

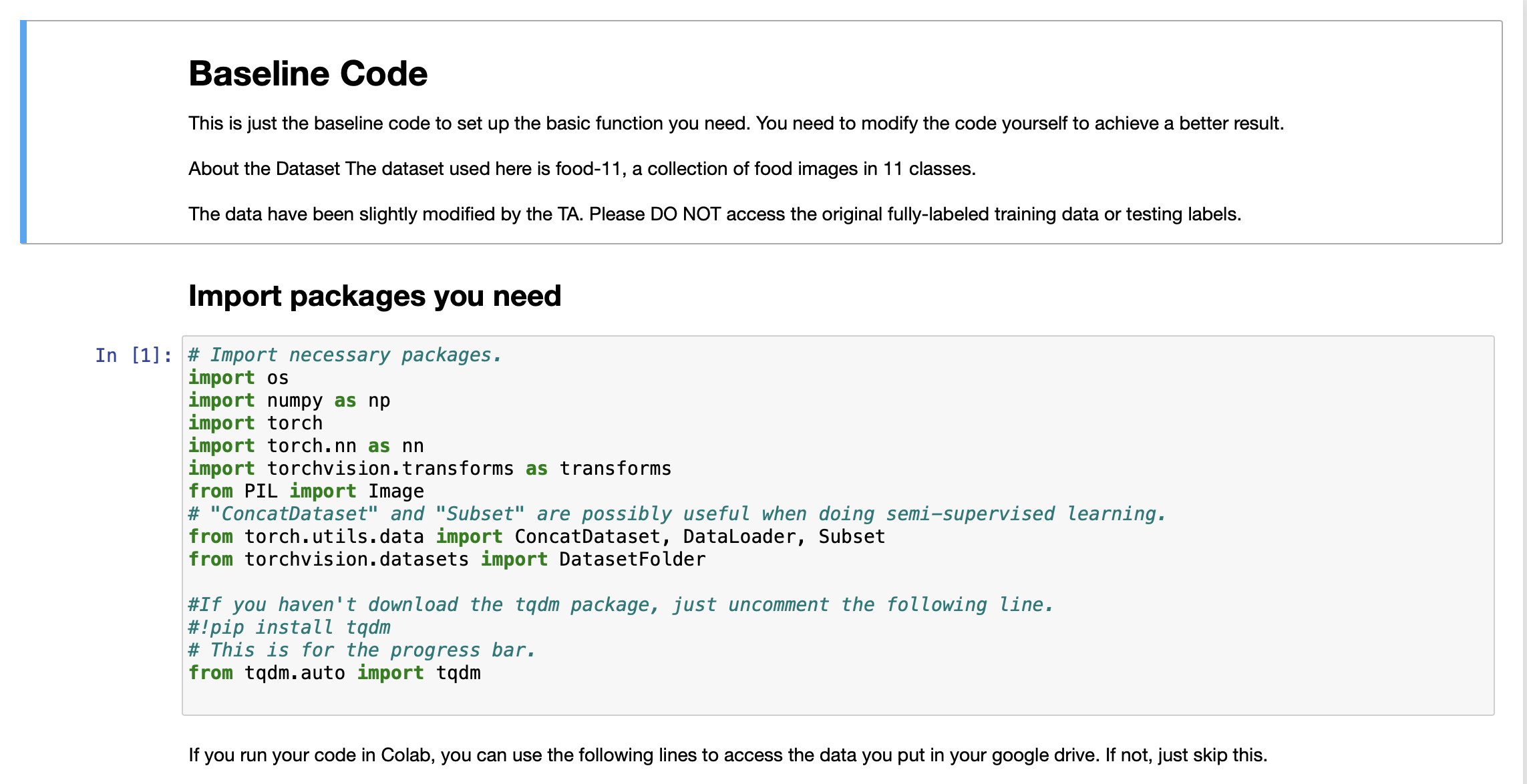
Baseline Code This is just the baseline code to set up the basic function you need....
Fantastic news! We've Found the answer you've been seeking!
Question:

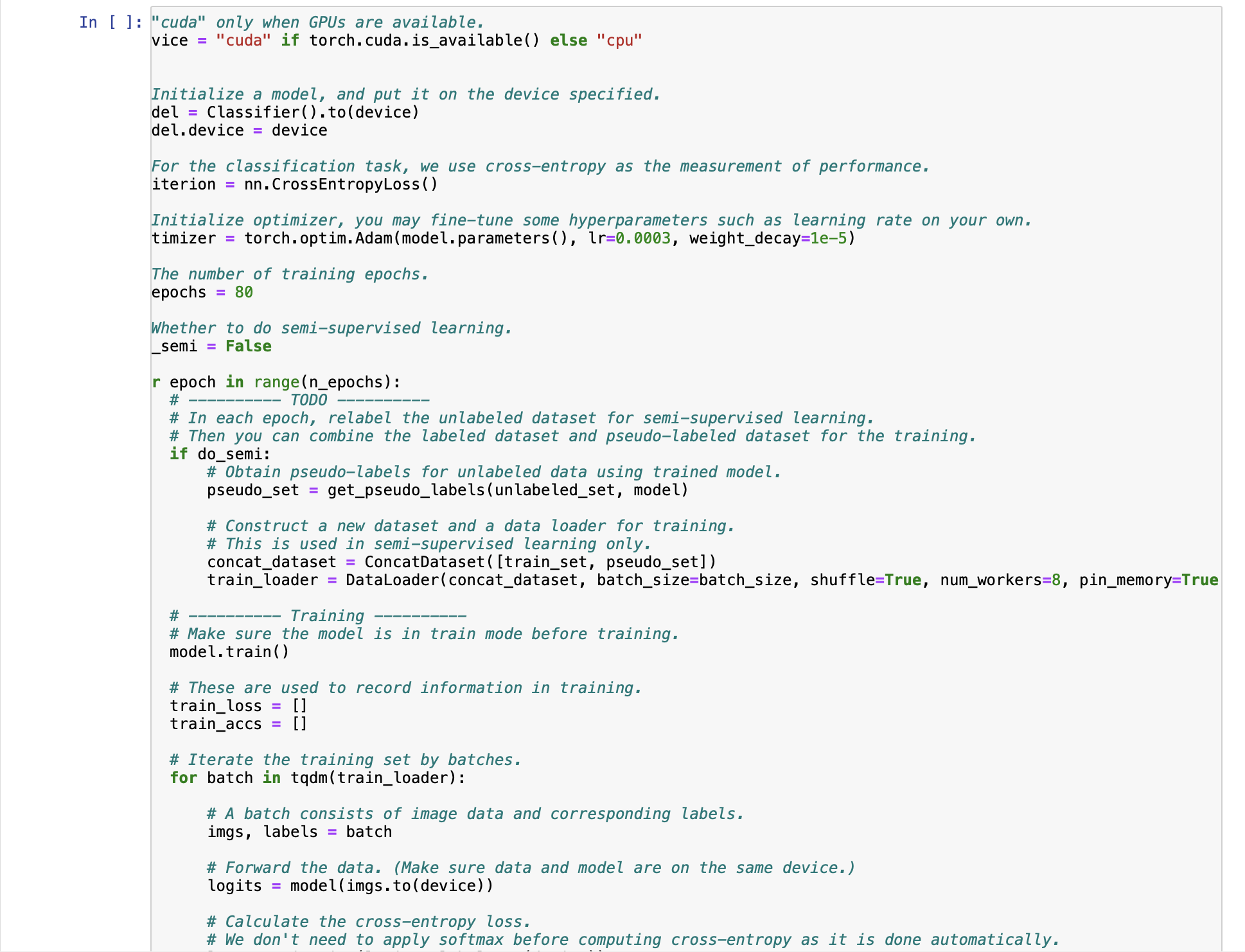

Transcribed Image Text:
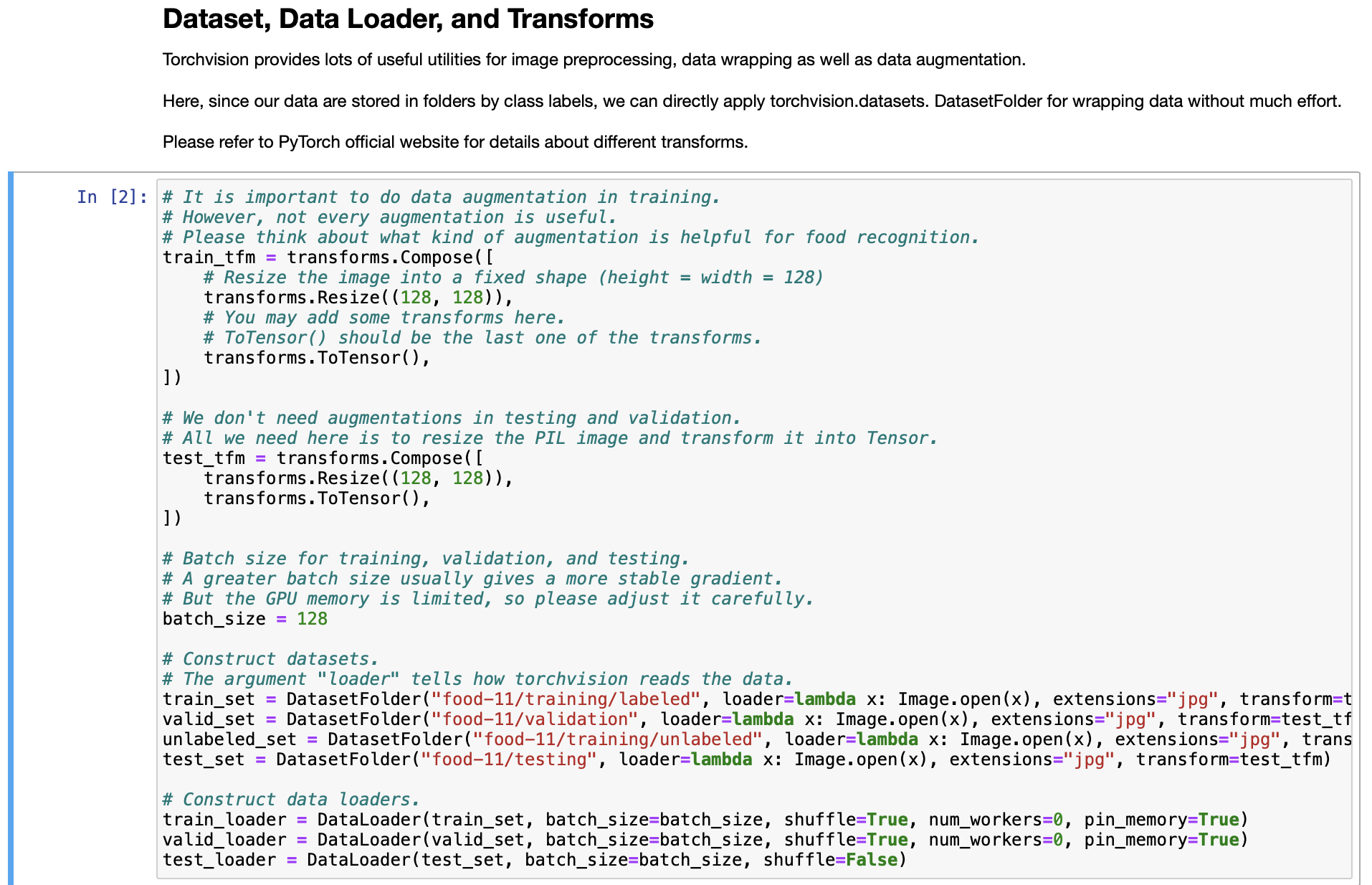
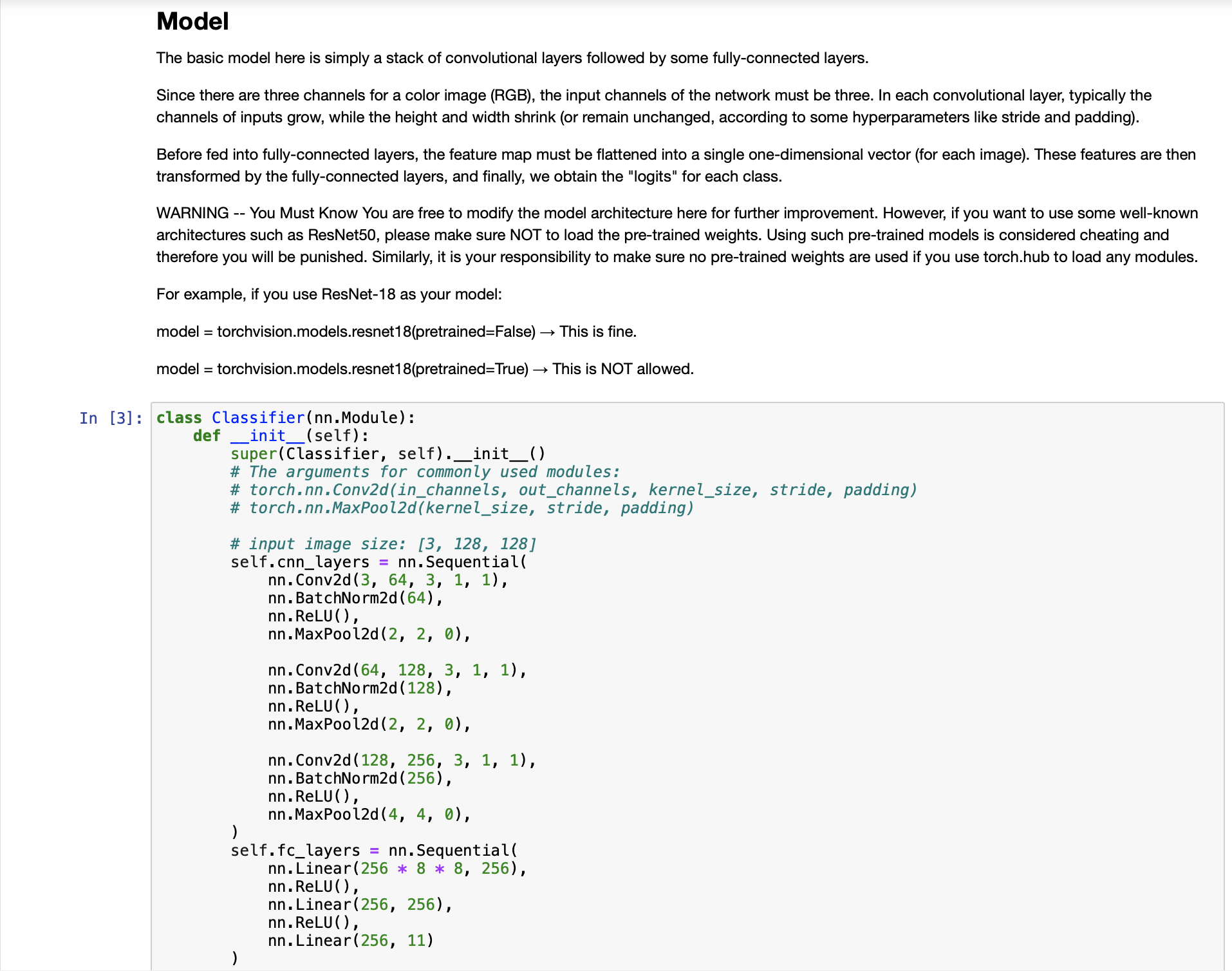
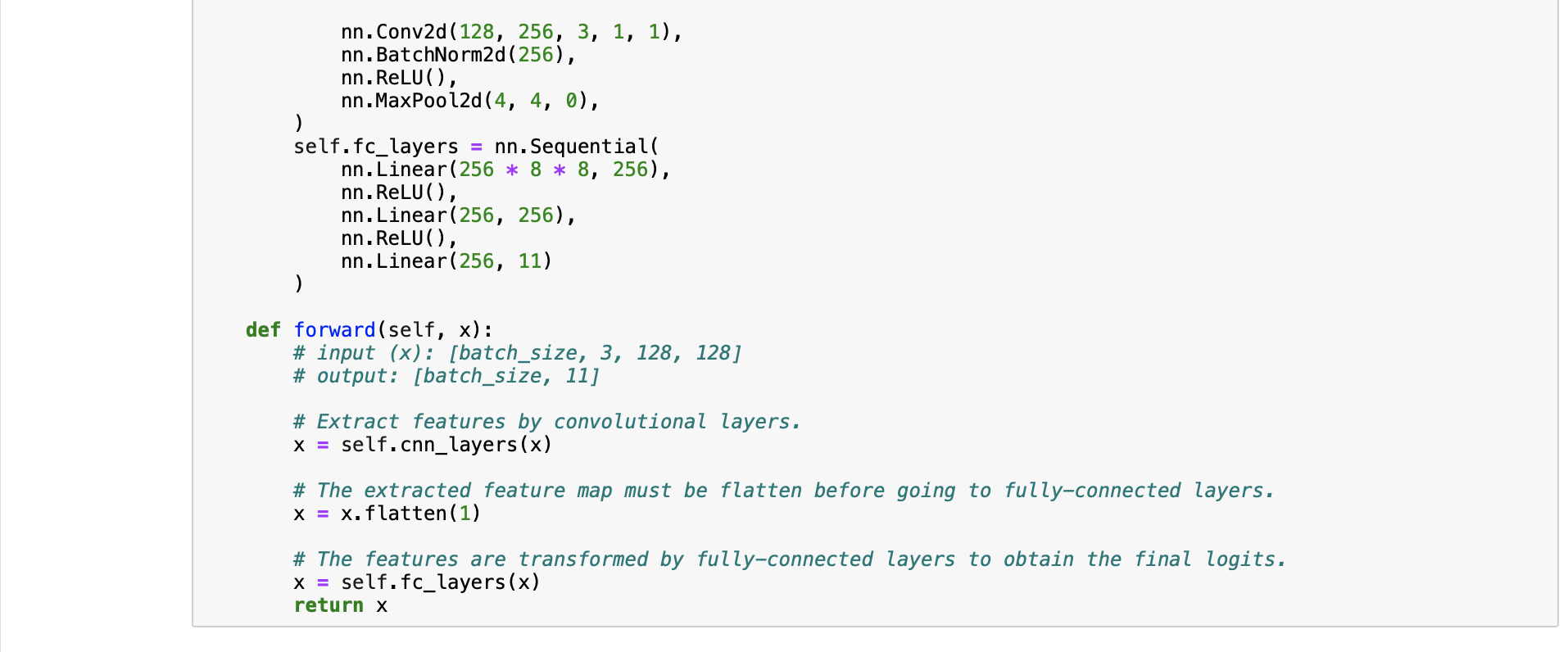
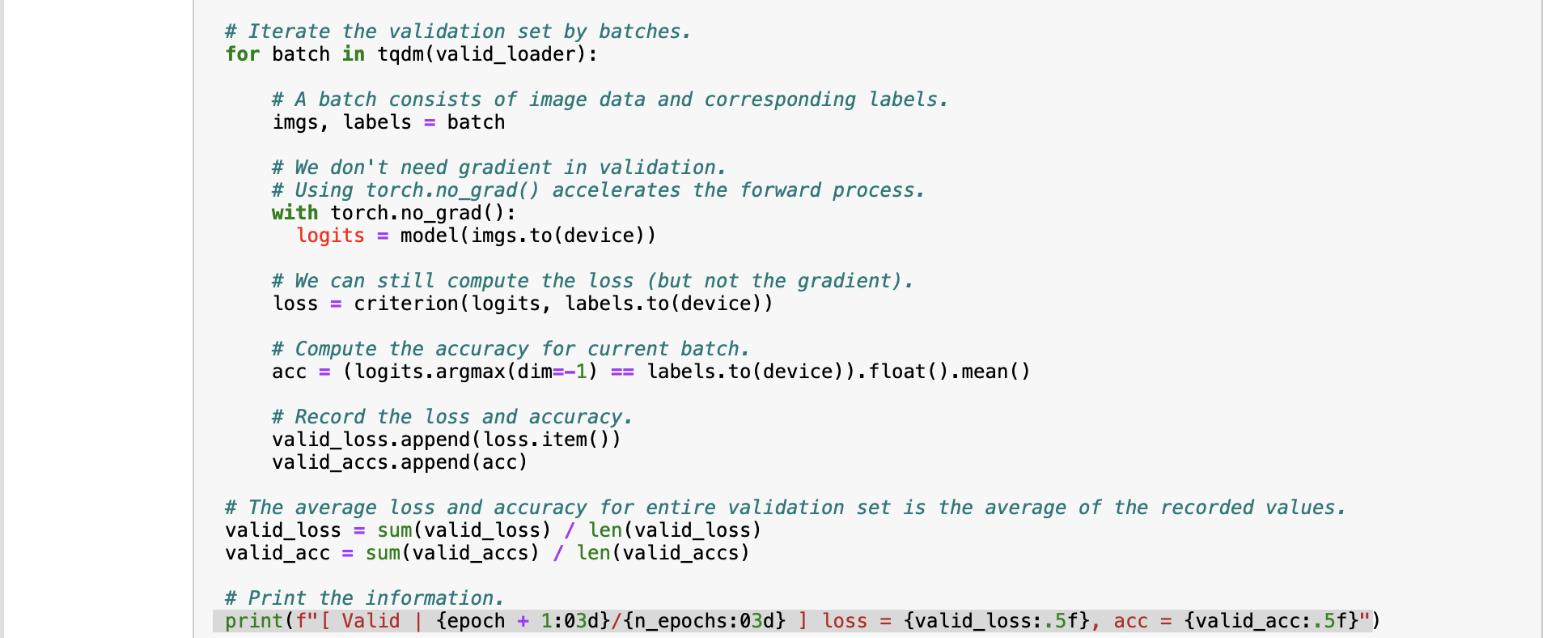
Baseline Code This is just the baseline code to set up the basic function you need. You need to modify the code yourself to achieve a better result. About the Dataset The dataset used here is food-11, a collection of food images in 11 classes. The data have been slightly modified by the TA. Please DO NOT access the original fully-labeled training data or testing labels. Import packages you need In [1]: # Import necessary packages. import os import numpy as np import torch import torch.nn as nn import torchvision.transforms as transforms from PIL import Image # "ConcatDataset" and "Subset" are possibly useful when doing semi-supervised learning. from torch.utils.data import ConcatDataset, DataLoader, Subset from torchvision.datasets import DatasetFolder #If you haven't download the tqdm package, just uncomment the following line. #!pip install tqdm # This is for the progress bar. from tqdm.auto import tqdm If you run your code in Colab, you can use the following lines to access the data you put in your google drive. If not, just skip this. Dataset, Data Loader, and Transforms Torchvision provides lots of useful utilities for image preprocessing, data wrapping as well as data augmentation. Here, since our data are stored in folders by class labels, we can directly apply torchvision.datasets. DatasetFolder for wrapping data without much effort. Please refer to PyTorch official website for details about different transforms. In [2] # It is important to do data augmentation in training. # However, not every augmentation is useful. # Please think about what kind of augmentation is helpful for food recognition. train_tfm = transforms.Compose ( [ # Resize the image into a fixed shape (height = width = 128) transforms.Resize((128, 128)), # You may add some transforms here. # ToTensor() should be the last one of the transforms. transforms.To Tensor(), ]) # We don't need augmentations in testing and validation. # All we need here is to resize the PIL image and transform it into Tensor. test_tfm = transforms.Compose ( [ 128)), transforms.Resize((128, transforms.To Tensor(), ]) #Batch size for training, validation, and testing. # A greater batch size usually gives a more stable gradient. #But the GPU memory is limited, so please adjust it carefully. batch_size = 128 # Construct datasets. # The argument "loader" tells how torchvision reads the data. train_set= DatasetFolder("food-11/training/labeled", loader=lambda x: Image.open(x), extensions="jpg", transform=t valid_set = DatasetFolder("food-11/validation", loader=lambda x: Image.open(x), extensions="jpg", transform=test_tf un labeled_set DatasetFolder("food-11/training/unlabeled", loader=lambda x: Image.open(x), extensions="jpg", trans test set = DatasetFolder("food-11/testing", loader=lambda x: Image.open(x), extensions="jpg", transform=test_tfm) # Construct data loaders. train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True) valid_loader = DataLoader(valid_set, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True) test_loader = DataLoader (test_set, batch_size=batch_size, shuffle=False) Model The basic model here is simply a stack of convolutional layers followed by some fully-connected layers. Since there are three channels for a color image (RGB), the input channels of the network must be three. In each convolutional layer, typically the channels of inputs grow, while the height and width shrink (or remain unchanged, according to some hyperparameters like stride and padding). Before fed into fully-connected layers, the feature map must be flattened into a single one-dimensional vector (for each image). These features are then transformed by the fully-connected layers, and finally, we obtain the "logits" for each class. WARNING You Must Know You are free to modify the model architecture here for further improvement. However, if you want to use some well-known architectures such as ResNet50, please make sure NOT to load the pre-trained weights. Using such pre-trained models is considered cheating and therefore you will be punished. Similarly, it is your responsibility to make sure no pre-trained weights are used if you use torch.hub to load any modules. For example, if you use ResNet-18 as your model: model = torchvision.models.resnet18(pretrained=False) - This is fine. model = torchvision.models.resnet18(pretrained=True) This is NOT allowed. -- In [3] class Classifier (nn. Module): def _init__(self): super(Classifier, self).__init__() # The arguments for commonly used modules: # torch.nn.Conv2d (in_channels, out_channels, kernel_size, stride, padding) #torch.nn.MaxPool2d (kernel_size, stride, padding) #input image size: [3, 128, 128] self.cnn_layers = nn.Sequential( nn. Conv2d (3, 64, 3, 1, 1), nn. BatchNorm2d (64), nn. ReLU ( ), nn. MaxPool2d (2, 2, 0), ) nn. Conv2d (64, 128, 3, 1, 1), nn. BatchNorm2d (128), nn. ReLU ( ), nn.MaxPool2d (2, 2, 0), nn. Conv2d (128, 256, 3, 1, 1), nn. BatchNorm2d (256), nn. ReLU (), nn. MaxPool2d (4, 4, 0), self.fc_layers = nn.Sequential( nn. Linear (256 * 8 * 8, 256), nn. ReLU (), nn. Linear (256, 256), nn. ReLU ( ), nn. Linear (256, 11) ) nn. Conv2d (128, 256, 3, 1, 1), nn. BatchNorm2d (256), nn. ReLU ( ), nn. MaxPool2d (4, 4, 0), self.fc_layers = nn.Sequential( nn. Linear (256*8* 8, 256), nn. ReLU ( ), nn. Linear (256, 256), nn. ReLU ( ), nn. Linear (256, 11) ) def forward(self,x): # input (x): [batch_size, 3, 128, 128] # output: [batch_size, 11] # Extract features by convolutional layers. x = self.cnn_layers (x) # The extracted feature map must be flatten before going to fully-connected layers. x = x. flatten (1) # The features are transformed by fully-connected layers to obtain the final logits. x = self.fc_layers (x) return x Training You can finish supervised learning by simply running the provided code without any modification. The function "get_pseudo_labels" is used for semi-supervised learning. It is expected to get better performance if you use unlabeled data for semi- supervised learning. However, you have to implement the function on your own and need to adjust several hyperparameters manually. In [4]: f get_pseudo_labels (dataset, model, threshold=0.65): # This functions generates pseudo-labels of a dataset using given model. # It returns an instance of DatasetFolder containing images whose prediction confidences exceed a given threshold # You are NOT allowed to use any models trained on external data for pseudo-labeling. device = "cuda" if torch.cuda.is_available() else "cpu" # Make sure the model is in eval mode. model. eval() # Define softmax function. softmax = nn.Softmax (dim=-1) # Iterate over the dataset by batches. for batch in tqdm(dataloader): img, = batch # Forward the data # Using torch.no_grad() accelerates the forward process. with torch.no_grad(): logits model(img.to (device)) = # Obtain the probability distributions by applying softmax on logits. probs = softmax (logits) # you may filter the data and construct a new dataset here. # # Turn off the eval mode. model.train() return dataset In [ ] "cuda" only when GPUs are available. vice = "cuda" if torch.cuda.is_available() else "cpu" Initialize a model, and put it on the device specified. del Classifier().to (device) = del.device = device For the classification task, we use cross-entropy as the measurement of performance. iterion nn. Cross Entropy Loss() = Initialize optimizer, you may fine-tune some hyperparameters such as learning rate on your own. timizer = torch.optim. Adam (model.parameters(), lr=0.0003, weight_decay=1e-5) The number of training epochs. epochs = 80 Whether to do semi-supervised learning. semi False r epoch in range(n_epochs): # TODO # In each epoch, relabel the unlabeled dataset for semi-supervised learning. # Then you can combine the labeled dataset and pseudo-labeled dataset for the training. if do_semi: # Obtain pseudo-labels for unlabeled data using trained model. pseudo_set get_pseudo_labels (unlabeled_set, model) # Construct a new dataset and a data loader for training. # This is used in semi-supervised learning only. concat_dataset = ConcatDataset ( [train_set, pseudo_set]) train_loader = DataLoader (concat_dataset, batch_size=batch_size, shuffle=True, num_workers=8, pin_memory=True # Training # Make sure the model is in train mode before training. model.train() # These are used to record information in training. train_loss = [] train_accs = [] # Iterate the training set by batches. for batch in tqdm (train_loader): # A batch consists of image data and corresponding labels. imgs, labels = batch # Forward the data. (Make sure data and model are on the same device.) logits = model(imgs.to (device)) # Calculate the cross-entropy loss. # We don't need to apply softmax before computing cross-entropy as it is done automatically. # Iterate the validation set by batches. for batch in tqdm (valid_loader): # A batch consists of image data and corresponding labels. imgs, labels = batch # We don't need gradient in validation. # Using torch.no_grad() accelerates the forward process. with torch.no_grad(): logits model(imgs.to (device)) # We can still compute the loss (but not the gradient). loss = criterion (logits, labels.to (device)) # Compute the accuracy for current batch. acc = (logits.argmax (dim=-1) # Record the loss and accuracy. valid_loss.append(loss.item()) valid_accs.append(acc) labels.to (device)).float() .mean() # The average loss and accuracy for entire validation set is the average of the recorded values. valid_loss sum(valid_loss) / len(valid_loss) valid_acc = sum(valid_accs) / len(valid_accs) #Print the information. print (f" [Valid | {epoch + 1:03d}/{n_epochs:03d} ] loss = {valid_loss:.5f}, acc = {valid_acc:.5f}") Testing For inference, we need to make sure the model is in eval mode, and the order of the dataset should not be shuffled ("shuffle=False" in test_loader). In [ ] # Make sure the model is in eval mode. # Some modules like Dropout or BatchNorm affect if the model is in training mode. model.eval() # Initialize a list to store the predictions. predictions = [] # Iterate the testing set by batches. for batch in tqdm(test_loader): # A batch consists of image data and corresponding labels. # But here the variable "labels" is useless since we do not have the ground-truth. # If printing out the labels, you will find that it is always 0. # This is because the wrapper (DatasetFolder) returns images and labels for each batch, # so we have to create fake labels to make it work normally. imgs, labels = batch # We don't need gradient in testing, and we don't even have labels to compute loss. # Using torch.no_grad() accelerates the forward process. with torch.no_grad(): logits model(imgs.to (device)) = # Take the class with greatest logit as prediction and record it. predictions.extend(logits.argmax(dim=-1).cpu().numpy().tolist()) In [ ]: Save predictions into the file. with open("predict.csv", "w") as f: # The first row must be "Id, Category" f.write("Id, Category ") # For the rest of the rows, each image id corresponds to a predicted class. for i, pred in enumerate(predictions): f.write(f"{i}, {pred} ") Hints for better result Design a better architecture Adopt different data augmentations to improve the performance. Utilize provided unlabeled data in training set Baseline Code This is just the baseline code to set up the basic function you need. You need to modify the code yourself to achieve a better result. About the Dataset The dataset used here is food-11, a collection of food images in 11 classes. The data have been slightly modified by the TA. Please DO NOT access the original fully-labeled training data or testing labels. Import packages you need In [1]: # Import necessary packages. import os import numpy as np import torch import torch.nn as nn import torchvision.transforms as transforms from PIL import Image # "ConcatDataset" and "Subset" are possibly useful when doing semi-supervised learning. from torch.utils.data import ConcatDataset, DataLoader, Subset from torchvision.datasets import DatasetFolder #If you haven't download the tqdm package, just uncomment the following line. #!pip install tqdm # This is for the progress bar. from tqdm.auto import tqdm If you run your code in Colab, you can use the following lines to access the data you put in your google drive. If not, just skip this. Dataset, Data Loader, and Transforms Torchvision provides lots of useful utilities for image preprocessing, data wrapping as well as data augmentation. Here, since our data are stored in folders by class labels, we can directly apply torchvision.datasets. DatasetFolder for wrapping data without much effort. Please refer to PyTorch official website for details about different transforms. In [2] # It is important to do data augmentation in training. # However, not every augmentation is useful. # Please think about what kind of augmentation is helpful for food recognition. train_tfm = transforms.Compose ( [ # Resize the image into a fixed shape (height = width = 128) transforms.Resize((128, 128)), # You may add some transforms here. # ToTensor() should be the last one of the transforms. transforms.To Tensor(), ]) # We don't need augmentations in testing and validation. # All we need here is to resize the PIL image and transform it into Tensor. test_tfm = transforms.Compose ( [ 128)), transforms.Resize((128, transforms.To Tensor(), ]) #Batch size for training, validation, and testing. # A greater batch size usually gives a more stable gradient. #But the GPU memory is limited, so please adjust it carefully. batch_size = 128 # Construct datasets. # The argument "loader" tells how torchvision reads the data. train_set= DatasetFolder("food-11/training/labeled", loader=lambda x: Image.open(x), extensions="jpg", transform=t valid_set = DatasetFolder("food-11/validation", loader=lambda x: Image.open(x), extensions="jpg", transform=test_tf un labeled_set DatasetFolder("food-11/training/unlabeled", loader=lambda x: Image.open(x), extensions="jpg", trans test set = DatasetFolder("food-11/testing", loader=lambda x: Image.open(x), extensions="jpg", transform=test_tfm) # Construct data loaders. train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True) valid_loader = DataLoader(valid_set, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True) test_loader = DataLoader (test_set, batch_size=batch_size, shuffle=False) Model The basic model here is simply a stack of convolutional layers followed by some fully-connected layers. Since there are three channels for a color image (RGB), the input channels of the network must be three. In each convolutional layer, typically the channels of inputs grow, while the height and width shrink (or remain unchanged, according to some hyperparameters like stride and padding). Before fed into fully-connected layers, the feature map must be flattened into a single one-dimensional vector (for each image). These features are then transformed by the fully-connected layers, and finally, we obtain the "logits" for each class. WARNING You Must Know You are free to modify the model architecture here for further improvement. However, if you want to use some well-known architectures such as ResNet50, please make sure NOT to load the pre-trained weights. Using such pre-trained models is considered cheating and therefore you will be punished. Similarly, it is your responsibility to make sure no pre-trained weights are used if you use torch.hub to load any modules. For example, if you use ResNet-18 as your model: model = torchvision.models.resnet18(pretrained=False) - This is fine. model = torchvision.models.resnet18(pretrained=True) This is NOT allowed. -- In [3] class Classifier (nn. Module): def _init__(self): super(Classifier, self).__init__() # The arguments for commonly used modules: # torch.nn.Conv2d (in_channels, out_channels, kernel_size, stride, padding) #torch.nn.MaxPool2d (kernel_size, stride, padding) #input image size: [3, 128, 128] self.cnn_layers = nn.Sequential( nn. Conv2d (3, 64, 3, 1, 1), nn. BatchNorm2d (64), nn. ReLU ( ), nn. MaxPool2d (2, 2, 0), ) nn. Conv2d (64, 128, 3, 1, 1), nn. BatchNorm2d (128), nn. ReLU ( ), nn.MaxPool2d (2, 2, 0), nn. Conv2d (128, 256, 3, 1, 1), nn. BatchNorm2d (256), nn. ReLU (), nn. MaxPool2d (4, 4, 0), self.fc_layers = nn.Sequential( nn. Linear (256 * 8 * 8, 256), nn. ReLU (), nn. Linear (256, 256), nn. ReLU ( ), nn. Linear (256, 11) ) nn. Conv2d (128, 256, 3, 1, 1), nn. BatchNorm2d (256), nn. ReLU ( ), nn. MaxPool2d (4, 4, 0), self.fc_layers = nn.Sequential( nn. Linear (256*8* 8, 256), nn. ReLU ( ), nn. Linear (256, 256), nn. ReLU ( ), nn. Linear (256, 11) ) def forward(self,x): # input (x): [batch_size, 3, 128, 128] # output: [batch_size, 11] # Extract features by convolutional layers. x = self.cnn_layers (x) # The extracted feature map must be flatten before going to fully-connected layers. x = x. flatten (1) # The features are transformed by fully-connected layers to obtain the final logits. x = self.fc_layers (x) return x Training You can finish supervised learning by simply running the provided code without any modification. The function "get_pseudo_labels" is used for semi-supervised learning. It is expected to get better performance if you use unlabeled data for semi- supervised learning. However, you have to implement the function on your own and need to adjust several hyperparameters manually. In [4]: f get_pseudo_labels (dataset, model, threshold=0.65): # This functions generates pseudo-labels of a dataset using given model. # It returns an instance of DatasetFolder containing images whose prediction confidences exceed a given threshold # You are NOT allowed to use any models trained on external data for pseudo-labeling. device = "cuda" if torch.cuda.is_available() else "cpu" # Make sure the model is in eval mode. model. eval() # Define softmax function. softmax = nn.Softmax (dim=-1) # Iterate over the dataset by batches. for batch in tqdm(dataloader): img, = batch # Forward the data # Using torch.no_grad() accelerates the forward process. with torch.no_grad(): logits model(img.to (device)) = # Obtain the probability distributions by applying softmax on logits. probs = softmax (logits) # you may filter the data and construct a new dataset here. # # Turn off the eval mode. model.train() return dataset In [ ] "cuda" only when GPUs are available. vice = "cuda" if torch.cuda.is_available() else "cpu" Initialize a model, and put it on the device specified. del Classifier().to (device) = del.device = device For the classification task, we use cross-entropy as the measurement of performance. iterion nn. Cross Entropy Loss() = Initialize optimizer, you may fine-tune some hyperparameters such as learning rate on your own. timizer = torch.optim. Adam (model.parameters(), lr=0.0003, weight_decay=1e-5) The number of training epochs. epochs = 80 Whether to do semi-supervised learning. semi False r epoch in range(n_epochs): # TODO # In each epoch, relabel the unlabeled dataset for semi-supervised learning. # Then you can combine the labeled dataset and pseudo-labeled dataset for the training. if do_semi: # Obtain pseudo-labels for unlabeled data using trained model. pseudo_set get_pseudo_labels (unlabeled_set, model) # Construct a new dataset and a data loader for training. # This is used in semi-supervised learning only. concat_dataset = ConcatDataset ( [train_set, pseudo_set]) train_loader = DataLoader (concat_dataset, batch_size=batch_size, shuffle=True, num_workers=8, pin_memory=True # Training # Make sure the model is in train mode before training. model.train() # These are used to record information in training. train_loss = [] train_accs = [] # Iterate the training set by batches. for batch in tqdm (train_loader): # A batch consists of image data and corresponding labels. imgs, labels = batch # Forward the data. (Make sure data and model are on the same device.) logits = model(imgs.to (device)) # Calculate the cross-entropy loss. # We don't need to apply softmax before computing cross-entropy as it is done automatically. # Iterate the validation set by batches. for batch in tqdm (valid_loader): # A batch consists of image data and corresponding labels. imgs, labels = batch # We don't need gradient in validation. # Using torch.no_grad() accelerates the forward process. with torch.no_grad(): logits model(imgs.to (device)) # We can still compute the loss (but not the gradient). loss = criterion (logits, labels.to (device)) # Compute the accuracy for current batch. acc = (logits.argmax (dim=-1) # Record the loss and accuracy. valid_loss.append(loss.item()) valid_accs.append(acc) labels.to (device)).float() .mean() # The average loss and accuracy for entire validation set is the average of the recorded values. valid_loss sum(valid_loss) / len(valid_loss) valid_acc = sum(valid_accs) / len(valid_accs) #Print the information. print (f" [Valid | {epoch + 1:03d}/{n_epochs:03d} ] loss = {valid_loss:.5f}, acc = {valid_acc:.5f}") Testing For inference, we need to make sure the model is in eval mode, and the order of the dataset should not be shuffled ("shuffle=False" in test_loader). In [ ] # Make sure the model is in eval mode. # Some modules like Dropout or BatchNorm affect if the model is in training mode. model.eval() # Initialize a list to store the predictions. predictions = [] # Iterate the testing set by batches. for batch in tqdm(test_loader): # A batch consists of image data and corresponding labels. # But here the variable "labels" is useless since we do not have the ground-truth. # If printing out the labels, you will find that it is always 0. # This is because the wrapper (DatasetFolder) returns images and labels for each batch, # so we have to create fake labels to make it work normally. imgs, labels = batch # We don't need gradient in testing, and we don't even have labels to compute loss. # Using torch.no_grad() accelerates the forward process. with torch.no_grad(): logits model(imgs.to (device)) = # Take the class with greatest logit as prediction and record it. predictions.extend(logits.argmax(dim=-1).cpu().numpy().tolist()) In [ ]: Save predictions into the file. with open("predict.csv", "w") as f: # The first row must be "Id, Category" f.write("Id, Category ") # For the rest of the rows, each image id corresponds to a predicted class. for i, pred in enumerate(predictions): f.write(f"{i}, {pred} ") Hints for better result Design a better architecture Adopt different data augmentations to improve the performance. Utilize provided unlabeled data in training set
Expert Answer:

Related Book For 

Understanding Cross Cultural Management
ISBN: 9781292015897
3rd Edition
Authors: Marie Joelle Browaeys, Roger Price
Posted Date:
Students also viewed these programming questions
-
Planning is one of the most important management functions in any business. A front office managers first step in planning should involve determine the departments goals. Planning also includes...
-
A small consulting company wants to make the switch to QuickBooks Online. All of their expenses are paid at the time they are incurred, so there is no need to track bills in the system. There is only...
-
Why are variances usually written off to cost of goods sold?
-
What are the potential consequences of not having (or not following) a Strategic Plan?
-
The Clifford Corporation has announced a rights offer to raise $50 million for a new journal, the Journal of Financial Excess. This journal will review potential articles after the author pays a...
-
Comparative data extracted from the general purpose financial statements and notes thereto of Express Delivery Ltd are presented below. Required (a) Prepare a trend analysis of the data. (b) Comment...
-
Boston Clothing Limited was a private company that experienced cash flow difficulties and hired new management to turn the company around. The company then went public and the shares sold at $15 per...
-
FIGURE shows a closed loop system with a variable gain element G in the feedback path. (a) Derive an expression for y/x (b) Show that for large values of K1 and K2 the value of y/x can be varied...
-
Briefly discuss community action plan to alleviate cigarette smoking in Maricopa County, Arizona.
-
Greg is thinking of a number, n and he wants his sister to guess the number. His first clue is that 3 less than 2 times his number is at least 5 and at most 7. Write and solve a compound inequality...
-
Simplify the following. $3942 219 1 +0.28 x 365 $3942 219 1+0.28x 365 = S $ (Type an integer or a decimal.)
-
Reimbursement Rates Blue Cross Highmark $20 $35 per visit per visit Variable Costs Resource Inputs Labor 48,000 total hours Supplies 65,000 total units Resource Input Prices Labor $25.00 per hour...
-
1. Solve for x in the exponential equation 5* 2. Explain how you can rewrite the equation 5 125. 125 in logarithmic form.
-
A $22,000 car loan incurs a 12.0% annual interest rate, but the loan is compounded monthly. What is the effective annual rate?
-
Background Belle has been managing a small company making signs for the last five years. The company has grown significantly in this time. The company has purchased numerous assets, expanded the...
-
Anna, a high school counselor, devised a program that integrates classroom learning with vocational training to help adolescents at risk for school dropouts stay in school and transition to work...
-
On initial examination, the findings of the GLOBE project appear to be an ambitious and elaborate extension of Hofstedes research, a development of Hofstedes doctrine and a corrective of Hofstedes...
-
If you incorporated an element on ethics into such a programme, what would it look like and what would be its main objective?
-
As the text indicates, companies tend not to give explicit attention to cultural issues when planning and implementing organisational change. Laurent advocates a dual approach to address this...
-
Which forecasting technique is more qualitative, the Delphi method or linear regression?
-
A road-paving crew required 8 hours to repave a 3-mile stretch of road, using \($5,000\) in materials. The crew consisted of three workers who each earn \($25\) an hour. Calculate a multifactor...
-
An automobile assembly plant produced 600 cars during a 5-day workweek. It then produced 500 cars the following week, although it only operated 4 days due to a national holiday. During which week was...

Study smarter with the SolutionInn App