

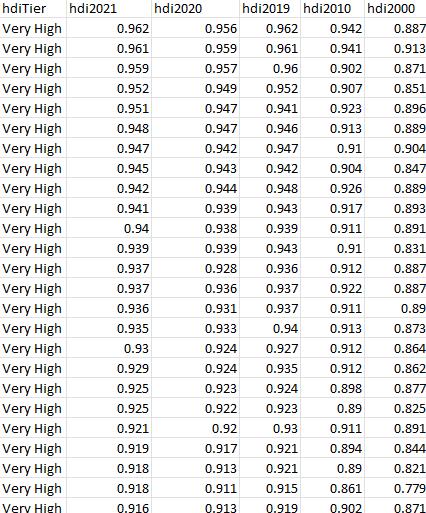
Using pandas, I need to calculate the average HDI for each category. The category is based...
Fantastic news! We've Found the answer you've been seeking!
Question:

Expert Answer:
To calculate the average HDI for each category you can use the Pandas library First you need to preprocess the data to make sure the HDI values are nu... View the full answer

Related Book For 

Applied Regression Analysis and Other Multivariable Methods
ISBN: 978-1285051086
5th edition
Authors: David G. Kleinbaum, Lawrence L. Kupper, Azhar Nizam, Eli S. Rosenberg
Posted Date:
