

Question: 2. 3. 4. Consider a DataFrame named df with columns named P2010, P2011, P2012, P2013, P2014 and P2015 containing float values. We want to use
2.

3.
4.
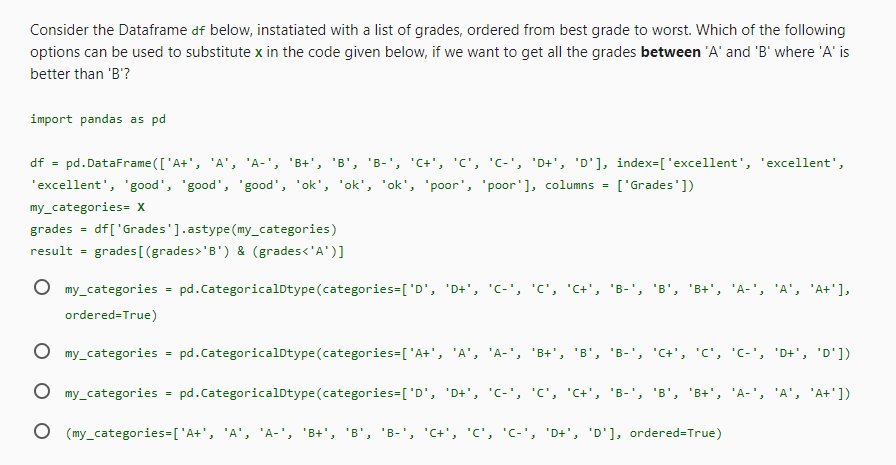
Consider a DataFrame named df with columns named P2010, P2011, P2012, P2013, P2014 and P2015 containing float values. We want to use the apply method to get a new DataFrame named result_df with a new column Avg. The Avg column should average the float values across P2010 to P2015. The apply method should also remove the 6 original columns (P2010 to P2015). For that, what should be the value of x and y in the given code? frames = ['P2010', 'P2011', 'P2012', 'P2013', 'P2014', 'P2015'] df['AVG'] = df[frames ].apply(lambda z: np.mean(z), axis=x) result_df df.drop(frames, axis=y) O X = 1 y = 0 O X = 1 y = 1 O x = 0 y = 1 O x = 0 y = 0 Consider the Dataframe df below, instatiated with a list of grades, ordered from best grade to worst. Which of the following options can be used to substitute x in the code given below, if we want to get all the grades between 'A' and 'B' where 'A' is better than 'B'? import pandas as pd df = pd.DataFrame(['A+', 'A', 'A', 'Bt', 'B', 'B-', 'C+', 'C', 'C', 'D+', 'D'], index=['excellent', 'excellent', 'excellent', 'good', 'good', 'good', 'ok', 'ok', 'ok', 'poor', 'poor'], columns = ['Grades']) my_categories= X grades df ['Grades'].astype (my_categories) result grades [ (grades >'B') & (grades
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts