

Question: Use the data in JTRAIN98 to answer this question. The variable unem98 is a binary variable indicating whether a worker was unemployed in 1998. It
Use the data in JTRAIN98 to answer this question. The variable unem98 is a binary variable indicating whether a worker was unemployed in 1998. It can be used to measure the effectiveness of the job training program in reducing the probability of being unemployed.
(i) What percentage of workers was unemployed in 1998, after the job training program? How does this compare with the unemployment rate in 1996?
(ii) Run the simple regression unem98 on train. How do you interepret the coefficient on train? Is it statistically significant? Does it make sense to you?
(iii) Add to the regression in part (ii) the explanatory variables earn96, educ, age, a n d married. Now interpret the estimated training effect. Why does it differ so much from that in part (ii)?
(iv) Now perform full regression adjustment by running a regression with a full set of interactions, where all variables (except the training indicator) are centered around their sample means:
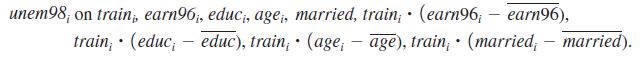
This regression uses all of the data. What ha ppens to the estimated average treatment effect of train compared with part (iii). Does its standard error change much?
(v) Are the interaction terms in part (iv) jointly significant?
(vi) Verify that you obtain exactly the same average treatment effect if you run two separate regressions and use the formula in equation (7.43). That is, run two separate regressions for the control and treated groups, obtain the fitted values unem98i(0) and unem98i(1) for everyone in the sample, and then compute
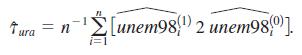
Check this with the coefficient on train in part (iv). Which approach is more convenient for obtaining a standard error?
unem98; on train, earn96;, educ;, age;, married, train; (earn96; - earn96), train, (educ; educ), train, (age, age), train, (married, married).
Step by Step Solution
3.33 Rating (171 Votes )
There are 3 Steps involved in it
i The average value for unem 98 is 0172 The average value for unem 96 is 0312 Thus a much lower frac... View full answer

Get step-by-step solutions from verified subject matter experts