

Question: 1 . Introduction You are given two real datasets which contain individual information in US . In the first real dataset, each individual is associated
Introduction
You are given two real datasets which contain individual information in US In the
first real dataset, each individual is associated with attributes and additional
Boolean attribute called income indicating whether the individual had an income
K per year or not. The second real dataset is the same as the first dataset but the
second one contains only the first attributes but no attribute income The
objective of this project is to predict whether each individual in the second dataset has
an income K or not.
There are three phases in this project Phase Phase and Phase In Phase you
are required to generate an Excel file from two raw files together with attribute names.
In Phase you are required to write a design report for this project. In Phase you
are required to follow the design report in Phase generate the predicted attribute
files for the second real dataset and write a final report
Milestones
Phase
i You are given two real datasets in TEXT format, trainingtxt and testtxt
ii File trainingtxt contains attributes and additional Boolean attribute.
iii. File testtxt contains attributes only.
iv Open these two TEXT files with MS Excel
vSave them in one MS Excel file where the content of trainingtxt is included in Sheet and the content of testtxt is included in Sheet
Please rename Sheet as training and rename Sheet as test in MS Excel.
viInsert a row at the beginning of each of the two sheets of the Excel file where this row gives the attribute names specified in Section
Phase
i In Phase you are required to write a design report for this project.
iiYou should list possible data mining models you want to try
iii.Note that a possible data mining model can be Decision Tree Classifier with a set of parameters and another possible data mining model can be Decision Tree Classifier with another set of parameters. Obviously, one of the possible data mining models can be Nearest Neighbor Classifier with a set of parameters.
Phase
I. In Phase you are required to follow the design report in Phase use the XLMiner software to predict attribute income for the second real dataset and write a final report.
ii The final report should include the following.
a All materials in your design report written in Phase ie the possible data mining models
b Description of the XLMiner results for each of possible data mining models
c Two examples illustrating what attributes determine an individual to have an income K or not for each of possible data mining models.
d Conclusions drawn from each of possible data mining models and an overall conclusion
iii. In addition to the final report, you are required to generate predicted attribute files for the second real dataset in TEXT file format. Note that each predicted attribute file corresponds to the output of a possible data mining model you proposed in Phase The file format is described in
Section
File format of Predicted Attribute File
In Phase you are required to submit predicted attribute files for the second dataset.
The files should be named as predictedtxtpredictedtxtpredictedtxt
predictedtxt and predictedtxt where predictedtxt corresponds to the output
of the first data mining model proposed in Phase and the other files have a similar
meaning. The file format of each file is shown as follows.
st
row: or where corresponds to that the first individual in the second dataset
has an income K and corresponds to that she does not
nd
row: or where corresponds to that the second individual in the second
dataset has an income K and corresponds to that she does not
Here is a sample file.
We have an answer file for the predicted attribute file. Among files given by you,
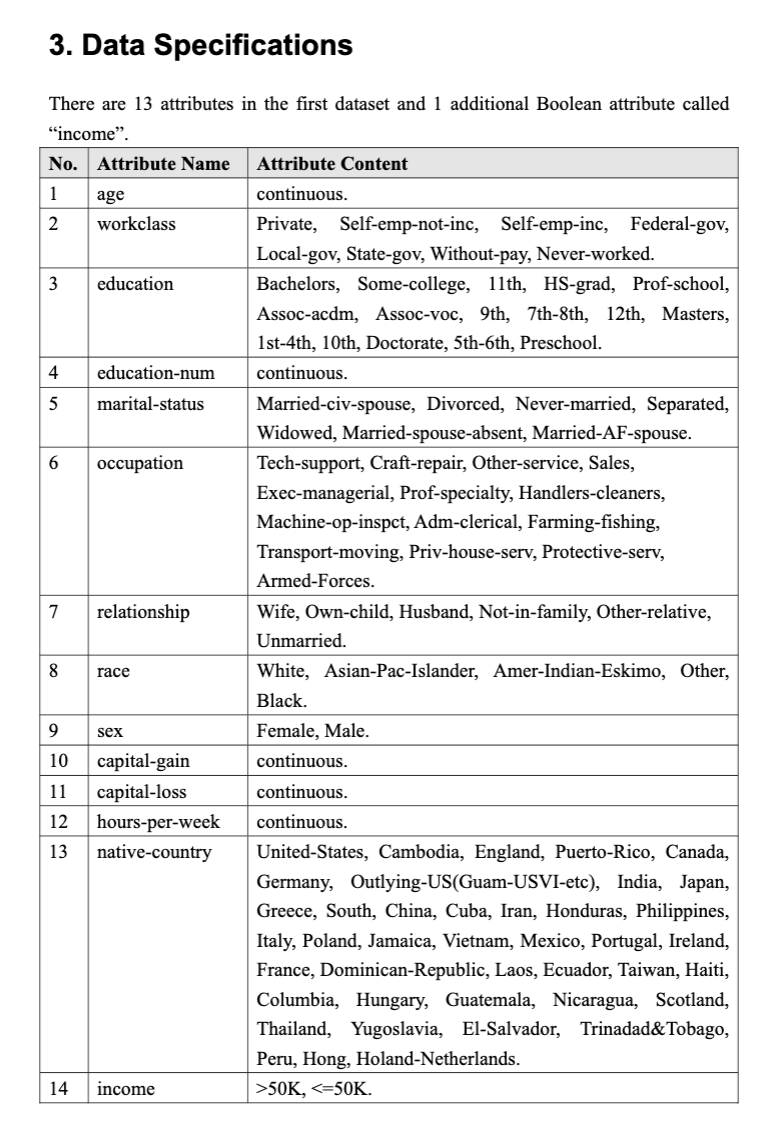
we will select the one with the highest accuracy as the final file for marking.Data Specifications
There are attributes in the first dataset and additional Boolean attribute called
"income".
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock