

Consider the decision trees shown in Figures (a) and (b). For each approach described below, you...
Fantastic news! We've Found the answer you've been seeking!
Question:
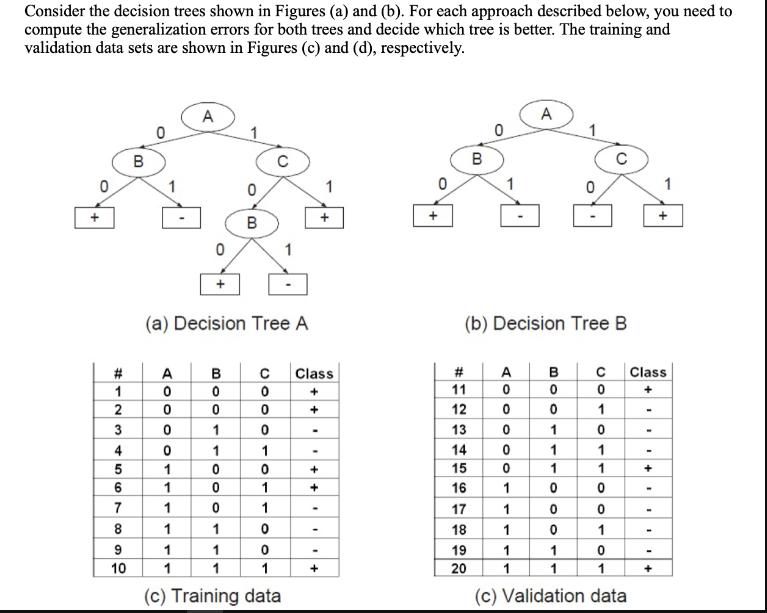

Expert Answer:
To compute the generalization errors for both Decision Tree A and Decision Tree B and decide which tree is better we will apply various approaches as described starting with the optimistic approach an... View the full answer

Related Book For 

Introduction to Data Mining
ISBN: 978-0321321367
1st edition
Authors: Pang Ning Tan, Michael Steinbach, Vipin Kumar
Posted Date:
