

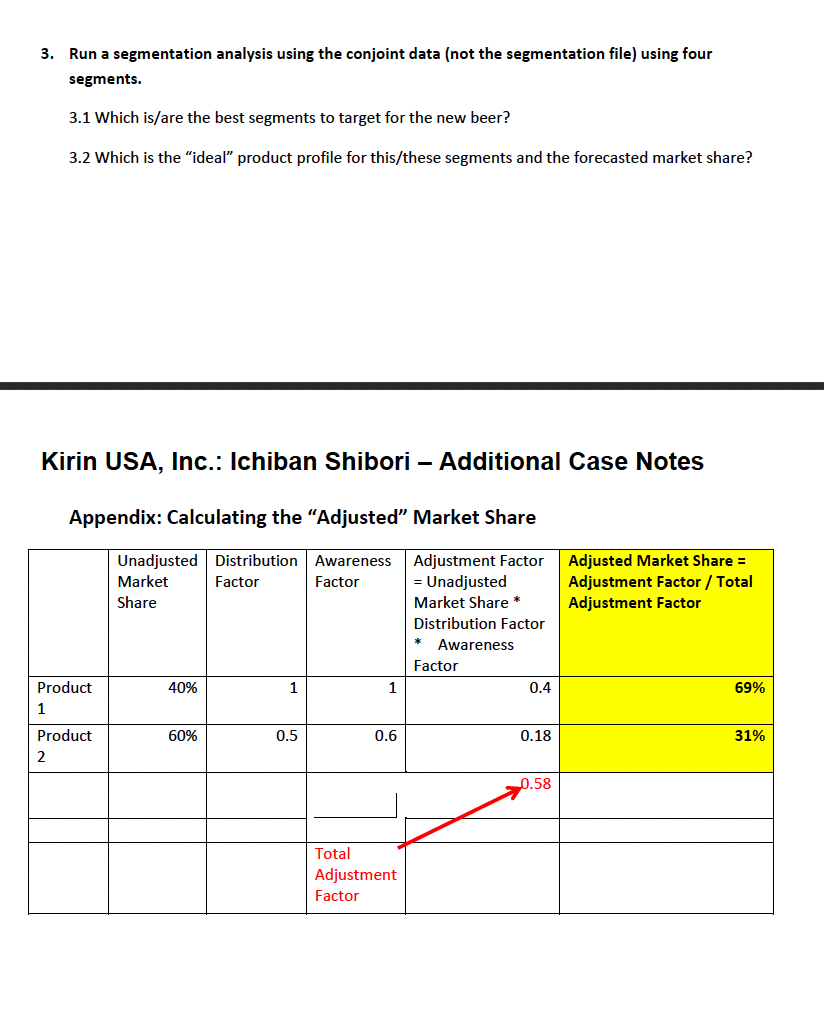
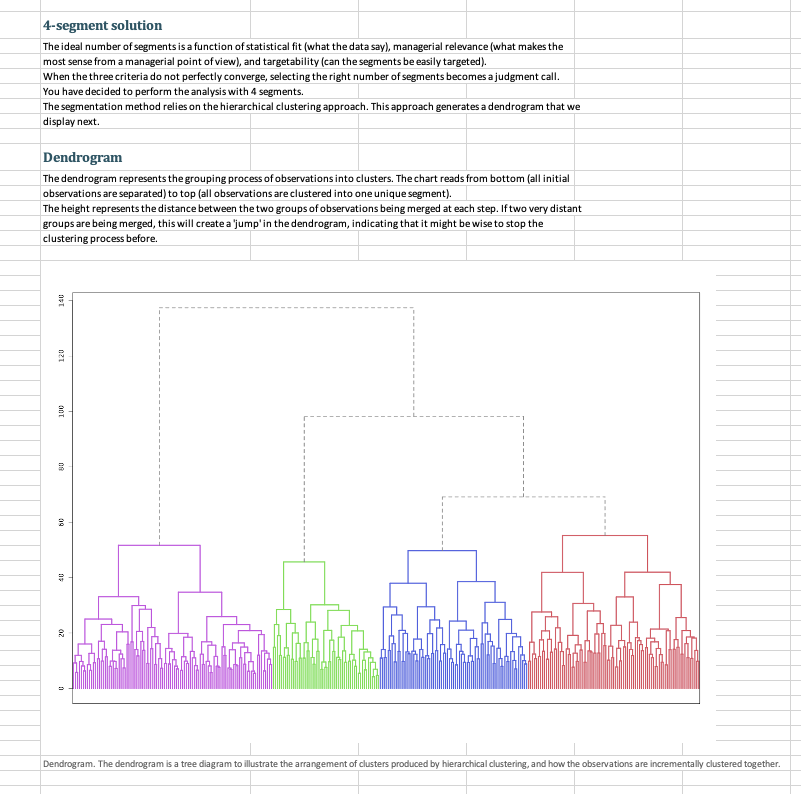
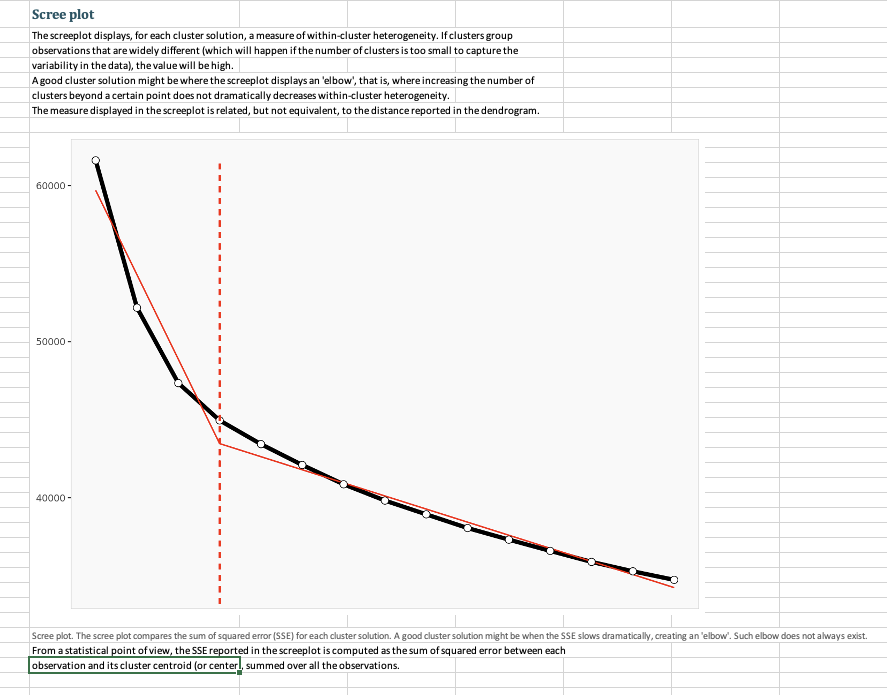
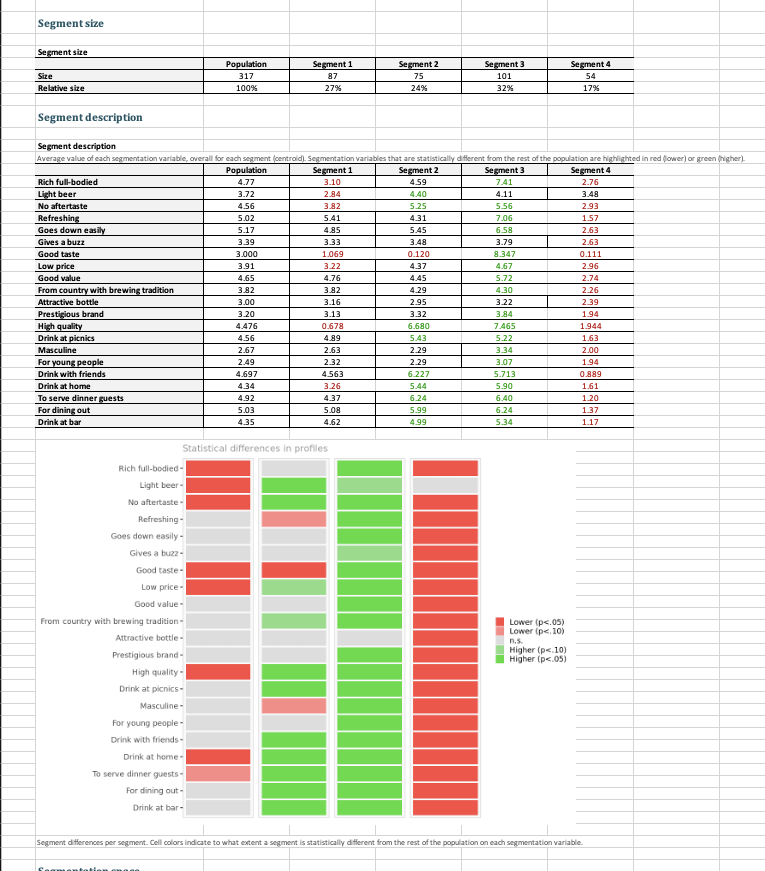
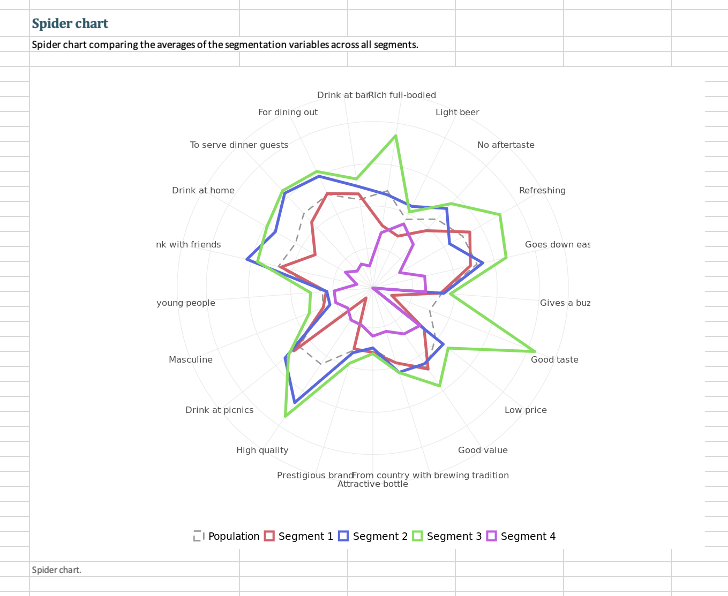
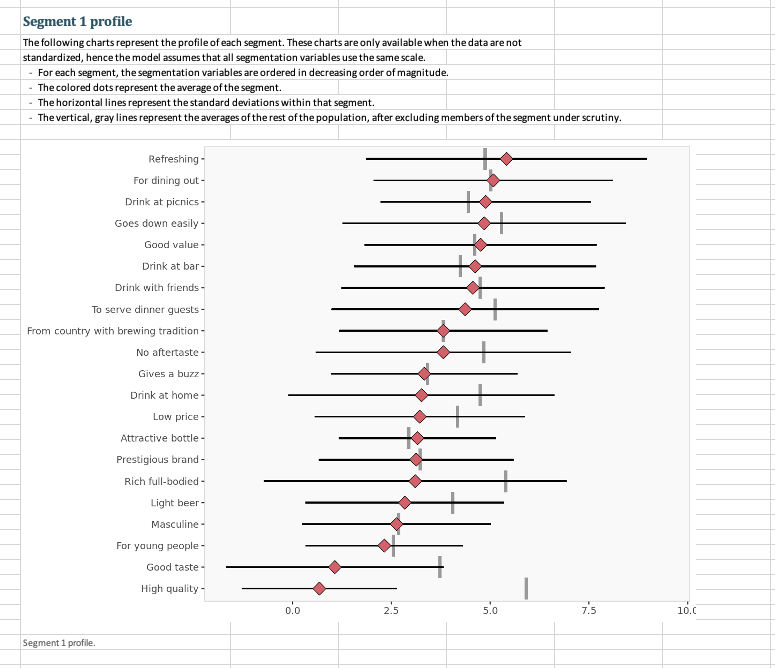
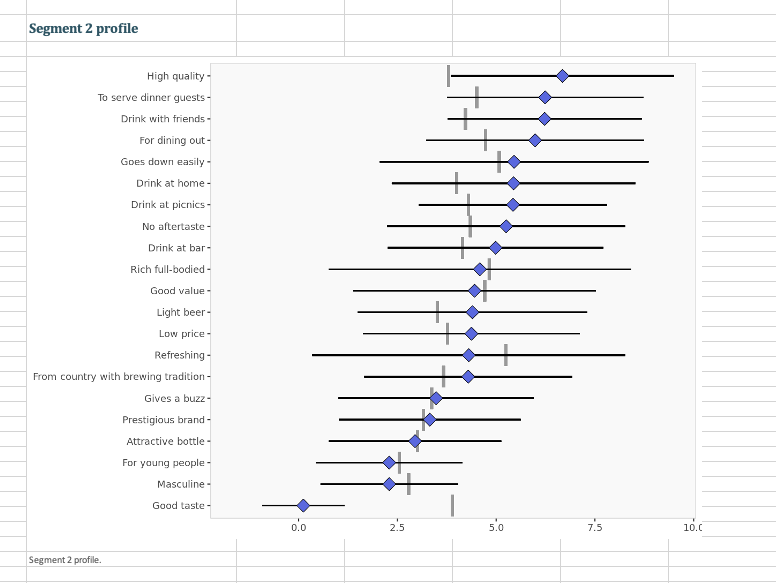
