones a player has in a given pit. The indices for these lists increase counter-clockwise (an illustration of this can be seen at the top of the init_() function.) p1-pot and p2.pot. contain the integer value of how many stones each player has in their store (and has therefore scored) so far. turn is an integer, which is 0. when it is player 1's turn and 1 when it is player 2's turn. Note that the Board class also contains a list called trace, which contains a list of moves made so far. Traces are usually used for debugging and replaying what moves led to a board state. You can access a convenient string representation of the trace through the trace property. You will use the following methods, properties, and attributes to interact with the board: (a) __init__([trace]) - This constructor function can be utilized in two ways: i. no args If no arguments are passed, the constructor function. generates a new board with 4 stones in each pit. ii. trace - If the trace argument is set to a valid string of moves, then the constructor function generates a new Board object. based on that trace. (b) makeMove (pit) - This function "picks up" all of the stones in the given pit, and places the stones according to Mancala rules. It also records the move in trace, and saves a copy of the previous board. in board history for later recovery. The function automatically picks up stones from the side of whoever's turn it is. NOTE: This function does not perform any error checking by default. It is the responsibility of the user to ensure that proper non-empty pit is 3 passed. See getAllValidMoves () for an example of proper usage. (c) undoMove () This will undo the last move made on a board, returning the board to the most recent state in the history, and updating the history, trace, and game over variables appropriately. (d) getAllValidMoves ( [preorder]). This generates a series of all the valid moves of the Board object. You may optionally pass a prior ordering that will influence the order in which moves are considered and returned. (e) print () This prints a graphical representation of the current board state to your terminal. (f) board - board is a 15-item integer array containing (in order) the first player's six pits, the first player's store, the second player's six pits, the second player's store, and the next player to play. All of this data is more easily accessed through different properties. (g) pl pot, pl pits. p2 pot, p2.pits - These properties allow you to access information about the current state of the board. p1-pot and p2 pot are integers; p1.pits and p2 pits are six-item integer arrays, arranged counterclockwise. (For instance, p1-pits [0] is opposite to p2-pits [5].) These properties are often used in your heuristic functions. (h) turn- - This property is 0 when it is currently player 1 (max)'s turn and 1 when it is currently player 2 (min)'s turn. This property is i used to determine whether to minimize or maximize in your minimax functions. (i) game over This attribute is True when the game is over and False otherwise. (j) winner - This property (not function) contains a value representing the terminal state of the game. If the game is over, it will contain -1 for a draw, 0 for a player one win, or 1 for a player two win. If the game is not over, it will evaluate to None. (k) trace This property (not function) contains a convenient string representing the sequence of moves that led to the current state of the board. This can be used to easily recreate another similar board, and is used in our debugging and grading tools. (1) state This property (not function) contains an integer representing the current state of the board. Note that two different traces might lead to the same state. state is used in the dynamic 4 programming portion of this assignment. 2. Player Class In this class, you will implement your search algorithm. This class is utilized by the Game class to simulate a game using your AI. The base player class must define constants P2_WIN_SCORE, TIE SCORE. and P1_WIN SCORE to represent scores for the different end states of the game. You will work with the following common to all Players: (a) findMove (trace) - This will return the optimal move for trace upon executing a game tree search up to the Player's max_depth. It will call an appropriate function according to the particular algorithm. the player uses. Some Player subclasses do very unusual things here! (b) heuristic (board) - This function returns a value representing the "goodness" of the board for each player. Good positions for Player 1 will return high values. Good positions for Player 2 will return low (or highly negative) values. As explained later, it is your responsibility to implement this function. We provide the following subclasses of BasePlayer: (a) RandomPlayer this subclass randomly selects one of the valid moves to execute each turn. (b) ManualPlayer - this subclass lets you play directly against your AI. Very fun! (c) RemotePlayer this subclass lets you play against the same instructor AI you are tested against on the Gameplay criterion. (You are tested with the instructor AI at a depth of five.) This subclass depends on the requests library. You will implement your search algorithms in the subclasses of BasePlayer following the instructions in the next section. Additionally, you can create subclasses of your various Players with different heuristic functions in order to test your heuristics against each other locally. We have provided an example of how to accomplish this. 3. Game Class This class is found within the a4.py file. This contains the interface for testing your search algorithms. You will work with the following functions: 5 (a) runGame () This will simulate a game using the AI agents that you create using your Board and Player classes. In particular, it will test if your search strategy was implemented properly and can be used to test heuristics against each other. You may find it beneficial to change the implementation and parameters of one or many of the above functions/classes in order to increase the efficiency of your code. Edits are not only accepted, but they are expected. (except where explicitly banned). That being said, please note that your changes must be able to interface with the functions in the a4.py file (Game class) and test cases. Failure to achieve this will preclude you from receiving any bonus, and will likely result in significant loss of points. You must define each of the homework functions to the specification outlined, except in your bonus player and board classes. 3.2 Objectives Your goal is to complete the following tasks. It is in your best interest to complete them in the order that they are presented. 3.2.1 BasePlayer.heuristic() You must complete the heuristic() function in the BasePlayer class to return a game state value that reflects the "goodness of the game. Remember, the better the game state for Player 1, the higher the score; the better the game state for Player 2, the lower the score (can and probably should be negative). Take into account whether it is valuable to control more. or fewer stones, how late into the game it is, and anything else you find. relevant. Additionally, you must define P2_WIN_SCORE, TIE_SCORE, and P1_WIN_SCORE so that all heuristic values fall between the two players' win scores. As this function will be called at almost every leaf node in your MiniMax search, you will want your function to be as efficient as possible. Note: While you may test your heuristic in different subclasses, the final heuristic that you'd like to be evaluated on must be in the main BasePlayer class. 3.2.2 MiniMax Search Your goal in this section is to develop a generic MiniMax search algorithm. without any optimizations (i.e., alpha-beta). For a reference to this algorithm, 6 you may revisit the lecture slides or see the following Wiki page: https://en.wikipedia.org/wiki/Minimax. In your PlayerMM class you will find the minimax () function where you must. implement the search algorithm. When creating your search algorithm, please consider the following: 1. The function should ultimately return the pit that represents the best move for the player. 2. Your algorithm should correctly identify end positions and assign them the correct value constant without doing any unnecessary processing. Please note that this can be trickier than it looks, so be sure that you think. carefully about your value assignments and use the constants you defined for all Player classes. 3. Your algorithm should correctly stop at maximum depth and return the appropriate heuristic value. 4. You should keep track of whose turn it is and where you are relative to the maximum depth. 5. You should always explore all possible children (except when you have reached maximum depth). If you have successfully completed this section, and Player.heuristic (), you should be able to run runGame in the Game class and achieve meaningful results (i.e., it will play a Mancala game to completion). Do not proceed until this works properly. 3.2.3 Alpha-Beta Pruning Your goal in this section is to implement alpha-beta pruning in the MiniMax search algorithm that you developed in the previous section. For a reference to this pruning technique, you may revisit the lecture slides or see the following Wiki page: https://en.wikipedia.org/wiki/Alpha%E2%80%93beta_pruning. For this, you will implement the alphaBeta () function of the PlayerAB class, and you should continue to ensure that it returns the best column to move in for the player. When implementing alpha-beta pruning, please consider the following: 1. You should update both alpha and beta whenever appropriate. 2. You should identify the correct pruning conditions and that you place. break statements in the correct locations. 7 When implemented correctly, your new MiniMax algorithm should run significantly faster than the one you initially developed. That being said, it should emit exactly the same answer (for the same depth). 3.2.4 Dynamic Programming Your goal in this section is to implement dynamic programming in the MiniMax search algorithm that you developed in previous sections. For a reference to dynamic programming, you may revisit the lecture slides. For this, you will implement the heuristic() function of the PlayerDP class. Keep in mind that this is overriding the heuristic() function of BasePlayer. To access that function, you may call BasePlayer.heuristic (self, board) or super().heuristic (board). Your implementation must not differ from the heuristic value returned by BasePlayer When implementing dynamic programming, please consider the following: 1. Remember that you cannot store objects as keys in hash maps because they are mutable. Instead you will need to use a hashable representation of your Board objects. Fortunately, this is already provided to you in Board.state. 2. You must use self.resolved to store the lookup table for your dynamic programming. We will be using this to test and grade this section of the assignment. As with alpha-beta pruning, your new Alpha-Beta algorithm with dynamic programming will likely run significantly faster (depending on how expensive your heuristic is) than the one you initially developed. That being said, it should emit exactly the same answer (for the same depth). 4 Tests Very simple tests have been given for you in player_test.py for the functions you implemented. Running the main of these files will run the tests. Be sure to use these to make sure your implementations are working generally as requested. These test cases are NOT all encompassing. Passing these does not mean your implementation is completely correct. In order to save submissions, it is advised to write additional unit tests for more complex puzzles as well as to cover cases that these tests do not. In player_test.py we provide some ideas as to what else you should test on your own. This isn't required, but it is highly recommended, as learning to debug on your own is an important skill. Once all of your functions have been completed, you can also test with the main function in a4.py. Additionally, you can and should utilize traces as an extra debugging tool. 8 5 Grading Problems are weighted according to the percentage assigned in the problem title. For each problem, points will be given based on the criteria met in the corresponding table on the next page and whether your solutions pass the test. cases on the online grader. Finally, remember that this is an individual assignment. 5.1 BasePlayer (5%) Criteria P2 WIN SCORE, TIE SCORE, P1_WIN SCORE all real-valued (and not infinity) P2_WIN SCORE < TIE_SCORE < P1_WIN_SCORE Heuristic is real-valued on all boards Heuristic always falls between P2_WIN SCORE and P1 WIN_SCORE Total 5.2 minimax (logic) (15%) Criteria (Game over) Returns a null move and the appropriate score constant for board's terminal state (Not base case) Calls board.getAllValidMoves() exactly once, optionally specifying a an order on the pits Calls and base case) (Not (Not board.makeMove (pit) board. undoMove ( e(pit) exactly once for each valid move 2 (Non-end state & depth 0) Returns a null move and the heuristic value for board Points 1 5.3 minimax (correctness) (10%) 1 1 2 5 Criteria The arrangement of nodes in the call tree is correct Scores for each node are correct Total Points 2 9 (Not base case) Recursively calls minimax on board after trying 31 each move, with depth - 1, to score each valid move 1 (Not base case) Returns the maximum or minimum-scored move 5 and its score, based on board.turn Total 2 15 Points 3 7 10 5.4 alphaBeta (logic) (20%) Criteria Points (Game over) Returns a null move and the appropriate score. 2 constant for board's end state 2 (Non-end state & depth = 0) Returns a null move and the heuristic value for board (Not base case) Calls board.getAllValidMoves() exactly once (Not home (Not base case) Calls board.makeMove (pit) exactly once for each valid move (Not base case) Recursively calls alphaBeta after trying each 1 move, with depth 1, to score each valid move 1 2 2 (Not base case) Returns the first encountered maximum or minimum-scored move and its score, based on board.turn Updates alpha or beta value (as appropriate) and passes values 5 down to recursive calls If a cutoff occurs, does not make any further recursive calls If a cutoff occurs, returns the value that caused the cutoff and a mull move. Total 5.5 alphaBeta (correctness) (15%) Criteria The arrangement of nodes is correct Scores for each node are correct Alpha/beta values passed to each node are correct Total 10 3 2 20 Points 3 7 5 15 5.6 PlayerDP (10%) O Criterial 5 Checks self.resolved for the board's state and returns it without recalculation if found self.resolved Otherwise, calls BasePlayer. heuristic to calculate a heuristic 3 value for this state. (Does not calculate it in this function.) Stores calculated values in self.resolved, indexed by the 2 board's state Total Points 10 5.7 Competency and Gameplay (25) Criteria Chooses moves well at a depth of 1 Chooses moves well at a depth of 3. Chooses moves well at a depth of 5 Beats a random player on a blank board as both P1 and P2 Beats the instructor AI more than 50% of the time on our suite of boards Total 11 Points 2 3 5 5 10 20 9 #a4.py 10 11 12 13 14 from player import * 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 36 37 38 39 40 41 42 43 44 45 46 import sys 47 48 49 50 from board import Board class Game: def _init_(self, trace, player1, player2): self.trace = trace self.player1 = player1 self.player2 = player2 if def runGame(self): board = Board(self.trace) while not board.game_over: # finds the move to make if board.turn == 0: if not isinstance (self.player1, ManualPlayer): print("Player 1 is thinking") move = self.player1. findMove (board.trace) else: if not isinstance(self.player2, ManualPlayer): print("Player 2 is thinking") move = self.player2.findMove (board.trad # makes the move board.makeMove (move) board.print() # determines if the game is over or not if board.winner == -1: print("It is a draw!") elif board.winner == 0: print("Player 1 wins!") elif board.winner == 1: print("Player 2 wins!") name == "___main__": # String representing a sequence of moves from a board. 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 if len(sys.argv) >= 2: trace = sys.argv[1] trace else: # Create player one by calling the # player class corresponding to the # search algorithm the player uses. p1 = RemotePlayer (3) # Same for player 2 p2 = ManualPlayer() # Create the game instance using the # board and players you've made. g = Game (trace, p1, p2) g.runGame() 9un23 u5 6 7 8 19 2812232425257 28 2912345拓初839 48 1 10 11 12 13 14 15 16 17 18 20 26 30 36 37 40 41 #board.py class Board: def __init__(self, trace=None): # # p2_pot # self.board_history = [] @property p2_pits [5] [4] [3] [2] [1¹] [0] self.board = [4,4,4,4,4,4,0,4,4,4,4,4,4,0,0] self._trace = [] self.game_over = False if not (trace is None): for c in trace: p1_pits [0] [1] [2] [3] [4] [5] @property if not self.isValidMove(int(c)): def p1_pits(self): @property return self.board[0:6] print('Warning: invalid move skipped.') continue self.makeMove(int (c)) def p1_pot (self): @property return self.board[6] def p2_pits(self): return self.board [7:13] p1_pot def p2_pot (self): return self.board[13] 114 119 1308 122 128 13 138 148 10 147 147 del turn(1) return selfboard] tu. del turn(self, value); f.bound[14] = valum property (f) if not self.ge_pear if self.pt_pat > salf_gt_got: if self.p pat > salf.gi_got: reture 1 return -1 dallf, pit) if laver return false if gitor pit return false iffure d return salf-beard[git] > @ return self_board[/+pit] > # del makeove(self, move): add move self._trace.append() create new board in stack self.board_history.append(salf board[:]} playerself.mn git-player+ stanes-self.board[pt] lfboardit] while stones # skip opponent's pot, othendisse ford if (pir pat pit +- 2 pit +- 1 loop around radostane to not pit salfardit] + 1 stones switch tures, unless the playw's last stane landed in their pot if git 1-6 and gắt l-tic self. 1 - alf.tur do the crazy capturing thing side-pit //17 across 12 - pit if sido -- player and self-board[pit] -- 1 and self hoard[across_pit] i= #2 player_pat - *player+ salf_beard[player_pet] + 1 + self.bordcross_git] salf.beard[it] - salf_beard[across_pât] - # check whether the game is over, and award the bonus if so pt_totalsum(1 if total d player — 1) or (pit-12 and player -- 8): * på total selfboard6] +-gt_total alfar total KHIELDCON CỪU CHI - Dầu tha thu nhu the HI slf.howro]):18] + 1 kg kg kg ty M self. True undf) undoes the most recent sove, returning the board to the previous state. Does not require the move to be specificially passed to the function. ** elfboard and stary-pop alca: f._trace.pop() clfgaver Falsa IF JF. s={calf.baard[P:]) del getalliches(self, procederwone) preorder-range(6) for 1 in pream 16 salf.beard[1]+k yield for 1 in preader: da prit(): pr if salf_beard[145] > yield ' • str{calf.pt_pâte[6]} + str{colf.pk_pits[]). prit(+ str{colf.på_pot) + " prit + * * + str{calf.p2_pâts[4]} + * * + str{colf.p2_pâts[i]) + • st={salf_pt_gâts[1]} + ** • str{self.p2_pātije) + str(alfat) › str{colf.pd_pätej«]] + " * + str{self.pa_pštx[i]] + * * + str{colf.pa_pštz[2]} + " + str{self.pt_pins[4]] + " dal state(): da pripad]F}: a spaced out printing method so that opt actually that correctly pr * + str{sal4.pt_pâts[i]) + • + ££¥{self_p2_pits[4]} * * * + 9 10 11 import math 12 import random 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #player.py 45 46 47 48 49 50 51 from board import Board class BasePlayer: def __init__(self, max_depth): self.max_depth max_depth # TODO # Assign integer scores to the three terminal states # P2_WIN_SCORE < TIE_SCORE < P1_WIN_SCORE # Access these with "self.TIE_SCORE", etc. P1_WIN_SCORE=Not Implemented P2_WIN_SCORE= Not Implemented TIE_SCORE= Not Implemented # Returns a heuristic for the board position # Good positions for pieces should be positive and # good positions for 1 pieces should be negative # for all boards, P2_WIN_SCORE < heuristic (b) < P1_WIN_SCORE def heuristic (self, board): raise NotImplementedError # You are not expected to implement anything here. def findMove (self, trace): raise NotImplementedError class ManualPlayer (BasePlayer): def __init__(self, max_depth=None): BasePlayer._init__(self, max_depth) def findMove (self, trace): board Board(trace) opts = " for c in range (6): opts += "+(str(c+1) if board.isValidMove (c) else' while True: "1 if(board.turn == 0): print("") Nnnnnn:¯`♥ $5660 ORAN MNAORDO 85 x ♡ % % % % % %252 52 53 54 55 56 57 58 59 60 61 62 63 64 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 89 90 91 92 93 94 board.printSpaced () print (opts) pit = input("Pick a pit (P1 side): ") else: print("") print(" " + opts[::-1]) board.printSpaced () pit = input("Pick a pit (P2 side): ") try: pit = int(pit) - 1 except ValueError: continue if board.isValidMove(pit): return pit class RandomPlayer (BasePlayer): def __init__(self, max_depth=None): BasePlayer._init__(self, max_depth) self.random = random. Random (max_depth) def findMove (self, trace): board = Board (trace) # options = list (board.getAllValidMoves()) return self.random.choice (options) class RemotePlayer (BasePlayer): 88 class PlayerMM(BasePlayer): def _init_(self, max_depth=None): BasePlayer._init__(self, max_depth) self.instructor_url = "http://silo.cs.indiana.edu: 30005" if self.max_depth > 8: print("It refused to go that hard. Sorry.") self.max_depth = 8 def findMove (self, trace): import requests r = requests.get(f'{self.instructor_url}/getmove/{self.max_depth}, {trace}') move = int(r.text) return move TODO # # performs minimax on board with depth. # returns the best move and best score as a tuple def minimax(self, board, depth): 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 def findMove (self, trace): board Board (trace) move, score = self.minimax(board, self.max_depth) return move raise NotImplementedError class PlayerAB (BasePlayer): # TODO # performs minimax with alpha-beta pruning on board with depth. #alpha represents the score of max's current strategy # beta represents the score of min's current strategy # in a cutoff situation, return the score that resulted in the cutoff # returns the best move and best score as a tuple def alphaBeta(self, board, depth, alpha, beta): raise NotImplementedError # # def findMove (self, trace): board = Board (trace) move, score = self.alphaBeta (board, self.max_depth, -math.inf, math.inf) return move class PlayerDP (PlayerAB): *** A version of Player AB that implements dynamic programming to cache values for its heuristic function, improving performance. def __init__(self, max_depth): Player AB._init__(self, max_depth) self.resolved = TODO # *** # if a saved heuristic value exists in self.resolved for board.state, returns that value # otherwise, uses BasePlayer.heuristic to get a heuristic value and saves it under board.state def heuristic (self, board): raise NotImplementedError 135 class PlayerBonus (BasePlayer): 136 137 *** This class is here to give you space to experiment for your ultimate Mancala AI, your one and only Player Bonus. This is only used for the extra credit tournament. 138 139 140 149 150 151 def findMove (self, trace): 141 142 # 143 # 144 145 # This will inherit your findMove from above, but will override the heuristic function with 146 # a new one; you can swap out the type of player by changing X in "class Test Player (X):" 147 class TestPlayer (BasePlayer): 148 152 153 raise NotImplementedError #Example Subclass for Testing #define your new heuristic here def heuristic (self): pass #player_test.py 10 11 from board import Board from player import * 9 12 13 14 15 16 7 8 19 28 21 22 23 24 25 26 27 28 29 38 1 2 3 3435357839 8 1 2 3 4 5 6 7 8 9 邹 1 17 18 20 30 31 32 33 36 40 41 42 43 44 45 46 47 48 49 50 51 def player_check (trace, depth, expected): totalpassedtest = 0 try: print (f"MiniMax Test on {trace}, depth (depth}...") player PlayerMM(depth) answer = player.findMove(trace) if answer == expected: else: try: print("Passed") totalpassedtest += 1 except NotImplementedError: print("Failed") print(f"Expect: (expected}, Return: {answer}") print('minimax not implemented.') print("Alpha/beta pruning Test on {trace}, depth (depth)...") player = PlayerAB (depth) answer = player.findMove (trace) try: if answer == expected: print("Passed") totalpassedtest += 1 else: print("Failed") print(f"Expect: {expected}, Return: {answer}") except NotImplementedError: print('alphaBeta not implemented.') print("Dynamic programming Test on (trace}, depth (depth)...") player PlayerDP (depth) answer = player.findMove(trace) if answer == expected: print("Passed") totalpassedtest += 1 else: print("Failed") 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 print (f"Expect: (expected}, Return: {answer}") except Not Implemented Error: print('PlayerDP not implemented.') return totalpassedtest if name # ##: # This code allows you to construct tests based on minimax trees you have drawn. # Remember that to our algorithms, a win is a win (margin of victory does not matter.) # # # # Example: assume we have the heuristic of board.pl_pot - board.p2_pot. # (This is trivial enough that you should not even consider using it for real.) # Consider the board with trace 123551234220105241 at a depth of 2. max_depth = 2 trace = '123551234220105241' # 10 # BasePlayer.heuristic = lambda self, board: board.p1_pot board.p2_pot # Test for findMove () (minimax and alphaBeta) # == # ##### 0 main : 0 # 10 1 0 3 2 6 01 Ø 0 # P2 has three options: 0, 2, and 3. # If P2 picks 0, then we get 1235512342201052410: # 1 1 7 2 1 0 # 11 PN 1 1 5 10 3 1 2 3 4 5 # If P1 picks 0, 1, or 2, then the heuristic when we cut off will be 4 - 11 = -7. # If P1 picks 3, 4, or 5, then the heuristic when we cut off will be 5 - 11 = -6. # So we assign 1235512342201052410 a score of -6. 1 NP 1 0 2 Ⓒ00 5 10 3 # If P2 picks 2, then we get 1235512342201052412: 0 7 0 8 8 in m 5 10 ##: ### 4 min 3 4 3 4 5 4 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 # If P1 picks 2, then the heuristic when we cut off will be 4 - 10 = -6. # If P1 picks 3, 4, or 5, then the heuristic when we cut off will be 5 - 10 = -5. # So we assign 1235512342201052412 a score of -5. # If P2 picks 3, then we get 1235512342201052413: 1 1 0 1 08 # # 11 # 1 2 N N 1 5 10 3 1 3 4 5 picks 0, 1, or 2, then the heuristic when we cut off will be 4 - 11 = -7. picks 3, 4, or 5, then the heuristic when we cut off will be 5 - 11 = -6. 4 # # If P1 # If P1 # So we assign 1235512342201052413 a score of -6. 2 # # Since this is P2's move, we assign 123551234220105241 a score of -6. # We expect that P2 will pick move 0, under the usual ordering. Move 3 would be equivalently good. expected = 0 player_check (trace, max_depth, expected) # Now it's your turn to try constructing similar tests! # There are many other good ways to come up with testing code, as well. # To write your own TESTS!!! # # TESTS you should make by yourself: # 1. Check for handling draw in endgame. # You should have a case for handling boards which have no winner (each player gets 24 stones). # 2. Check for tie in minimax and alphabeta functions: # You should have a case to break tie if there are two moves that is equally good (should be first considered move) # # 3. Check that your heuristic always falls strictly within your P2_WIN, P1_WIN range. 1 Summary • Develop a competitive AI for the game Mancala • Demonstrate your understanding of the MiniMax search algorithm, alpha- beta pruning, and dynamic programming We will be using Python 3 so be sure you aren't using older versions. Code that will compile in Python 2.7 may not compile in Python 3. See our installation guide for help removing old versions and installing Python 3. To run your completed programs against our instructor AI, you may want to install the requests module. You will do utilizing pip and using your terminal to execute the command python -m pip install requests. If your code still does not run due to missing modules, please come by office hours. 2 Background Mancala is a two-player, turn-based strategy game where the objective is to collect the most pieces by the end of the game. To play a game, you need a Mancala board, which is a board made up of two rows of six pockets, also known as pits, and two "stores" located at the ends of these pits. 2.1 Rules 1. Each turn consists of a player picking up all the pieces in a pit and, moving counter-clockwise, deposit a stone in each pocket until the stones run out. 1 When moving your stones, if you pass your store then you deposit one stone inside it as well, but you skip over your opponent's store. 2. If the last piece you place goes into your store, you take another turn. 3. If the last piece you place is in an empty space on your side, and your opponent has stones in the pit exactly opposite of this empty space¹, then you collect all the stones in your opponent's opposite pit as well as your last placed stone. 4. The game is over when all the stones on one side of the board are gone, and when this happens the other player takes all their stones on their side and puts them in their store. 5. To score the game, each player counts up the total number of stones in their store. The player with the most stones wins! For those of you who have never played Mancala before this might seem like an overload of information. If you are confused about the structure/rules of the game, please visit the following links for more detailed explanations with visuals: https://www.scholastic.com/content/dam/teachers/blogs/ alycia-zimmerman/migrated-files/mancala_rules.pdf and https: //endlessgames.com/wp-content/uploads/Mancala_Instructions.pdf. When designing a heuristic, it is vitally important to understand how the game is played. Because of this, we highly suggest that you play a couple of games to really understand the underlying rules and strategies. The following link will take you to a website where you can play some practice games against a computer which is a great way for beginners to learn the game: https://mancala.playdrift.com/. We also hope to share a brief video of ourselves playing the game to illustrate some of the rules. 3 Programming Component In this assignment's programming component, you will implement an artificial intelligence agent that can competitively play Mancala. To achieve this, you will implement three key algorithms: MiniMax, alpha-beta pruning, and dynamic programming. Additionally, you will develop your own heuristic function to help evaluate maximum depth nodes in your game tree search. Note that this rule differs slightly from the rules linked, which do not require your opponent have stones in their pit to make an "empty capture". However, this is consistent with the interactive website linked, and with how the game is most often played. 2 3.1 Game Data Structures. You will utilize the following classes. You should read and understand this section before embarking on your assignment. 1. Board Class The Board class is the data structure that holds the Mancala, board and the game operations. The data structures that hold the current board state and the historical states are Python lists, but you will primarily be interfacing with them through the pl-pits, p2-pits, pl-pot, p2-pot, and turn properties. pl-pits and p2-pits are both lists which contain integers indexed from 0-5 representing how many stones a player has in a given pit. The indices for these lists increase counter-clockwise (an illustration of this can be seen at the top of the init_() function.) p1-pot and p2.pot. contain the integer value of how many stones each player has in their store (and has therefore scored) so far. turn is an integer, which is 0. when it is player 1's turn and 1 when it is player 2's turn. Note that the Board class also contains a list called trace, which contains a list of moves made so far. Traces are usually used for debugging and replaying what moves led to a board state. You can access a convenient string representation of the trace through the trace property. You will use the following methods, properties, and attributes to interact with the board: (a) __init__([trace]) - This constructor function can be utilized in two ways: i. no args If no arguments are passed, the constructor function. generates a new board with 4 stones in each pit. ii. trace - If the trace argument is set to a valid string of moves, then the constructor function generates a new Board object. based on that trace. (b) makeMove (pit) - This function "picks up" all of the stones in the given pit, and places the stones according to Mancala rules. It also records the move in trace, and saves a copy of the previous board. in board history for later recovery. The function automatically picks up stones from the side of whoever's turn it is. NOTE: This function does not perform any error checking by default. It is the responsibility of the user to ensure that proper non-empty pit is 3 passed. See getAllValidMoves () for an example of proper usage. (c) undoMove () This will undo the last move made on a board, returning the board to the most recent state in the history, and updating the history, trace, and game over variables appropriately. (d) getAllValidMoves ( [preorder]). This generates a series of all the valid moves of the Board object. You may optionally pass a prior ordering that will influence the order in which moves are considered and returned. (e) print () This prints a graphical representation of the current board state to your terminal. (f) board - board is a 15-item integer array containing (in order) the first player's six pits, the first player's store, the second player's six pits, the second player's store, and the next player to play. All of this data is more easily accessed through different properties. (g) pl pot, pl pits. p2 pot, p2.pits - These properties allow you to access information about the current state of the board. p1-pot and p2 pot are integers; p1.pits and p2 pits are six-item integer arrays, arranged counterclockwise. (For instance, p1-pits [0] is opposite to p2-pits [5].) These properties are often used in your heuristic functions. (h) turn- - This property is 0 when it is currently player 1 (max)'s turn and 1 when it is currently player 2 (min)'s turn. This property is i used to determine whether to minimize or maximize in your minimax functions. (i) game over This attribute is True when the game is over and False otherwise. (j) winner - This property (not function) contains a value representing the terminal state of the game. If the game is over, it will contain -1 for a draw, 0 for a player one win, or 1 for a player two win. If the game is not over, it will evaluate to None. (k) trace This property (not function) contains a convenient string representing the sequence of moves that led to the current state of the board. This can be used to easily recreate another similar board, and is used in our debugging and grading tools. (1) state This property (not function) contains an integer representing the current state of the board. Note that two different traces might lead to the same state. state is used in the dynamic 4 programming portion of this assignment. 2. Player Class In this class, you will implement your search algorithm. This class is utilized by the Game class to simulate a game using your AI. The base player class must define constants P2_WIN_SCORE, TIE SCORE. and P1_WIN SCORE to represent scores for the different end states of the game. You will work with the following common to all Players: (a) findMove (trace) - This will return the optimal move for trace upon executing a game tree search up to the Player's max_depth. It will call an appropriate function according to the particular algorithm. the player uses. Some Player subclasses do very unusual things here! (b) heuristic (board) - This function returns a value representing the "goodness" of the board for each player. Good positions for Player 1 will return high values. Good positions for Player 2 will return low (or highly negative) values. As explained later, it is your responsibility to implement this function. We provide the following subclasses of BasePlayer: (a) RandomPlayer this subclass randomly selects one of the valid moves to execute each turn. (b) ManualPlayer - this subclass lets you play directly against your AI. Very fun! (c) RemotePlayer this subclass lets you play against the same instructor AI you are tested against on the Gameplay criterion. (You are tested with the instructor AI at a depth of five.) This subclass depends on the requests library. You will implement your search algorithms in the subclasses of BasePlayer following the instructions in the next section. Additionally, you can create subclasses of your various Players with different heuristic functions in order to test your heuristics against each other locally. We have provided an example of how to accomplish this. 3. Game Class This class is found within the a4.py file. This contains the interface for testing your search algorithms. You will work with the following functions: 5 (a) runGame () This will simulate a game using the AI agents that you create using your Board and Player classes. In particular, it will test if your search strategy was implemented properly and can be used to test heuristics against each other. You may find it beneficial to change the implementation and parameters of one or many of the above functions/classes in order to increase the efficiency of your code. Edits are not only accepted, but they are expected. (except where explicitly banned). That being said, please note that your changes must be able to interface with the functions in the a4.py file (Game class) and test cases. Failure to achieve this will preclude you from receiving any bonus, and will likely result in significant loss of points. You must define each of the homework functions to the specification outlined, except in your bonus player and board classes. 3.2 Objectives Your goal is to complete the following tasks. It is in your best interest to complete them in the order that they are presented. 3.2.1 BasePlayer.heuristic() You must complete the heuristic() function in the BasePlayer class to return a game state value that reflects the "goodness of the game. Remember, the better the game state for Player 1, the higher the score; the better the game state for Player 2, the lower the score (can and probably should be negative). Take into account whether it is valuable to control more. or fewer stones, how late into the game it is, and anything else you find. relevant. Additionally, you must define P2_WIN_SCORE, TIE_SCORE, and P1_WIN_SCORE so that all heuristic values fall between the two players' win scores. As this function will be called at almost every leaf node in your MiniMax search, you will want your function to be as efficient as possible. Note: While you may test your heuristic in different subclasses, the final heuristic that you'd like to be evaluated on must be in the main BasePlayer class. 3.2.2 MiniMax Search Your goal in this section is to develop a generic MiniMax search algorithm. without any optimizations (i.e., alpha-beta). For a reference to this algorithm, 6 you may revisit the lecture slides or see the following Wiki page: https://en.wikipedia.org/wiki/Minimax. In your PlayerMM class you will find the minimax () function where you must. implement the search algorithm. When creating your search algorithm, please consider the following: 1. The function should ultimately return the pit that represents the best move for the player. 2. Your algorithm should correctly identify end positions and assign them the correct value constant without doing any unnecessary processing. Please note that this can be trickier than it looks, so be sure that you think. carefully about your value assignments and use the constants you defined for all Player classes. 3. Your algorithm should correctly stop at maximum depth and return the appropriate heuristic value. 4. You should keep track of whose turn it is and where you are relative to the maximum depth. 5. You should always explore all possible children (except when you have reached maximum depth). If you have successfully completed this section, and Player.heuristic (), you should be able to run runGame in the Game class and achieve meaningful results (i.e., it will play a Mancala game to completion). Do not proceed until this works properly. 3.2.3 Alpha-Beta Pruning Your goal in this section is to implement alpha-beta pruning in the MiniMax search algorithm that you developed in the previous section. For a reference to this pruning technique, you may revisit the lecture slides or see the following Wiki page: https://en.wikipedia.org/wiki/Alpha%E2%80%93beta_pruning. For this, you will implement the alphaBeta () function of the PlayerAB class, and you should continue to ensure that it returns the best column to move in for the player. When implementing alpha-beta pruning, please consider the following: 1. You should update both alpha and beta whenever appropriate. 2. You should identify the correct pruning conditions and that you place. break statements in the correct locations. 7 When implemented correctly, your new MiniMax algorithm should run significantly faster than the one you initially developed. That being said, it should emit exactly the same answer (for the same depth). 3.2.4 Dynamic Programming Your goal in this section is to implement dynamic programming in the MiniMax search algorithm that you developed in previous sections. For a reference to dynamic programming, you may revisit the lecture slides. For this, you will implement the heuristic() function of the PlayerDP class. Keep in mind that this is overriding the heuristic() function of BasePlayer. To access that function, you may call BasePlayer.heuristic (self, board) or super().heuristic (board). Your implementation must not differ from the heuristic value returned by BasePlayer When implementing dynamic programming, please consider the following: 1. Remember that you cannot store objects as keys in hash maps because they are mutable. Instead you will need to use a hashable representation of your Board objects. Fortunately, this is already provided to you in Board.state. 2. You must use self.resolved to store the lookup table for your dynamic programming. We will be using this to test and grade this section of the assignment. As with alpha-beta pruning, your new Alpha-Beta algorithm with dynamic programming will likely run significantly faster (depending on how expensive your heuristic is) than the one you initially developed. That being said, it should emit exactly the same answer (for the same depth). 4 Tests Very simple tests have been given for you in player_test.py for the functions you implemented. Running the main of these files will run the tests. Be sure to use these to make sure your implementations are working generally as requested. These test cases are NOT all encompassing. Passing these does not mean your implementation is completely correct. In order to save submissions, it is advised to write additional unit tests for more complex puzzles as well as to cover cases that these tests do not. In player_test.py we provide some ideas as to what else you should test on your own. This isn't required, but it is highly recommended, as learning to debug on your own is an important skill. Once all of your functions have been completed, you can also test with the main function in a4.py. Additionally, you can and should utilize traces as an extra debugging tool. 8 5 Grading Problems are weighted according to the percentage assigned in the problem title. For each problem, points will be given based on the criteria met in the corresponding table on the next page and whether your solutions pass the test. cases on the online grader. Finally, remember that this is an individual assignment. 5.1 BasePlayer (5%) Criteria P2 WIN SCORE, TIE SCORE, P1_WIN SCORE all real-valued (and not infinity) P2_WIN SCORE < TIE_SCORE < P1_WIN_SCORE Heuristic is real-valued on all boards Heuristic always falls between P2_WIN SCORE and P1 WIN_SCORE Total 5.2 minimax (logic) (15%) Criteria (Game over) Returns a null move and the appropriate score constant for board's terminal state (Not base case) Calls board.getAllValidMoves() exactly once, optionally specifying a an order on the pits Calls and base case) (Not (Not board.makeMove (pit) board. undoMove ( e(pit) exactly once for each valid move 2 (Non-end state & depth 0) Returns a null move and the heuristic value for board Points 1 5.3 minimax (correctness) (10%) 1 1 2 5 Criteria The arrangement of nodes in the call tree is correct Scores for each node are correct Total Points 2 9 (Not base case) Recursively calls minimax on board after trying 31 each move, with depth - 1, to score each valid move 1 (Not base case) Returns the maximum or minimum-scored move 5 and its score, based on board.turn Total 2 15 Points 3 7 10 5.4 alphaBeta (logic) (20%) Criteria Points (Game over) Returns a null move and the appropriate score. 2 constant for board's end state 2 (Non-end state & depth = 0) Returns a null move and the heuristic value for board (Not base case) Calls board.getAllValidMoves() exactly once (Not home (Not base case) Calls board.makeMove (pit) exactly once for each valid move (Not base case) Recursively calls alphaBeta after trying each 1 move, with depth 1, to score each valid move 1 2 2 (Not base case) Returns the first encountered maximum or minimum-scored move and its score, based on board.turn Updates alpha or beta value (as appropriate) and passes values 5 down to recursive calls If a cutoff occurs, does not make any further recursive calls If a cutoff occurs, returns the value that caused the cutoff and a mull move. Total 5.5 alphaBeta (correctness) (15%) Criteria The arrangement of nodes is correct Scores for each node are correct Alpha/beta values passed to each node are correct Total 10 3 2 20 Points 3 7 5 15 5.6 PlayerDP (10%) O Criterial 5 Checks self.resolved for the board's state and returns it without recalculation if found self.resolved Otherwise, calls BasePlayer. heuristic to calculate a heuristic 3 value for this state. (Does not calculate it in this function.) Stores calculated values in self.resolved, indexed by the 2 board's state Total Points 10 5.7 Competency and Gameplay (25) Criteria Chooses moves well at a depth of 1 Chooses moves well at a depth of 3. Chooses moves well at a depth of 5 Beats a random player on a blank board as both P1 and P2 Beats the instructor AI more than 50% of the time on our suite of boards Total 11 Points 2 3 5 5 10 20 9 #a4.py 10 11 12 13 14 from player import * 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 36 37 38 39 40 41 42 43 44 45 46 import sys 47 48 49 50 from board import Board class Game: def _init_(self, trace, player1, player2): self.trace = trace self.player1 = player1 self.player2 = player2 if def runGame(self): board = Board(self.trace) while not board.game_over: # finds the move to make if board.turn == 0: if not isinstance (self.player1, ManualPlayer): print("Player 1 is thinking") move = self.player1. findMove (board.trace) else: if not isinstance(self.player2, ManualPlayer): print("Player 2 is thinking") move = self.player2.findMove (board.trad # makes the move board.makeMove (move) board.print() # determines if the game is over or not if board.winner == -1: print("It is a draw!") elif board.winner == 0: print("Player 1 wins!") elif board.winner == 1: print("Player 2 wins!") name == "___main__": # String representing a sequence of moves from a board. 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 if len(sys.argv) >= 2: trace = sys.argv[1] trace else: # Create player one by calling the # player class corresponding to the # search algorithm the player uses. p1 = RemotePlayer (3) # Same for player 2 p2 = ManualPlayer() # Create the game instance using the # board and players you've made. g = Game (trace, p1, p2) g.runGame() 9un23 u5 6 7 8 19 2812232425257 28 2912345拓初839 48 1 10 11 12 13 14 15 16 17 18 20 26 30 36 37 40 41 #board.py class Board: def __init__(self, trace=None): # # p2_pot # self.board_history = [] @property p2_pits [5] [4] [3] [2] [1¹] [0] self.board = [4,4,4,4,4,4,0,4,4,4,4,4,4,0,0] self._trace = [] self.game_over = False if not (trace is None): for c in trace: p1_pits [0] [1] [2] [3] [4] [5] @property if not self.isValidMove(int(c)): def p1_pits(self): @property return self.board[0:6] print('Warning: invalid move skipped.') continue self.makeMove(int (c)) def p1_pot (self): @property return self.board[6] def p2_pits(self): return self.board [7:13] p1_pot def p2_pot (self): return self.board[13] 114 119 1308 122 128 13 138 148 10 147 147 del turn(1) return selfboard] tu. del turn(self, value); f.bound[14] = valum property (f) if not self.ge_pear if self.pt_pat > salf_gt_got: if self.p pat > salf.gi_got: reture 1 return -1 dallf, pit) if laver return false if gitor pit return false iffure d return salf-beard[git] > @ return self_board[/+pit] > # del makeove(self, move): add move self._trace.append() create new board in stack self.board_history.append(salf board[:]} playerself.mn git-player+ stanes-self.board[pt] lfboardit] while stones # skip opponent's pot, othendisse ford if (pir pat pit +- 2 pit +- 1 loop around radostane to not pit salfardit] + 1 stones switch tures, unless the playw's last stane landed in their pot if git 1-6 and gắt l-tic self. 1 - alf.tur do the crazy capturing thing side-pit //17 across 12 - pit if sido -- player and self-board[pit] -- 1 and self hoard[across_pit] i= #2 player_pat - *player+ salf_beard[player_pet] + 1 + self.bordcross_git] salf.beard[it] - salf_beard[across_pât] - # check whether the game is over, and award the bonus if so pt_totalsum(1 if total d player — 1) or (pit-12 and player -- 8): * på total selfboard6] +-gt_total alfar total KHIELDCON CỪU CHI - Dầu tha thu nhu the HI slf.howro]):18] + 1 kg kg kg ty M self. True undf) undoes the most recent sove, returning the board to the previous state. Does not require the move to be specificially passed to the function. ** elfboard and stary-pop alca: f._trace.pop() clfgaver Falsa IF JF. s={calf.baard[P:]) del getalliches(self, procederwone) preorder-range(6) for 1 in pream 16 salf.beard[1]+k yield for 1 in preader: da prit(): pr if salf_beard[145] > yield ' • str{calf.pt_pâte[6]} + str{colf.pk_pits[]). prit(+ str{colf.på_pot) + " prit + * * + str{calf.p2_pâts[4]} + * * + str{colf.p2_pâts[i]) + • st={salf_pt_gâts[1]} + ** • str{self.p2_pātije) + str(alfat) › str{colf.pd_pätej«]] + " * + str{self.pa_pštx[i]] + * * + str{colf.pa_pštz[2]} + " + str{self.pt_pins[4]] + " dal state(): da pripad]F}: a spaced out printing method so that opt actually that correctly pr * + str{sal4.pt_pâts[i]) + • + ££¥{self_p2_pits[4]} * * * + 9 10 11 import math 12 import random 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #player.py 45 46 47 48 49 50 51 from board import Board class BasePlayer: def __init__(self, max_depth): self.max_depth max_depth # TODO # Assign integer scores to the three terminal states # P2_WIN_SCORE < TIE_SCORE < P1_WIN_SCORE # Access these with "self.TIE_SCORE", etc. P1_WIN_SCORE=Not Implemented P2_WIN_SCORE= Not Implemented TIE_SCORE= Not Implemented # Returns a heuristic for the board position # Good positions for pieces should be positive and # good positions for 1 pieces should be negative # for all boards, P2_WIN_SCORE < heuristic (b) < P1_WIN_SCORE def heuristic (self, board): raise NotImplementedError # You are not expected to implement anything here. def findMove (self, trace): raise NotImplementedError class ManualPlayer (BasePlayer): def __init__(self, max_depth=None): BasePlayer._init__(self, max_depth) def findMove (self, trace): board Board(trace) opts = " for c in range (6): opts += "+(str(c+1) if board.isValidMove (c) else' while True: "1 if(board.turn == 0): print("") Nnnnnn:¯`♥ $5660 ORAN MNAORDO 85 x ♡ % % % % % %252 52 53 54 55 56 57 58 59 60 61 62 63 64 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 89 90 91 92 93 94 board.printSpaced () print (opts) pit = input("Pick a pit (P1 side): ") else: print("") print(" " + opts[::-1]) board.printSpaced () pit = input("Pick a pit (P2 side): ") try: pit = int(pit) - 1 except ValueError: continue if board.isValidMove(pit): return pit class RandomPlayer (BasePlayer): def __init__(self, max_depth=None): BasePlayer._init__(self, max_depth) self.random = random. Random (max_depth) def findMove (self, trace): board = Board (trace) # options = list (board.getAllValidMoves()) return self.random.choice (options) class RemotePlayer (BasePlayer): 88 class PlayerMM(BasePlayer): def _init_(self, max_depth=None): BasePlayer._init__(self, max_depth) self.instructor_url = "http://silo.cs.indiana.edu: 30005" if self.max_depth > 8: print("It refused to go that hard. Sorry.") self.max_depth = 8 def findMove (self, trace): import requests r = requests.get(f'{self.instructor_url}/getmove/{self.max_depth}, {trace}') move = int(r.text) return move TODO # # performs minimax on board with depth. # returns the best move and best score as a tuple def minimax(self, board, depth): 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 def findMove (self, trace): board Board (trace) move, score = self.minimax(board, self.max_depth) return move raise NotImplementedError class PlayerAB (BasePlayer): # TODO # performs minimax with alpha-beta pruning on board with depth. #alpha represents the score of max's current strategy # beta represents the score of min's current strategy # in a cutoff situation, return the score that resulted in the cutoff # returns the best move and best score as a tuple def alphaBeta(self, board, depth, alpha, beta): raise NotImplementedError # # def findMove (self, trace): board = Board (trace) move, score = self.alphaBeta (board, self.max_depth, -math.inf, math.inf) return move class PlayerDP (PlayerAB): *** A version of Player AB that implements dynamic programming to cache values for its heuristic function, improving performance. def __init__(self, max_depth): Player AB._init__(self, max_depth) self.resolved = TODO # *** # if a saved heuristic value exists in self.resolved for board.state, returns that value # otherwise, uses BasePlayer.heuristic to get a heuristic value and saves it under board.state def heuristic (self, board): raise NotImplementedError 135 class PlayerBonus (BasePlayer): 136 137 *** This class is here to give you space to experiment for your ultimate Mancala AI, your one and only Player Bonus. This is only used for the extra credit tournament. 138 139 140 149 150 151 def findMove (self, trace): 141 142 # 143 # 144 145 # This will inherit your findMove from above, but will override the heuristic function with 146 # a new one; you can swap out the type of player by changing X in "class Test Player (X):" 147 class TestPlayer (BasePlayer): 148 152 153 raise NotImplementedError #Example Subclass for Testing #define your new heuristic here def heuristic (self): pass #player_test.py 10 11 from board import Board from player import * 9 12 13 14 15 16 7 8 19 28 21 22 23 24 25 26 27 28 29 38 1 2 3 3435357839 8 1 2 3 4 5 6 7 8 9 邹 1 17 18 20 30 31 32 33 36 40 41 42 43 44 45 46 47 48 49 50 51 def player_check (trace, depth, expected): totalpassedtest = 0 try: print (f"MiniMax Test on {trace}, depth (depth}...") player PlayerMM(depth) answer = player.findMove(trace) if answer == expected: else: try: print("Passed") totalpassedtest += 1 except NotImplementedError: print("Failed") print(f"Expect: (expected}, Return: {answer}") print('minimax not implemented.') print("Alpha/beta pruning Test on {trace}, depth (depth)...") player = PlayerAB (depth) answer = player.findMove (trace) try: if answer == expected: print("Passed") totalpassedtest += 1 else: print("Failed") print(f"Expect: {expected}, Return: {answer}") except NotImplementedError: print('alphaBeta not implemented.') print("Dynamic programming Test on (trace}, depth (depth)...") player PlayerDP (depth) answer = player.findMove(trace) if answer == expected: print("Passed") totalpassedtest += 1 else: print("Failed") 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 print (f"Expect: (expected}, Return: {answer}") except Not Implemented Error: print('PlayerDP not implemented.') return totalpassedtest if name # ##: # This code allows you to construct tests based on minimax trees you have drawn. # Remember that to our algorithms, a win is a win (margin of victory does not matter.) # # # # Example: assume we have the heuristic of board.pl_pot - board.p2_pot. # (This is trivial enough that you should not even consider using it for real.) # Consider the board with trace 123551234220105241 at a depth of 2. max_depth = 2 trace = '123551234220105241' # 10 # BasePlayer.heuristic = lambda self, board: board.p1_pot board.p2_pot # Test for findMove () (minimax and alphaBeta) # == # ##### 0 main : 0 # 10 1 0 3 2 6 01 Ø 0 # P2 has three options: 0, 2, and 3. # If P2 picks 0, then we get 1235512342201052410: # 1 1 7 2 1 0 # 11 PN 1 1 5 10 3 1 2 3 4 5 # If P1 picks 0, 1, or 2, then the heuristic when we cut off will be 4 - 11 = -7. # If P1 picks 3, 4, or 5, then the heuristic when we cut off will be 5 - 11 = -6. # So we assign 1235512342201052410 a score of -6. 1 NP 1 0 2 Ⓒ00 5 10 3 # If P2 picks 2, then we get 1235512342201052412: 0 7 0 8 8 in m 5 10 ##: ### 4 min 3 4 3 4 5 4 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 # If P1 picks 2, then the heuristic when we cut off will be 4 - 10 = -6. # If P1 picks 3, 4, or 5, then the heuristic when we cut off will be 5 - 10 = -5. # So we assign 1235512342201052412 a score of -5. # If P2 picks 3, then we get 1235512342201052413: 1 1 0 1 08 # # 11 # 1 2 N N 1 5 10 3 1 3 4 5 picks 0, 1, or 2, then the heuristic when we cut off will be 4 - 11 = -7. picks 3, 4, or 5, then the heuristic when we cut off will be 5 - 11 = -6. 4 # # If P1 # If P1 # So we assign 1235512342201052413 a score of -6. 2 # # Since this is P2's move, we assign 123551234220105241 a score of -6. # We expect that P2 will pick move 0, under the usual ordering. Move 3 would be equivalently good. expected = 0 player_check (trace, max_depth, expected) # Now it's your turn to try constructing similar tests! # There are many other good ways to come up with testing code, as well. # To write your own TESTS!!! # # TESTS you should make by yourself: # 1. Check for handling draw in endgame. # You should have a case for handling boards which have no winner (each player gets 24 stones). # 2. Check for tie in minimax and alphabeta functions: # You should have a case to break tie if there are two moves that is equally good (should be first considered move) # # 3. Check that your heuristic always falls strictly within your P2_WIN, P1_WIN range.
Expert Answer:
Answer rating: 100% (QA)
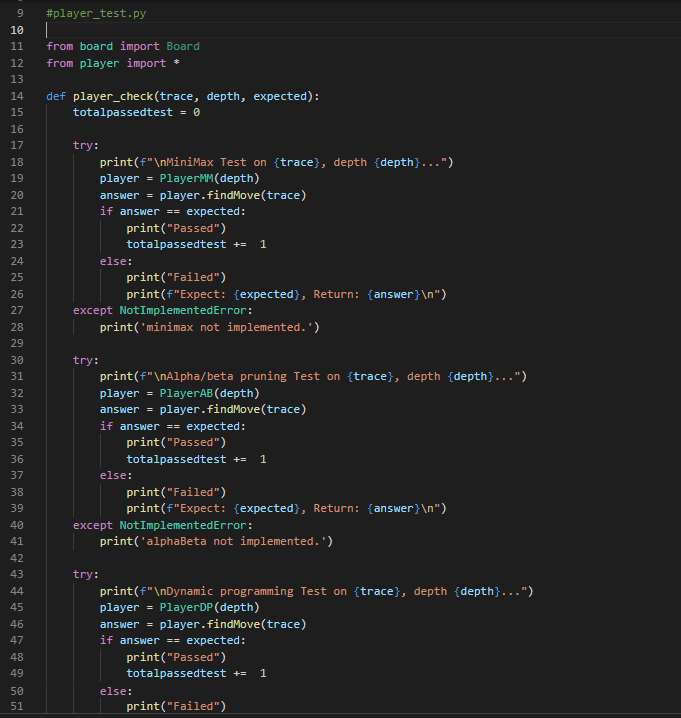
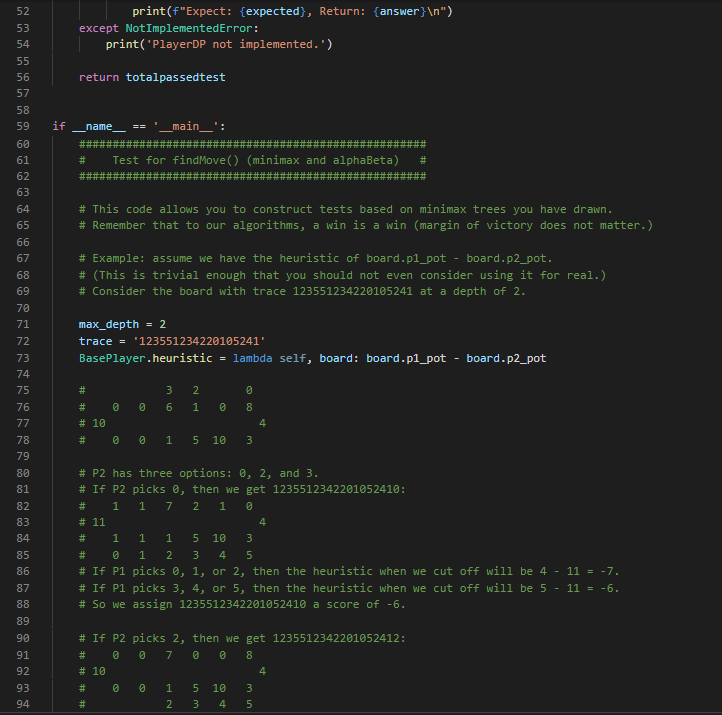
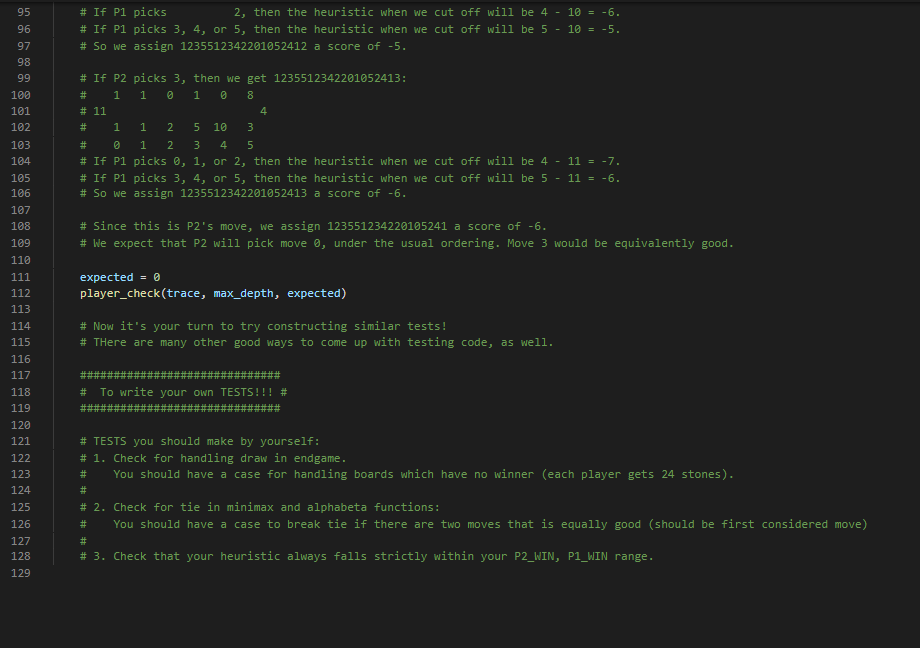
To develop a competitive AI for the game Mancala you can follow these steps 1 Understand the rules of Mancala Familiarize yourself with the rules and ... View the full answer

Related Book For 

Data Modeling and Database Design
ISBN: 978-1285085258
2nd edition
Authors: Narayan S. Umanath, Richard W. Scammel
Posted Date:
Students also viewed these programming questions
-
A load 52.2 kN is applied onto the frame shown below. Use the portal method to determine approximately the magnitude of the bending moment at Joint A. Please provide your answer in kN.m and to two...
-
Demonstrate your understanding of the terms by using them correctly. Creativity is encouraged by not required; a realistic scenario would be best. Terms: Harassment, Severe/pervasive, Vicarious...
-
Demonstrate your understanding of data, metadata, and information using an example.
-
Transfer pricing is a significant area of concern for taxing authorities and multinational entities (MNE). Examine at least two (2) potential transfer pricing issues that create concern for both...
-
In Chapter 7, you developed a use case diagram, a domain model class diagram, and detailed documentation for three use cases. In your detailed documentation, you generated a fully developed...
-
How does an increase in the value of the pound sterling affect Canadian businesses?
-
Which item(s) appears as a reconciling item(s) to the bank balance in a bank reconciliation? a. Outstanding checks b. Deposits in transit C. Both a and b d. None of the above
-
The manager of a minor league baseball team wants to estimate the average fastball speed of two pitchers. He clocks 50 fastballs, in miles per hour, for each pitcher. A portion of the data is shown...
-
Use the following Adjusted Trial Balance to prepare a Merchandising MULTI-STEP Income Statement for the Year Ended Dec 31, 2022. Asset, Liab, Rev, I/S or Account Description Debit Credit Exp, Other...
-
A cross-flow molecular filtration device equipped with a mesoporous membrane is used to separate the enzyme lysozyme from a fermentation broth, as shown in the figure (right column). Water at...
-
Write a program that calculates the area for a number of different shapes. Create a method to ask the user if they want to calculate the area for a circle, a rectangle, or a triangle. If the user...
-
If you can earn 7% on money, is it better to pay $1990 cash for an item or to pay $2090 in a year? Give the cash equivalent of the savings resulting from adopting the better plan.
-
The partnership agreement of Romeo and Rocky has the following provisions; the partners are to earn 1 0 percent on the average capital. Romeo and Rocky are to earn salaries of $ 2 5 , 0 0 0 and $ 1 0...
-
Yesta Limited manufactures electronic automobiles and sells to its Asian customers. The company provides warranties associated with the automobile sold. It is the company's policy to provide two...
-
Ivanhoe Industries Limited purchased a strip mine for cash on April 1, 2020 at a cost of $5,787,000. Ivanhoe expects to operate the mine for 10 years, at which it is legally required to restore the...
-
Explain how marketing to different countries or cultures may affect your advertising message or campaign? Explain the principle and give examples of actual advertising campaigns localized for...
-
Two U.S. government bonds will deliver one single cash flow in one year. One will pay 103 dollars per 100 dollars of principal and the other will pay 104 dollars per 100 dollars of principal. Which...
-
Doorharmony Company makes doorbells. It has a weighted- average cost of capital of 5% and total assets of $ 5,900,000. Doorharmony has current liabilities of $ 750,000. Its operating income for the...
-
Given the schema SCHEDULE (Prof, Office, Major, {Book}, Course, Quarter) along with: F: fd1: Prof {Office, Major} and D: mvd: Prof --->> Book a. Identify the primary key of SCHEDULE such that...
-
What is a unique identifier of an entity type? Is it possible for there to be more than one unique identifier for an entity type?
-
This question is based on the four relations shown below. Show the results along with the relational algebra expressions for the following four retrieval requests? a. Display the products and their...
-
What is the average rate of return for the values that follow? 0.90, 1.1, 1.2
-
What is the average rate of return for the values that follow? 0.80, 2.0, 5.0
-
State whether the data are symmetrical, skewed to the left, or skewed to the right. 16; 17; 19; 22; 22; 22; 22; 22; 23

Study smarter with the SolutionInn App