

We saw that our measurements of the prefix-sum function psum1 (Figure 5.1) yield a CPE of 9.00
Question:
We saw that our measurements of the prefix-sum function psum1 (Figure 5.1) yield a CPE of 9.00 on a machine where the basic operation to be performed, floating point addition, has a latency of just 3 clock cycles. Let us try to understand why our function performs so poorly.
The following is the assembly code for the inner loop of the function:
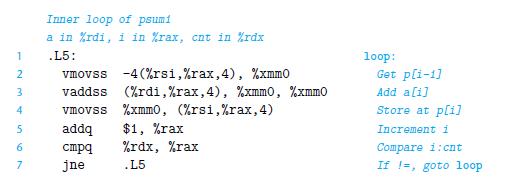
Perform an analysis similar to those shown for combine3 (Figure 5.14) and for write_read (Figure 5.36) to diagram the data dependencies created by this loop, and hence the critical path that forms as the computation proceeds. Explain why the CPE is so high.
Figure 5.1

Figure 5.14
![%xmmo mul %xmmo load %rax %rdx cmp jne (a) add %rdx data [/] %xmmo load mul %xmmo (b) %rdx add %rdx](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/2/2/0/2696538c8ed04f871698220267917.jpg)
Figure 5.36
Fantastic news! We've Found the answer you've been seeking!
Step by Step Answer:
We can see that this function has a writeread dependency ...View the full answer

Answered By
Amar Kumar Behera
I am an expert in science and technology. I provide dedicated guidance and help in understanding key concepts in various fields such as mechanical engineering, industrial engineering, electronics, computer science, physics and maths. I will help you clarify your doubts and explain ideas and concepts that are otherwise difficult to follow. I also provide proof reading services. I hold a number of degrees in engineering from top 10 universities of the US and Europe.
My experience spans 20 years in academia and industry. I have worked for top blue chip companies.
1+ Reviews
10+ Question Solved
Related Book For 

Computer Systems A Programmers Perspective
ISBN: 9781292101767
3rd Global Edition
Authors: Randal E. Bryant, David R. O'Hallaron
Question Posted:
