

implement the agglomerative hierarchical clustering algorithm. We will implement three different cluster similarity measures: Single link,...
Fantastic news! We've Found the answer you've been seeking!
Question:



Transcribed Image Text:
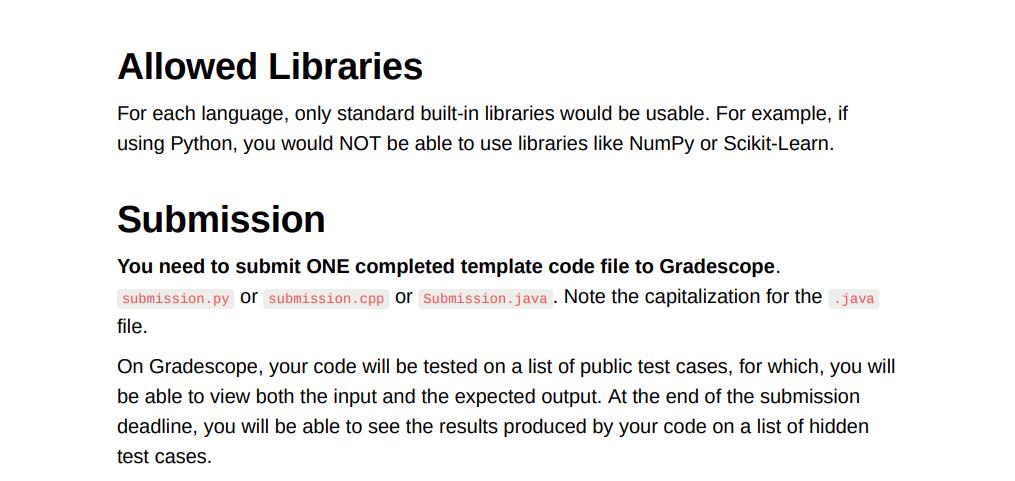
implement the agglomerative hierarchical clustering algorithm. We will implement three different cluster similarity measures: Single link, Complete link, and Average link. We will be using geographical data for this assignment. Each of the data points is a 2D vector, with longitude and latitude as its dimensions. Here is a brief review of agglomerative clustering. During the clustering process, we iteratively aggregate the most similar two clusters until there are K clusters left. For initialization, each data point forms its own cluster. The similarity of two clusters C₁, C'; is determined by a distance measure. We use the following three measures in this assignment: Single link: D(C₁, C;) = min{d(vp, va) | Vp Ci, va € Cj} Complete link: D(C₁, C₂) = max{d(vp, Vg) | Vp € C₁, Vq € Cj} Average link: D(C₁, C;) = mean{d(vp, Vq) | Vp € C₁, Vq € Cj } The smaller the distance is, the more similar the two clusters are. In the equations, d(...) is a distance measure between two data points. In this assignment, for simplicity, we use the Euclidean distance, defined by: In the equations, d(.,.) is a distance measure between two data points. In this assignment, for simplicity, we use the Euclidean distance, defined by: d(p, q) = √i (Pi — qi ) ² where pi, qi are dimensions of p, q. Your task: complete the missing functions in the given programming template files. Programming Assignment: Hierarchical Clustering Programming Template Find in template/ You are allowed to use one of three programming languages for this assignment: Python (3.10), C++ (14), or Java (JDK version 17). You are provided with the template code for each language containing descriptions for the expected input and output for each function that you would have to write. Sample Input and Output Find in sample_test_cases/ To aid your understanding, we have included one test case for each of Single Link, 1 Sample Input and Output Find in sample_test_cases/ To aid your understanding, we have included one test case for each of Single Link, Complete Link, and Average Link clustering within this problem statement. The input format is as follows: The first line of the input contains three space-separated integers N, K, M: 1. N: The number of data points (lines) following the first line. 2. K: The number of output clusters. 3. M: The cluster similarity measure. M = 0 for single link, M = 1 for complete link, M = 2 for average link. Starting from the second line, each line will have exactly two floating point numbers, representing the longitude and latitude of a location. Each line corresponds to a 2D data point which will be fed into the clustering algorithm. Thus, in the input file, there would be N + 1 lines in total. The objective would be to use the similarity measure specified by M to cluster the N data points into K clusters. Note here that the test case format is provided for you to understand the test case files that will be used. For whichever language you use, you would NOT have to read in test cases from STDIN. That will be handled by the grader. You simply need to complete the required functions in the template code file. Test Scale For all public and hidden test cases, N≤ 100, K ≤ 40. Allowed Libraries For each language, only standard built-in libraries would be usable. For example, if using Python, you would NOT be able to use libraries like NumPy or Scikit-Learn. Submission You need to submit ONE completed template code file to Gradescope. submission.py or submission.cpp Or Submission.java. Note the capitalization for the java file. On Gradescope, your code will be tested on a list of public test cases, for which, you will be able to view both the input and the expected output. At the end of the submission deadline, you will be able to see the results produced by your code on a list of hidden test cases. implement the agglomerative hierarchical clustering algorithm. We will implement three different cluster similarity measures: Single link, Complete link, and Average link. We will be using geographical data for this assignment. Each of the data points is a 2D vector, with longitude and latitude as its dimensions. Here is a brief review of agglomerative clustering. During the clustering process, we iteratively aggregate the most similar two clusters until there are K clusters left. For initialization, each data point forms its own cluster. The similarity of two clusters C₁, C'; is determined by a distance measure. We use the following three measures in this assignment: Single link: D(C₁, C;) = min{d(vp, va) | Vp Ci, va € Cj} Complete link: D(C₁, C₂) = max{d(vp, Vg) | Vp € C₁, Vq € Cj} Average link: D(C₁, C;) = mean{d(vp, Vq) | Vp € C₁, Vq € Cj } The smaller the distance is, the more similar the two clusters are. In the equations, d(...) is a distance measure between two data points. In this assignment, for simplicity, we use the Euclidean distance, defined by: In the equations, d(.,.) is a distance measure between two data points. In this assignment, for simplicity, we use the Euclidean distance, defined by: d(p, q) = √i (Pi — qi ) ² where pi, qi are dimensions of p, q. Your task: complete the missing functions in the given programming template files. Programming Assignment: Hierarchical Clustering Programming Template Find in template/ You are allowed to use one of three programming languages for this assignment: Python (3.10), C++ (14), or Java (JDK version 17). You are provided with the template code for each language containing descriptions for the expected input and output for each function that you would have to write. Sample Input and Output Find in sample_test_cases/ To aid your understanding, we have included one test case for each of Single Link, 1 Sample Input and Output Find in sample_test_cases/ To aid your understanding, we have included one test case for each of Single Link, Complete Link, and Average Link clustering within this problem statement. The input format is as follows: The first line of the input contains three space-separated integers N, K, M: 1. N: The number of data points (lines) following the first line. 2. K: The number of output clusters. 3. M: The cluster similarity measure. M = 0 for single link, M = 1 for complete link, M = 2 for average link. Starting from the second line, each line will have exactly two floating point numbers, representing the longitude and latitude of a location. Each line corresponds to a 2D data point which will be fed into the clustering algorithm. Thus, in the input file, there would be N + 1 lines in total. The objective would be to use the similarity measure specified by M to cluster the N data points into K clusters. Note here that the test case format is provided for you to understand the test case files that will be used. For whichever language you use, you would NOT have to read in test cases from STDIN. That will be handled by the grader. You simply need to complete the required functions in the template code file. Test Scale For all public and hidden test cases, N≤ 100, K ≤ 40. Allowed Libraries For each language, only standard built-in libraries would be usable. For example, if using Python, you would NOT be able to use libraries like NumPy or Scikit-Learn. Submission You need to submit ONE completed template code file to Gradescope. submission.py or submission.cpp Or Submission.java. Note the capitalization for the java file. On Gradescope, your code will be tested on a list of public test cases, for which, you will be able to view both the input and the expected output. At the end of the submission deadline, you will be able to see the results produced by your code on a list of hidden test cases.
Expert Answer:
Answer rating: 100% (QA)
To implement the Agglomerative Hierarchical Clustering algorithm with three different cluster similarity measures Single link Complete link and Averag... View the full answer

Related Book For 

Business Analytics Communicating With Numbers
ISBN: 9781260785005
1st Edition
Authors: Sanjiv Jaggia, Alison Kelly, Kevin Lertwachara, Leida Chen
Posted Date:
Students also viewed these programming questions
-
What characteristics would you expect to see in a reader who should be at the emergent and beginning stages of reading?
-
Planning is one of the most important management functions in any business. A front office managers first step in planning should involve determine the departments goals. Planning also includes...
-
Managing Scope Changes Case Study Scope changes on a project can occur regardless of how well the project is planned or executed. Scope changes can be the result of something that was omitted during...
-
Some observers maintain that not all politicians move toward the middle of the political spectrum in order to obtain votes. They often cite Barry Goldwater in the 1964 presidential election and...
-
Accurate Research surveys Canadian opinions. The company's balance sheet reports the following assets under Property, Plant, and Equipment: Land, Buildings, Office Furniture, Communication Equipment,...
-
IZAX, Co. had the following items on its balance sheet at the beginning of the year:Its net income this year is $19,600 and it pays dividends of $5100. If its assets grew at its internal growth rate,...
-
Compute the future value of \($1,000\) continuously compounded for a. 5 years at a stated annual interest rate of 12 percent. b. 3 years at a stated annual interest rate of 10 percent. c. 10 years at...
-
Logan Fruit Drink Company planned to make 200,000 containers of apple juice. It expected to use two cups of frozen apple concentrate to make each container of juice, thus using 400,000 cups of frozen...
-
The weights of adult individuals in a certain country are normally distributed with a population mean of ?=172 pounds and a population standard deviation of ?=29 pounds. Suppose n=36 indivi...
-
Freddy Frolic consumes only asparagus and tomatoes, which are highly seasonal crops in Freddys part of the world. He sells umbrellas for a living, which provides a fluctuating income depending on the...
-
Santana Rey has consulted with her local banker and is consideringfinancing an expansion of her business by obtaining a long-termbank loan. Selected account balances at March 31,2020, for BusinessS...
-
Describe the regulatory mechanisms involved in the activation and suppression of the lac operon in E. coli . How does this model illustrate gene regulation in prokaryotes ?
-
Consider the following items for Wolverine Properties during 2024. 1. On December 1, 2024, Wolverine received $4,000 cash from a company renting office space from Wolverine. The payment, representing...
-
Assume the amount borrowed was $18,600. What was the interest rate if the amount of interest owed was $558? (Round intermediate calculations to 6 decimal places, e.g. 1.251241 and final answer to O...
-
Discuss objectives of an organization's internal control system. Discuss the 5 components of internal control.
-
American Automotive, a national chain of automotive repair shops, acquired all of the outstanding common stock of Southern Parts for $598,000 in cash. The book values and the market values of...
-
(Click on the icon here in order to copy the contents of the data table below into a spreadsheet.) Rounded Depreciation Percentages by Recovery Year Using MACRS for First Four Property Classes...
-
An investor sells a European call on a share for $4. The stock price is $47 and the strike price is $50. Under what circumstances does the investor make a profit? Under what circumstances will the...
-
The accompanying data set contains three predictor variables (x 1 , x 2 , and x 3 ) and the target variable (y). Partition the data to develop a nave Bayes classification model where 1 denotes the...
-
A manufacturing manager uses a dexterity test on 120 current employees in order to predict watch production based on time to completion (in seconds) and a Male dummy variable. A portion of the data...
-
A financial analyst wants to compare the performance of the stocks of two Internet companies, Amazon (AMZN) and Google (GOOG). She records the average closing prices of the two stocks for the years...
-
A companys balance sheet appears as follows: Required: (a) If 10,000 of the ordinary shares were purchased at par, there being no new issue of shares for the purpose, show the journal entries to...
-
Some years ago M plc had issued 375,000 of 10 per cent debentures 2006/2010 at par. The terms of the issue allow the company the right to repurchase these debentures for cancellation at or below par,...
-
Debentures of 30,000 are issued on 1 January 2003. Redemption is to take place, on equal terms, four years later. The company decides to put aside an equal amount to be invested at 5 per cent which...

Study smarter with the SolutionInn App