

Probem 1. (10 points) Consider the hyperplane wx+b=0 of known parameters w and b. a) (5...
Fantastic news! We've Found the answer you've been seeking!
Question:



Transcribed Image Text:
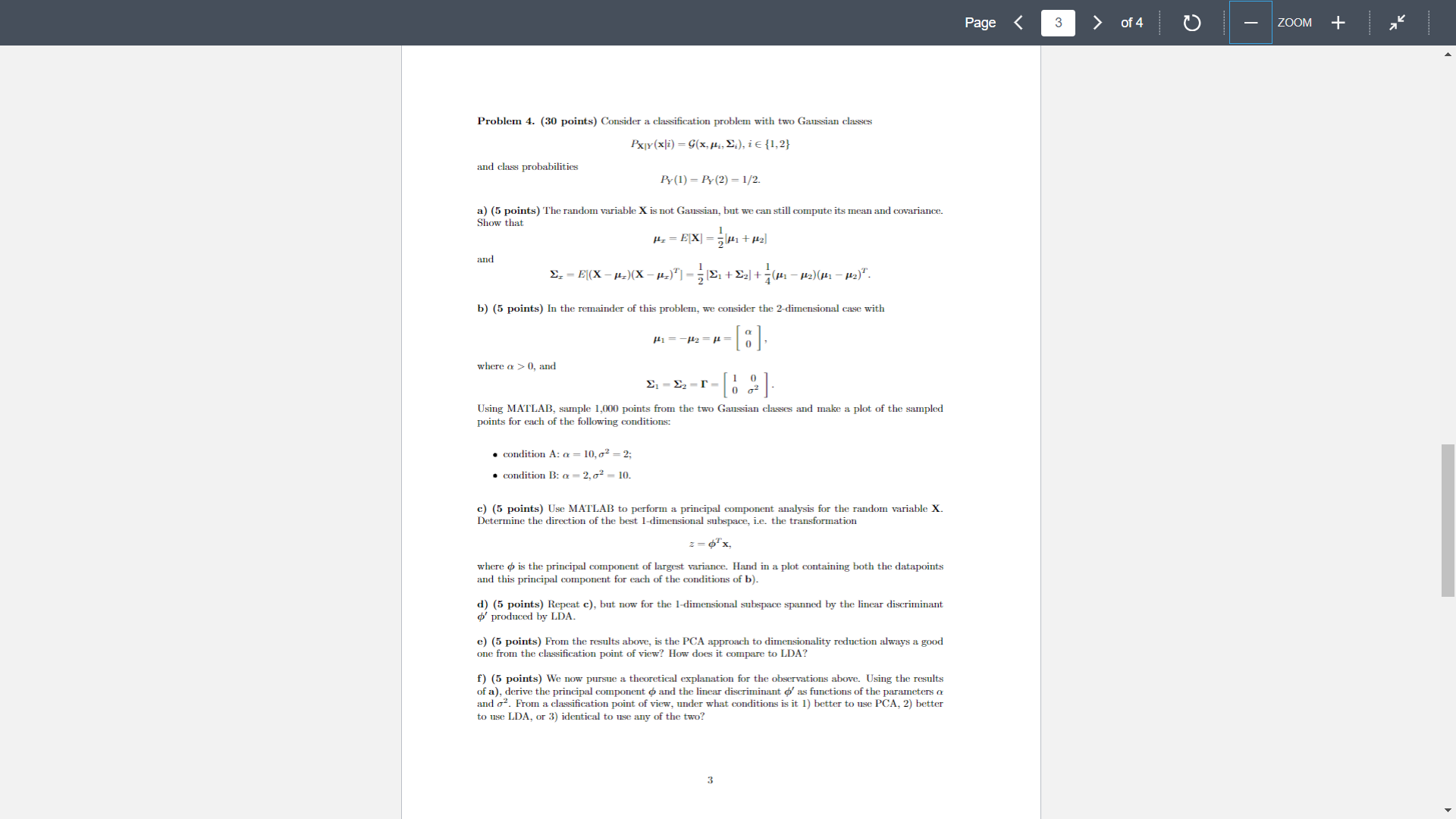
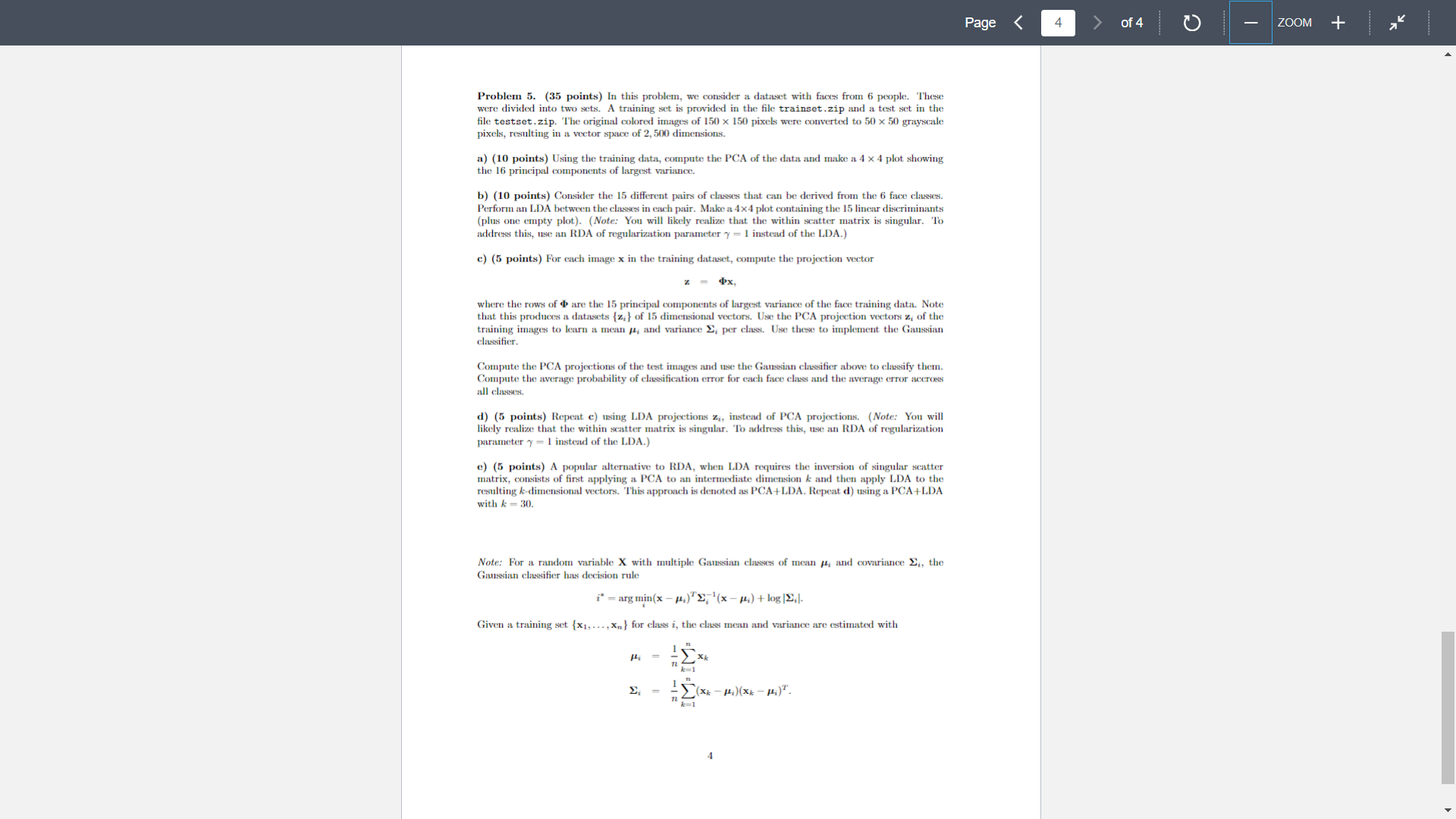
Probem 1. (10 points) Consider the hyperplane wx+b=0 of known parameters w and b. a) (5 points) Use Lagrangian optimization to find the point xo in the plane closest to the origin, as a function of w and b. b) (5 points) Use the result of a) to derive a geometric interpretation for the parameters w and b, when ||w|| = 1. Problem 2. (10 points) The entropy of probability density function (pdf) p(z) is defined as - p(z) log p(x)dr. r) h(x) = a) (5 points) Use Lagrangian optimization to find the pdf of maximal entropy among those whose expected value is and variance is o. b) (5 points) Find the values of the Lagrange multipliers associated with the optimal solution. 1 Problem 3. (15 points) Extensive experimental evidence in the area of image compression has shown that the Discrete Cosine Transform (DCT) of image patches is a very good approximation to their PCA. It is also well known that all but one of the DCT coefficients (features) have zero mean, and only one has non-zero mean. The latter is the so-called DC coefficient because it results from projecting the image patch into the vector 1 = (1,1,...,1), where d is the vector dimension and, therefore, is proportional to the average (DC) value of the patch. In this problem, we are going to explore the connection between the DCT and PCA to explain this fact. For this, we are going to assume the following. An image patch is a collection of random variables X = {X, X64} which are identically distributed Px. (x) = f(x), Vi {1,...,64}, where f(x) is a common probability density function. The pixels in the image patch are correlated, according to the correlation coefficient E[XX] E[X]VE[X] This obviously implies that we do not have an iid sample. Pij a) (5 points) Consider the PCA of X. Show that it is not affected by a change of variables of the type Z = X - 2, where = E[X]. b) (5 points) Given a), we can assume that X has zero mean. We will do so for the remainder of the problem. Show that in the extreme of highly correlated pixel values, i.e. when Pij 1, Vij the vector 1 is the largest principal component. Since neighboring image pixels do tend to be highly correlated, this helps explain why the DC coefficient is always present. c) (5 points) Let be the matrix whose columns ; are the principal components and consider the set of coefficients (features) Z resulting from the projection of an arbitrary image patch X into these components, i.e. z = $x. Consider the DCT coefficients z; = ofx, noting that 2 = E[zi] = 0, Vi > 1, i.e. that the remaining (AC) coefficients have zero mean. = 1Tx is the DC coefficient. Show that Problem 4. (30 points) Consider a classification problem with two Gaussian classes PX|Y (xi) = G(x, i, ;), i {1,2} and class probabilities a) (5 points) The random variable X is not Gaussian, but we can still compute its mean and covariance. Show that = = 102 H=EX] = + f] . - ((X - .)(X - pa)|- -|. + 2] + +7 ( ) ( ). b) (5 points) In the remainder of this problem, we consider the 2-dimensional case with -[8], [2]. = = r = Using MATLAB, sample 1,000 points from the two Gaussian classes and make a plot of the sampled points for each of the following conditions: and where a > 0, and Py(1) Py (2) = 1/2. condition A: a = 10,0 = 2; condition B: a = 2,0 = 10. f-f=f= c) (5 points) Use MATLAB to perform a principal component analysis for the random variable X. Determine the direction of the best 1-dimensional subspace, i.e. the transformation z = 6x, where is the principal component of largest variance. Hand in a plot containing both the datapoints and this principal component for each of the conditions of b). d) (5 points) Repeat c), but now for the 1-dimensional subspace spanned by the linear discriminant o produced by LDA. e) (5 points) From the results above, is the PCA approach to dimensionality reduction always a good one from the classification point of view? How does it compare to LDA? f) (5 points) We now pursue a theoretical explanation for the observations above. Using the results of a), derive the principal component and the linear discriminant d' as functions of the parameters o and o. From a classification point of view, under what conditions is it 1) better to use PCA, 2) better to use LDA, or 3) identical to use any of the two? 3 Page < 3 of 4 ZOOM + Problem 5. (35 points) In this problem, we consider a dataset with faces from 6 people. These were divided into two sets. A training set is provided in the file trainset.zip and a test set in the file testset.zip. The original colored images of 150 x 150 pixels were converted to 50 x 50 grayscale pixels, resulting in a vector space of 2,500 dimensions. a) (10 points) Using the training data, compute the PCA of the data and make a 4 x 4 plot showing the 16 principal components of largest variance. b) (10 points) Consider the 15 different pairs of classes that can be derived from the 6 face classes. Perform an LDA between the classes in each pair. Make a 4x4 plot containing the 15 linear discriminants (plus one empty plot). (Note: You will likely realize that the within scatter matrix is singular. To address this, use an RDA of regularization parameter y = 1 instead of the LDA.) c) (5 points) For each image x in the training dataset, compute the projection vector px, where the rows of are the 15 principal components of largest variance of the face training data. Note that this produces a datasets (z;} of 15 dimensional vectors. Use the PCA projection vectors z, of the training images to learn a mean , and variance ; per class. Use these to implement the Gaussian classifier. Compute the PCA projections of the test images and use the Gaussian classifier above to classify them. Compute the average probability of classification error for each face class and the average error accross all classes. d) (5 points) Repeat c) using LDA projections z,, instead of PCA projections. (Note: You will likely realize that the within scatter matrix is singular. To address this, use an RDA of regularization parameter y=1 instead of the LDA.) e) (5 points) A popular alternative to RDA, when LDA requires the inversion of singular scatter matrix, consists of first applying a PCA to an intermediate dimension k and then apply LDA to the resulting k-dimensional vectors. This approach is denoted as PCA+LDA. Repeat d) using a PCA+LDA with k 30. Note: For a random variable X with multiple Gaussian classes of mean , and covariance E, the Gaussian classifier has decision rule i* = arg min (x-)(x ) + log |.|. Given a training set {x,...,xn) for class i, the class mean and variance are estimated with H k=1 = [(xx-) (xx-). 12 4 Page < 4 of 4 ZOOM + Probem 1. (10 points) Consider the hyperplane wx+b=0 of known parameters w and b. a) (5 points) Use Lagrangian optimization to find the point xo in the plane closest to the origin, as a function of w and b. b) (5 points) Use the result of a) to derive a geometric interpretation for the parameters w and b, when ||w|| = 1. Problem 2. (10 points) The entropy of probability density function (pdf) p(z) is defined as - p(z) log p(x)dr. r) h(x) = a) (5 points) Use Lagrangian optimization to find the pdf of maximal entropy among those whose expected value is and variance is o. b) (5 points) Find the values of the Lagrange multipliers associated with the optimal solution. 1 Problem 3. (15 points) Extensive experimental evidence in the area of image compression has shown that the Discrete Cosine Transform (DCT) of image patches is a very good approximation to their PCA. It is also well known that all but one of the DCT coefficients (features) have zero mean, and only one has non-zero mean. The latter is the so-called DC coefficient because it results from projecting the image patch into the vector 1 = (1,1,...,1), where d is the vector dimension and, therefore, is proportional to the average (DC) value of the patch. In this problem, we are going to explore the connection between the DCT and PCA to explain this fact. For this, we are going to assume the following. An image patch is a collection of random variables X = {X, X64} which are identically distributed Px. (x) = f(x), Vi {1,...,64}, where f(x) is a common probability density function. The pixels in the image patch are correlated, according to the correlation coefficient E[XX] E[X]VE[X] This obviously implies that we do not have an iid sample. Pij a) (5 points) Consider the PCA of X. Show that it is not affected by a change of variables of the type Z = X - 2, where = E[X]. b) (5 points) Given a), we can assume that X has zero mean. We will do so for the remainder of the problem. Show that in the extreme of highly correlated pixel values, i.e. when Pij 1, Vij the vector 1 is the largest principal component. Since neighboring image pixels do tend to be highly correlated, this helps explain why the DC coefficient is always present. c) (5 points) Let be the matrix whose columns ; are the principal components and consider the set of coefficients (features) Z resulting from the projection of an arbitrary image patch X into these components, i.e. z = $x. Consider the DCT coefficients z; = ofx, noting that 2 = E[zi] = 0, Vi > 1, i.e. that the remaining (AC) coefficients have zero mean. = 1Tx is the DC coefficient. Show that Problem 4. (30 points) Consider a classification problem with two Gaussian classes PX|Y (xi) = G(x, i, ;), i {1,2} and class probabilities a) (5 points) The random variable X is not Gaussian, but we can still compute its mean and covariance. Show that = = 102 H=EX] = + f] . - ((X - .)(X - pa)|- -|. + 2] + +7 ( ) ( ). b) (5 points) In the remainder of this problem, we consider the 2-dimensional case with -[8], [2]. = = r = Using MATLAB, sample 1,000 points from the two Gaussian classes and make a plot of the sampled points for each of the following conditions: and where a > 0, and Py(1) Py (2) = 1/2. condition A: a = 10,0 = 2; condition B: a = 2,0 = 10. f-f=f= c) (5 points) Use MATLAB to perform a principal component analysis for the random variable X. Determine the direction of the best 1-dimensional subspace, i.e. the transformation z = 6x, where is the principal component of largest variance. Hand in a plot containing both the datapoints and this principal component for each of the conditions of b). d) (5 points) Repeat c), but now for the 1-dimensional subspace spanned by the linear discriminant o produced by LDA. e) (5 points) From the results above, is the PCA approach to dimensionality reduction always a good one from the classification point of view? How does it compare to LDA? f) (5 points) We now pursue a theoretical explanation for the observations above. Using the results of a), derive the principal component and the linear discriminant d' as functions of the parameters o and o. From a classification point of view, under what conditions is it 1) better to use PCA, 2) better to use LDA, or 3) identical to use any of the two? 3 Page < 3 of 4 ZOOM + Problem 5. (35 points) In this problem, we consider a dataset with faces from 6 people. These were divided into two sets. A training set is provided in the file trainset.zip and a test set in the file testset.zip. The original colored images of 150 x 150 pixels were converted to 50 x 50 grayscale pixels, resulting in a vector space of 2,500 dimensions. a) (10 points) Using the training data, compute the PCA of the data and make a 4 x 4 plot showing the 16 principal components of largest variance. b) (10 points) Consider the 15 different pairs of classes that can be derived from the 6 face classes. Perform an LDA between the classes in each pair. Make a 4x4 plot containing the 15 linear discriminants (plus one empty plot). (Note: You will likely realize that the within scatter matrix is singular. To address this, use an RDA of regularization parameter y = 1 instead of the LDA.) c) (5 points) For each image x in the training dataset, compute the projection vector px, where the rows of are the 15 principal components of largest variance of the face training data. Note that this produces a datasets (z;} of 15 dimensional vectors. Use the PCA projection vectors z, of the training images to learn a mean , and variance ; per class. Use these to implement the Gaussian classifier. Compute the PCA projections of the test images and use the Gaussian classifier above to classify them. Compute the average probability of classification error for each face class and the average error accross all classes. d) (5 points) Repeat c) using LDA projections z,, instead of PCA projections. (Note: You will likely realize that the within scatter matrix is singular. To address this, use an RDA of regularization parameter y=1 instead of the LDA.) e) (5 points) A popular alternative to RDA, when LDA requires the inversion of singular scatter matrix, consists of first applying a PCA to an intermediate dimension k and then apply LDA to the resulting k-dimensional vectors. This approach is denoted as PCA+LDA. Repeat d) using a PCA+LDA with k 30. Note: For a random variable X with multiple Gaussian classes of mean , and covariance E, the Gaussian classifier has decision rule i* = arg min (x-)(x ) + log |.|. Given a training set {x,...,xn) for class i, the class mean and variance are estimated with H k=1 = [(xx-) (xx-). 12 4 Page < 4 of 4 ZOOM +
Expert Answer:
Answer rating: 100% (QA)
It appears youve shared a multipart assignment or examination consisting of various problems related to optimization statistics and machine learning c... View the full answer

Related Book For 

Posted Date:
Students also viewed these algorithms questions
-
Q1. You have identified a market opportunity for home media players that would cater for older members of the population. Many older people have difficulty in understanding the operating principles...
-
Give Correct ANSWERS Human-Computer Interaction (a) If you had been one of the original inventors of the WIMP interface, and engineers on the technical team had been sceptical about the advantages...
-
Holly needs $21,800 worth of new equipment for his shop. He can borrow this money at a discount rate of 11% for a year. Find the amount of the loan Holly should ask for so that the proceeds are...
-
Which is greater: an increase in temperature of 1 Celsius degree or an increase of 1 Fahrenheit degree?
-
No Friction is an industrial lubricant, which is formed by subjecting certain crude chemicals to two successive processes. The output of process 1 is passed to process 2, where it is blended with...
-
Consider an object of characteristic length \(0.015 \mathrm{~m}\) and a situation for which the temperature difference is \(10^{\circ} \mathrm{C}\). Evaluating thermophysical properties at the...
-
Winter Companys balance sheet at December 31, 2013, is presented below. During January 2014, the following transactions occurred. Winter uses the perpetual inventory method. Jan. 1 Winter accepted a...
-
An object moving along a horizontal track collides with and compresses a light spring (which obeys Hooke's Law) located at the end of the track. The spring constant is 40.7 N/m, the mass of the...
-
Air is compressed in an isentropic compressor from 15 psia and 70°F to 200 psia. Determine the outlet temperature and the work consumed by this compressor per unit mass of air. 200 psia Air...
-
The time t, in seconds, as measured on Flash Gordon's spaceship traveling at a speed v equals 2.2499 cross times 10 to the power of 8 space m s to the power of negative 1 end exponent is given by t...
-
Troy Engines, Limited, manufactures a variety of engines for use in heavy equipment. The company has always produced all of the necessary parts for its engines, including all of the carburetors. An...
-
Robert Corp. granted an incentive stock option for 200 shares to Beverly, an employee, on March 14, Year 12. The option price and FMV on the date of grant was$150. Beverly exercised the option on...
-
A company purchased a highspeed industrial centrifuge at a cost of $420,000. Shipping costs totaled $12,000. Foundation work to house the centrifuge cost $8,800. An additional water line had to be...
-
A real estate loan that is not insured or guaranteed by a government agency is a(n) known as: Define and explain the answer with example.
-
sarasota corporation produces high - performance rotors. it expects to produce 3 0 , 0 0 0 rotors in the coming year. it has invested $ 4 , 3 1 2 , 5 0 0 to produce rotors. the company has a required...
-
The elevator E shown in the figure moves downward with a constant velocity of 4 m/s. Determine ( a ) the velocity of the cable C , ( b ) the velocity of the counterweight W , ( c ) the relative...
-
A manufacturer can sell product 1 at a profit of $20 per unit and product 2 at a profit of $40 per unit. Three units of raw material are needed to manufacture one unit of product 1, and six units of...
-
Distinguish between medical savings accounts and Health Savings Accounts.
-
Briefly explain the following types of alternative work schedules: flextime, telecommuting, job sharing, and the condensed workweek.
-
Go to your college or university library or go online and search under the terms Personnel Management and Human Resources Management. Based on your findings, approximately when was the term Personnel...
-
Find the probability that a randomly selected person has an IQ score higher than 125. Is this an unusual event? Explain. In a standardized IQ test, scores are normally distributed, with a mean score...
-
Find the probability that the number of U.S. adults who say they have had someone take over their email accounts without their permission is (a) at most 40, (b) less than 45, and (c) exactly 48....
-
A random sample of 60 people is selected from this population. What is the probability that the mean IQ score of the sample is greater than 105 ? Interpret the result. In a standardized IQ test,...

Study smarter with the SolutionInn App