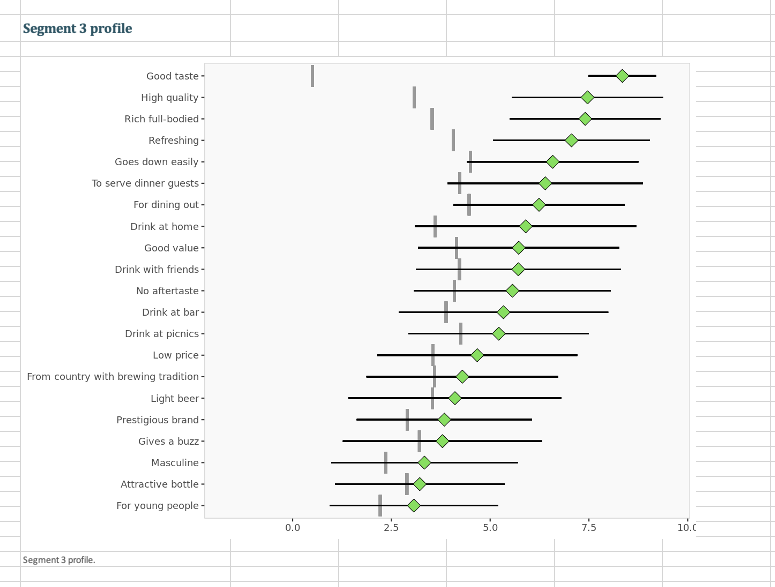
Question: 3. Run a segmentation analysis using the conjoint data (not the segmentation file) using four segments. 3.1 Which is/are the best segments to target for
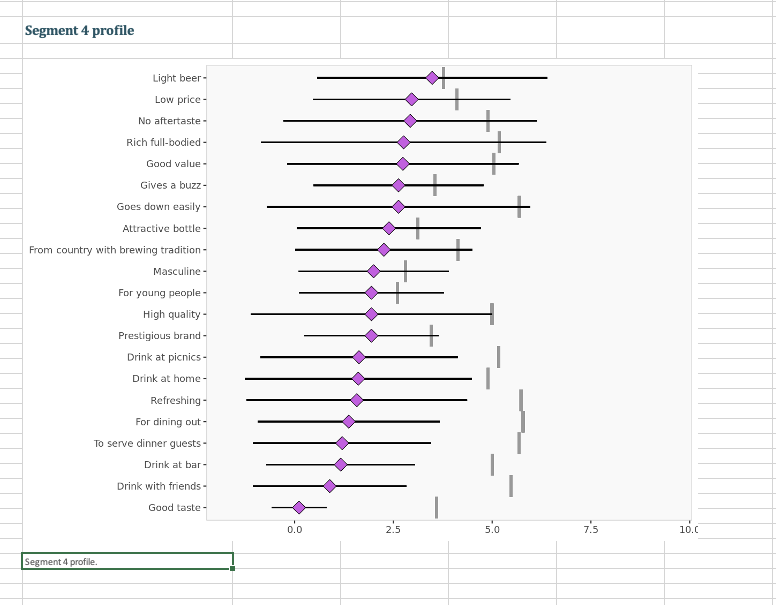
