

Question: Problem A basic algorithm, for inducing a decision tree from training tuples, follows a top down approach, similar to those constructed by algorithms such as
Problem
A basic algorithm, for inducing a decision tree from training
tuples, follows a top down approach, similar to those constructed by
algorithms such as ID3, C4.5 and CART.
Part 1
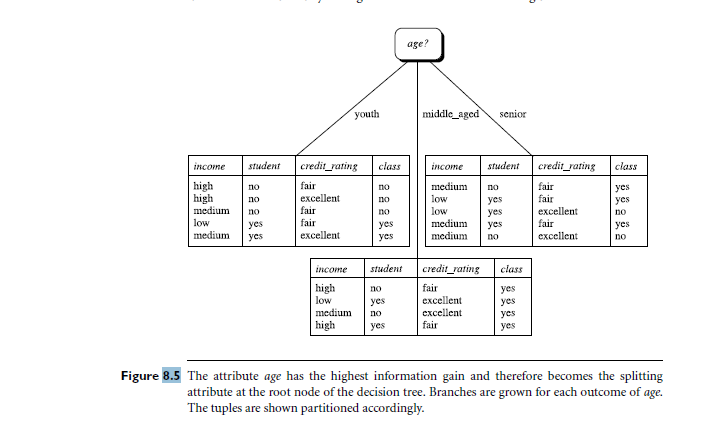
The execution of algorithm given in Section 8.2.1 is illustrated in Section 8.2.2, in Figure 8.5. The
illustration only shows the first two levels of the tree. Complete the example to show the entire
resulting decision tree. Include all nodes, branches and partitions.
REFERENCES
8.2.1 Decision Tree Induction
During the late 1970s and early 1980s, J. Ross Quinlan, a researcher in machine learning, developed a decision tree algorithm known as ID3 (Iterative Dichotomiser). This work expanded on earlier work on concept learning systems, described by E. B. Hunt, J. Marin, and P. T. Stone. Quinlan later presented C4.5 (a successor of ID3), which became a benchmark to which newer supervised learning algorithms are often compared. In 1984, a group of statisticians (L. Breiman, J. Friedman, R. Olshen, and C. Stone) published the book Classification and Regression Trees (CART), which described the generation of binary decision trees. ID3 and CART were invented independently of one another at around the same time, yet follow a similar approach for learning decision trees from training tuples. These two cornerstone algorithms spawned a flurry of work on decision tree induction. ID3, C4.5, and CART adopt a greedy (i.e., nonbacktracking) approach in which decision trees are constructed in a top-down recursive divide-and-conquer manner. Most algorithms for decision tree induction also follow a top-down approach, which starts with a training set of tuples and their associated class labels. The training set is recursively partitioned into smaller subsets as the tree is being built. A basic decision tree algorithm is summarized in Figure 8.3. At first glance, the algorithm may appear long, but fear not! It is quite straightforward. The strategy is as follows. The algorithm is called with three parameters: D, attribute list, and Attribute selection method. We refer to D as a data partition. Initially, it is the complete set of training tuples and their associated class labels. The parameter attribute list is a list of attributes describing the tuples. Attribute selection method specifies a heuristic procedure for selecting the attribute that best discriminates the given tuples according to class. This procedure employs an attribute selection measure such as information gain or the Gini index. Whether the tree is strictly binary is generally driven by the attribute selection measure. Some attribute selection measures, such as the Gini index, enforce the resulting tree to be binary. Others, like information gain, do not, therein allowingmultiway splits (i.e., two or more branches to be grown from a node).
-The tree starts as a single node, N, representing the training tuples in D (step 1).
-If the tuples in D are all of the same class, then node N becomes a leaf and is labeled with that class (steps 2 and 3). Note that steps 4 and 5 are terminating conditions. All terminating conditions are explained at the end of the algorithm.
-Otherwise, the algorithm calls Attribute selection method to determine the splitting criterion. The splitting criterion tells us which attribute to test at node N by determining the best way to separate or partition the tuples in D into individual classes (step 6). The splitting criterion also tells us which branches to grow from node N with respect to the outcomes of the chosen test. More specifically, the splitting criterion indicates the splitting attribute and may also indicate either a split-point or a splitting subset. The splitting criterion is determined so that, ideally, the resultingpartitions at each branch are as pure as possible. A partition is pure if all the tuples in it belong to the same class. In other words, if we split up the tuples in D according to themutually exclusive outcomes of the splitting criterion, we hope for the resulting partitions to be as pure as possible.
-The node N is labeled with the splitting criterion, which serves as a test at the node (step 7). A branch is grown from node N for each of the outcomes of the splitting criterion. The tuples in D are partitioned accordingly (steps 10 to 11). There are three possible scenarios, as illustrated in Figure 8.4. Let A be the splitting attribute. A has v distinct values, fa1, a2, : : : , avg, based on the training data.

Algorithm: Generate decision_tree. Generate a decision tree from the training tuples of data partition, D. Input: Data partition, D, which is a set of training tuples and their associated class labels; attribute list, the set of candidate attributes; Attribute selection.method, a procedure to determine the splitting criterion that "best partitions the data tuples into individual classes. This criterion consists of a splitting-attribute and, possibly, either a split-point or splitting subset. Output: A decision tree. Method: (1) create a node N; (2) if tuples in D are all of the same class, C, then (3) return N as a leaf node labeled with the class C (4) if attribute_list is empty thern (5) return N as a leaf node labeled with the majority class in D, I/ majority voting (6) apply Attribute.selection method(D, attribute list) to find the "best" splitting.criterion (7) label node N with splitting-criterion; (8) if splitting attribute is discrete-valued and multiway splits allowed then not restricted to binary trees (9) attribute list attribute list-splitting attribute; // remove splitting attribute (10) for each outcome j of splitting-criterion // partition the tuples and grow subtrees for each partition (1) e Dj be the set of data tuples in D satisfying outcome j II a partition (12) If Dj is empty then (13) (14) else attach the node returned by Generate.decision tree(Di, attribute list) to node N; attach a leaf labeled with the majority class in D to node N; endfor (15) return N; Figure 8.3 Basic algorithm for inducing a decision tree from training tuples
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts