

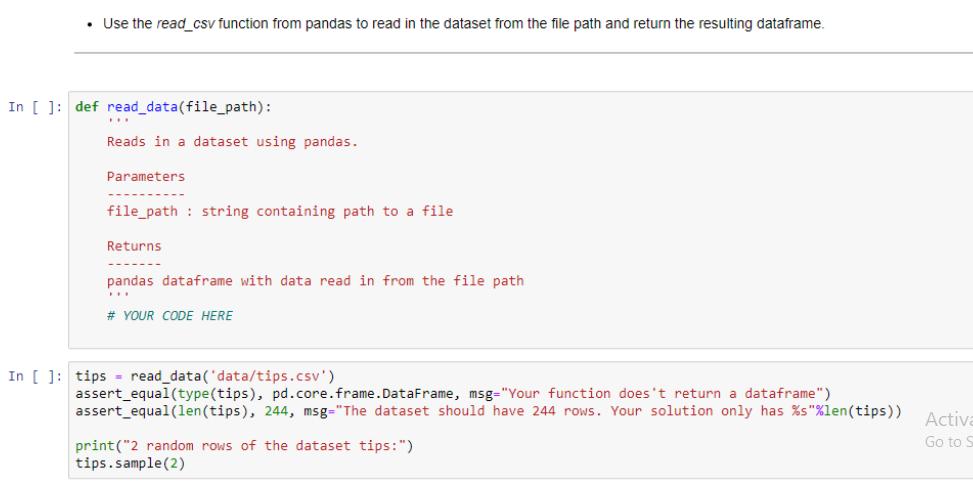
Use the read_csv function from pandas to read in the dataset from the file path and...
Fantastic news! We've Found the answer you've been seeking!
Question:
Transcribed Image Text:
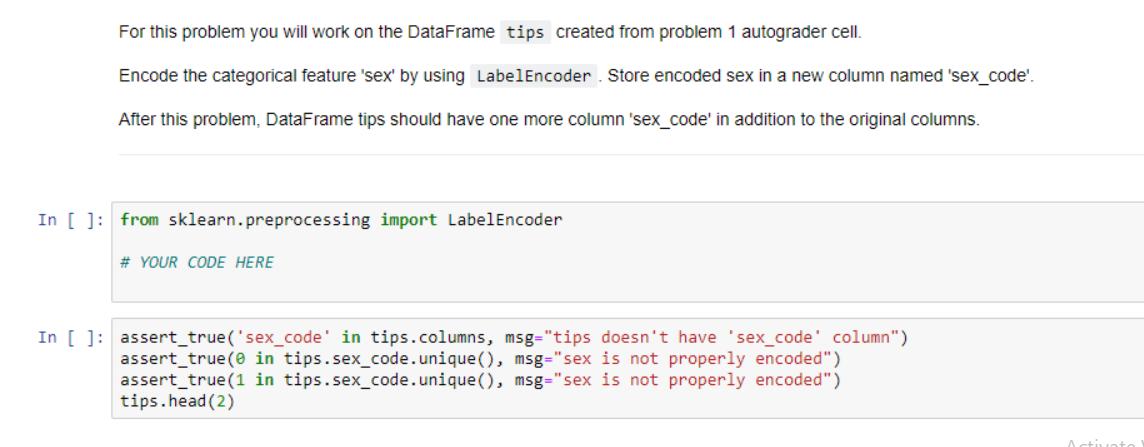
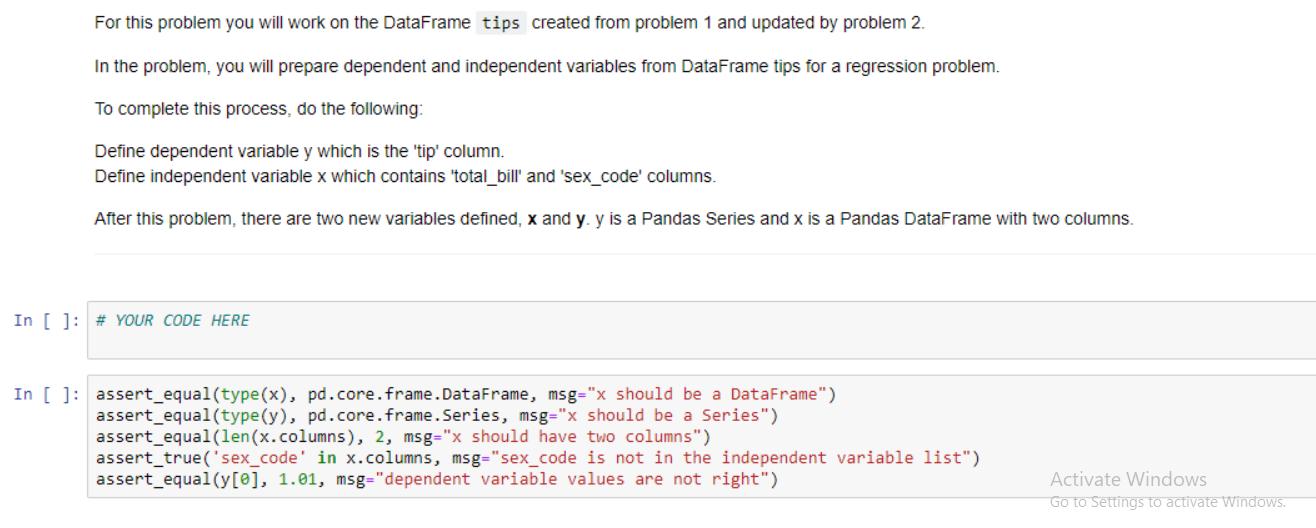
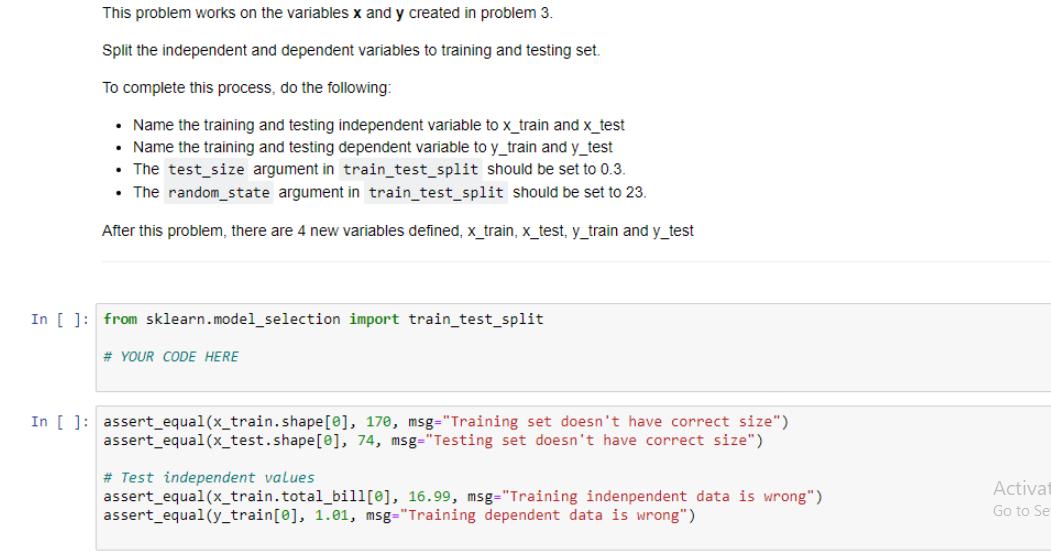
• Use the read_csv function from pandas to read in the dataset from the file path and return the resulting dataframe. In [ ]: def read_data(file_path): ... Reads in a dataset using pandas. Parameters file_path string containing path to a file Returns. pandas dataframe with data read in from the file path # YOUR CODE HERE In [ ]: tips = read_data('data/tips.csv') assert_equal (type (tips), pd.core.frame.DataFrame, msg="Your function does't return a dataframe") assert_equal(len (tips), 244, msg="The dataset should have 244 rows. Your solution only has %s"%len(tips)) print("2 random rows of the dataset tips:") tips.sample (2) Activa Go to S For this problem you will work on the DataFrame tips created from problem 1 autograder cell. Encode the categorical feature 'sex' by using LabelEncoder. Store encoded sex in a new column named 'sex_code'. After this problem, DataFrame tips should have one more column 'sex_code' in addition to the original columns. In []: from sklearn.preprocessing import LabelEncoder # YOUR CODE HERE In [ ]: assert_true ('sex_code' in tips.columns, msg="tips doesn't have 'sex_code' column") assert true (0 in tips.sex_code.unique(), msg="sex is not properly encoded") assert true (1 in tips.sex_code.unique (), msg="sex is not properly encoded") tips.head (2) Activato! For this problem you will work on the DataFrame tips created from problem 1 and updated by problem 2. In the problem, you will prepare dependent and independent variables from DataFrame tips for a regression problem. To complete this process, do the following: Define dependent variable y which is the 'tip' column. Define independent variable x which contains 'total_bill' and 'sex_code' columns. After this problem, there are two new variables defined, x and y. y is a Pandas Series and x is a Pandas DataFrame with two columns. In [ ]: # YOUR CODE HERE In [ ]: assert_equal (type (x), pd.core.frame.DataFrame, msg="x should be a DataFrame") assert equal (type (y), pd.core.frame. Series, msg="x should be a Series") assert_equal(len (x.columns), 2, msg="x should have two columns") assert true('sex_code' in x.columns, msg="sex_code is not in the independent variable list") assert_equal (y [0], 1.01, msg="dependent variable values are not right") Activate Windows Go to Settings to activate Windows. This problem works on the variables x and y created in problem 3. Split the independent and dependent variables to training and testing set. To complete this process, do the following: • Name the training and testing independent variable to x_train and x_test • Name the training and testing dependent variable to y_train and y_test • The test size argument in train_test_split should be set to 0.3. •The random_state argument in train_test_split should be set to 23. After this problem, there are 4 new variables defined, x_train, x_test, y_train and y_test In []: from sklearn.model_selection import train_test_split # YOUR CODE HERE In [ ]: assert_equal(x_train.shape [0], 170, msg="Training set doesn't have correct size") assert_equal(x_test.shape [0], 74, msg="Testing set doesn't have correct size") # Test independent values assert_equal (x_train.total_bill[0], 16.99, msg="Training indenpendent data is wrong"). assert_equal (y_train [0], 1.01, msg="Training dependent data is wrong") Activat Go to Se • Use the read_csv function from pandas to read in the dataset from the file path and return the resulting dataframe. In [ ]: def read_data(file_path): ... Reads in a dataset using pandas. Parameters file_path string containing path to a file Returns. pandas dataframe with data read in from the file path # YOUR CODE HERE In [ ]: tips = read_data('data/tips.csv') assert_equal (type (tips), pd.core.frame.DataFrame, msg="Your function does't return a dataframe") assert_equal(len (tips), 244, msg="The dataset should have 244 rows. Your solution only has %s"%len(tips)) print("2 random rows of the dataset tips:") tips.sample (2) Activa Go to S For this problem you will work on the DataFrame tips created from problem 1 autograder cell. Encode the categorical feature 'sex' by using LabelEncoder. Store encoded sex in a new column named 'sex_code'. After this problem, DataFrame tips should have one more column 'sex_code' in addition to the original columns. In []: from sklearn.preprocessing import LabelEncoder # YOUR CODE HERE In [ ]: assert_true ('sex_code' in tips.columns, msg="tips doesn't have 'sex_code' column") assert true (0 in tips.sex_code.unique(), msg="sex is not properly encoded") assert true (1 in tips.sex_code.unique (), msg="sex is not properly encoded") tips.head (2) Activato! For this problem you will work on the DataFrame tips created from problem 1 and updated by problem 2. In the problem, you will prepare dependent and independent variables from DataFrame tips for a regression problem. To complete this process, do the following: Define dependent variable y which is the 'tip' column. Define independent variable x which contains 'total_bill' and 'sex_code' columns. After this problem, there are two new variables defined, x and y. y is a Pandas Series and x is a Pandas DataFrame with two columns. In [ ]: # YOUR CODE HERE In [ ]: assert_equal (type (x), pd.core.frame.DataFrame, msg="x should be a DataFrame") assert equal (type (y), pd.core.frame. Series, msg="x should be a Series") assert_equal(len (x.columns), 2, msg="x should have two columns") assert true('sex_code' in x.columns, msg="sex_code is not in the independent variable list") assert_equal (y [0], 1.01, msg="dependent variable values are not right") Activate Windows Go to Settings to activate Windows. This problem works on the variables x and y created in problem 3. Split the independent and dependent variables to training and testing set. To complete this process, do the following: • Name the training and testing independent variable to x_train and x_test • Name the training and testing dependent variable to y_train and y_test • The test size argument in train_test_split should be set to 0.3. •The random_state argument in train_test_split should be set to 23. After this problem, there are 4 new variables defined, x_train, x_test, y_train and y_test In []: from sklearn.model_selection import train_test_split # YOUR CODE HERE In [ ]: assert_equal(x_train.shape [0], 170, msg="Training set doesn't have correct size") assert_equal(x_test.shape [0], 74, msg="Testing set doesn't have correct size") # Test independent values assert_equal (x_train.total_bill[0], 16.99, msg="Training indenpendent data is wrong"). assert_equal (y_train [0], 1.01, msg="Training dependent data is wrong") Activat Go to Se
Expert Answer:
Answer rating: 100% (QA)
Your code looks great It passes all of the assertions Here is a summary of your code PYTHON def read... View the full answer

Related Book For 

Introduction to Java Programming, Comprehensive Version
ISBN: 978-0133761313
10th Edition
Authors: Y. Daniel Liang
Posted Date:
Students also viewed these programming questions
-
What considerations (ethical or otherwise) do professional sports leagues prioritize when making decisions about relocating teams, particularly in light of the economic impact on local communities...
-
Luzadis Company makes furniture using the latest automated technology. The company uses a job-order costing system and applies manufacturing overhead cost to products based on machine-hours. The...
-
This assignment reviews object-oriented programming concepts such as classes, methods, constructors, accessor methods, and access modifiers. It makes use of an array of objects as a class data...
-
Alistair bought a house on 1 April 2000 for 125,000 and occupied the entire house as his principal private residence until 1 November 2008. As from that date, he rented out two rooms (comprising...
-
The ray of light shown in FIGURE 26-79 passes from medium 1 to medium 2 to medium 3. The index of refraction in medium 1 is n1, in medium 2 it is n2 > n1, and in medium 3 it is n3 > n2. Show that...
-
Expensive restaurant meals are income-elastic goods for most people, including Sanjay. Suppose his income falls by 10% this year. What can you predict about the change in Sanjays consumption of...
-
Based on the information in the Botox Application, what would happen to the optimum price and quantity if the government had collected a specific tax of \(\$ 75\) per vial of Botox? What welfare...
-
On April 1, Julie Spengel established Spengels Travel Agency. The following transactions were completed during the month. 1. Invested $15,000 cash to start the agency. 2. Paid $600 cash for April...
-
On January 1, Hawaiian Specialty Foods purchased equipment for $39,000. Residual value at the end of an estimated four-year service life is expected to be $3,910. The company expects the machine to...
-
You have just been hired as a new management trainee by Earrings Unlimited, a distributor of earrings to various retail outlets located in shopping malls across the country. In the past, the company...
-
Suppose a firm has an initial expenditure of $ 5 , 0 0 0 . The cash inflows are $ 1 , 1 5 0 at the end of year 1 , $ 1 , 3 5 0 at the end of year 2 , $ 7 0 0 at the end of year 3 , $ 1 , 6 0 0 at the...
-
On January 1 , 2 0 2 3 , P cheuse Lt e sold a fishing vessel to a customer in exchange for a five - year 4 5 0 , 0 0 0 promissory note with an annual interest rate of 5 % . Interest only payments are...
-
You may adapt or modify sections of the marketing plan template to suit your needs. However, your completed plan must include the following. Identification of current and relevant marketing issues...
-
Sherrod, Inc., reported pretax accounting income of $88 million for 2021. The following information relates to differences between pretax accounting income and taxable income: a. Income from...
-
2. Taking on the role of the management group that has been charged by Max Radford to assess what is really going on in the development/growth of the business of Muskoka Lakehouse Restaurants: (a)...
-
PharmaOne Inc. is a private company that operates a chain of 3 0 drug stores in Western Canada. PharmaOne is considering upgrading the software in its pharmacies to allow doctors offices to transmit...
-
A put option has a strike price of $ 3 5 and a stock price of $ 3 7 . If the option is trading at $ 2 . 2 5 , what is the time ( speculative ) value embedded in the option? $ 0 $ 0 . 7 5 $ 2 . 2 5 $ 3
-
A Firm intends to invest some capital for a period of 15 years; the Firm's Management considers three Options, each consisting of purchasing a machinery of a specific brand, different for each...
-
Programming Exercise 7.35 presents a console version of the popular hangman game. Write a GUI program that lets a user play the game. The user guesses a word by entering one letter at a time, as...
-
Write a method to sort a two-dimensional array using the following header: public static void sort(int m[][]) The method performs a primary sort on rows and a secondary sort on columns. For example,...
-
Write a program that animates the AVL tree insert, delete, and search methods, as shown in Figure 26.1. 2 i = hash(key) An entry ikey value N-1 Hash function FIGURE 27.1 A hash function maps a key to...
-
You find short time lags between deposits and withdrawals and large deposits made on Fridays. What should you suspect?
-
What are some ways to steal cash? What can help to prevent cash and check thefts?
-
What are some audit steps to catch skimming and money-laundering schemes?

Study smarter with the SolutionInn App