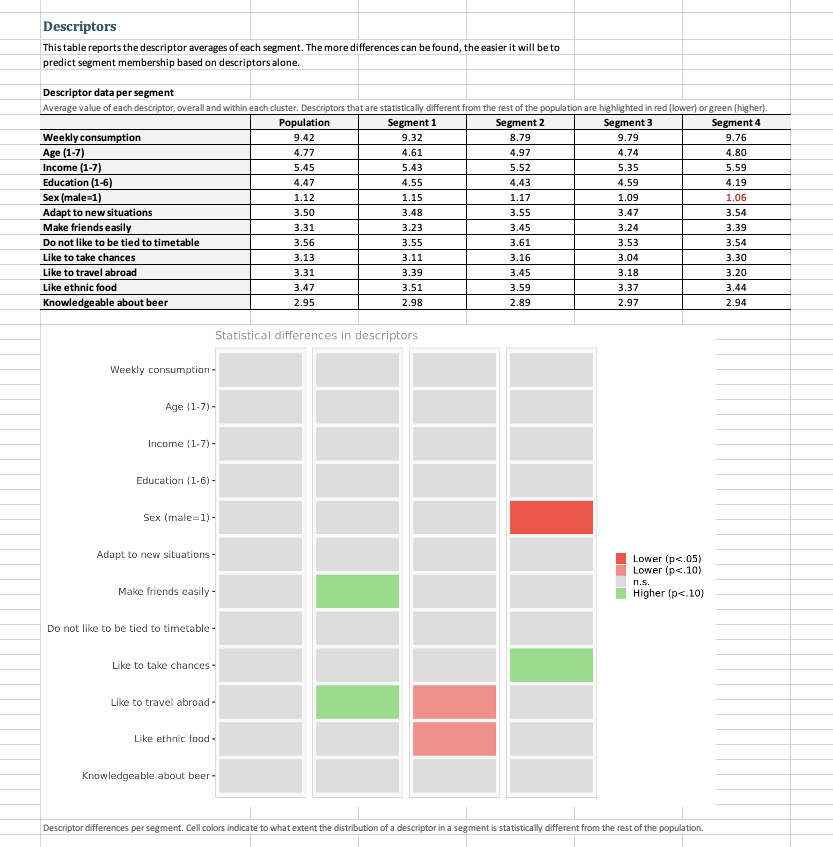
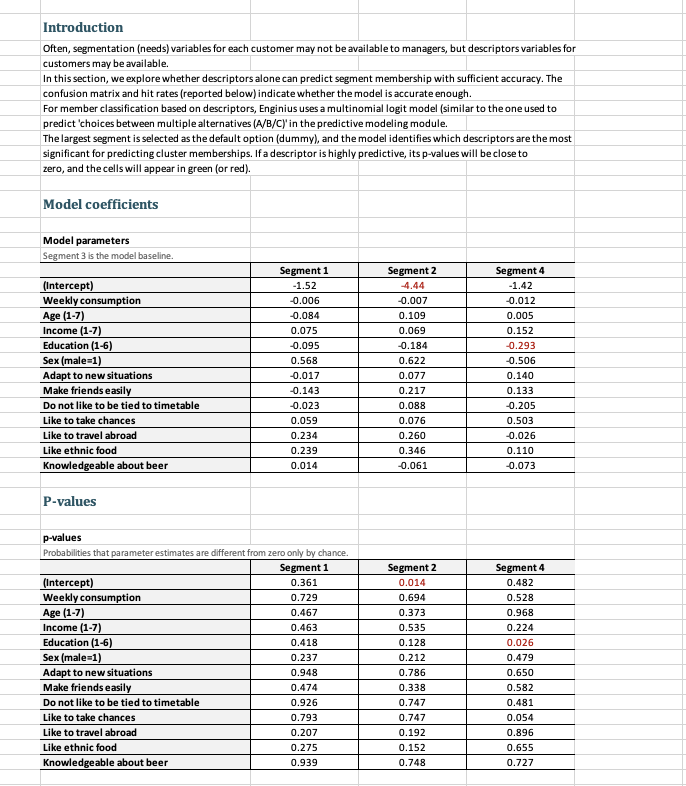
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock