

Question: 4. A good hash function h(1) behaves in practice very close to the simple uniform hash- ing assumption analyzed in class, but is a deterministic


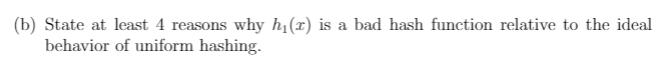


4. A good hash function h(1) behaves in practice very close to the simple uniform hash- ing assumption analyzed in class, but is a deterministic function. Designing good hash functions is hard, and a bad hash function can cause a hash table to quickly exit the sparse loading regime by overloading some buckets and under-loading others. Good hash functions often rely on beautiful and complicated insights from number theory, and have deep connections to pseudorandom number generators and cryptographic functions. In practice, most hash functions are moderate to poor approximations of uniform hashing. Consider the following two hash functions. Let U be the universe of strings composed of the characters from the alphabet = A...,2), and let the function f(1) return the index of a letter I; E , e.g., f(A) = 1 and f(Z) = 26. Letr be a string of length m. (1) The first hash function we consider is hi() = f(1) mode, where l is the number of buckets in the hash table. (2) For the second hash function, first-globally, external to the hash function- choose uniformly random integers a; (one for each I; E ) from 0.....10,000, and then define h2(2) = L eif(1) mod l. List your values of a; here: (and please use consistent values of ; throughout this question) (a) There is a txt file on Canvas that contains US Census derived last names. Using these names as input strings, first choose a uniformly random 50% of these name strings. Letl=5851 be the number of buckets. For each of the two hash functions (separately), produce a histogram showing the distribution of hash locations for the names you chose. Label the axes of your figures. Give a brief description of what the figure shows about him and h2(): justify your results in terms of the behavior of these hash functions. Hint: the raw file includes information other than the name strings, which will need to be removed; and, think about how you can count hash locations without building or using a real hash table. (b) State at least 4 reasons why hi() is a bad hash function relative to the ideal behavior of uniform hashing. (c) Produce two plotsone for each hash function h, he showing the length of the longest chain were we to use chaining for resolving collisions as a function of the number n of these strings that we hash into a table with l = 5851 buckets. That is, you may use the 50% of names from part (a), and as you hash them one by one, show how the length of the longest chain is growing. (d) Produce another pair of plotsone for each of hy, he showing the number of collisions as a function of l. Comment on how collisions decrease as l increases. Aside from size, do you notice any particular kinds of values for that seem better than others? (e.g. odd/even, prime, etc.) Discuss briefly. 4. A good hash function h(1) behaves in practice very close to the simple uniform hash- ing assumption analyzed in class, but is a deterministic function. Designing good hash functions is hard, and a bad hash function can cause a hash table to quickly exit the sparse loading regime by overloading some buckets and under-loading others. Good hash functions often rely on beautiful and complicated insights from number theory, and have deep connections to pseudorandom number generators and cryptographic functions. In practice, most hash functions are moderate to poor approximations of uniform hashing. Consider the following two hash functions. Let U be the universe of strings composed of the characters from the alphabet = A...,2), and let the function f(1) return the index of a letter I; E , e.g., f(A) = 1 and f(Z) = 26. Letr be a string of length m. (1) The first hash function we consider is hi() = f(1) mode, where l is the number of buckets in the hash table. (2) For the second hash function, first-globally, external to the hash function- choose uniformly random integers a; (one for each I; E ) from 0.....10,000, and then define h2(2) = L eif(1) mod l. List your values of a; here: (and please use consistent values of ; throughout this question) (a) There is a txt file on Canvas that contains US Census derived last names. Using these names as input strings, first choose a uniformly random 50% of these name strings. Letl=5851 be the number of buckets. For each of the two hash functions (separately), produce a histogram showing the distribution of hash locations for the names you chose. Label the axes of your figures. Give a brief description of what the figure shows about him and h2(): justify your results in terms of the behavior of these hash functions. Hint: the raw file includes information other than the name strings, which will need to be removed; and, think about how you can count hash locations without building or using a real hash table. (b) State at least 4 reasons why hi() is a bad hash function relative to the ideal behavior of uniform hashing. (c) Produce two plotsone for each hash function h, he showing the length of the longest chain were we to use chaining for resolving collisions as a function of the number n of these strings that we hash into a table with l = 5851 buckets. That is, you may use the 50% of names from part (a), and as you hash them one by one, show how the length of the longest chain is growing. (d) Produce another pair of plotsone for each of hy, he showing the number of collisions as a function of l. Comment on how collisions decrease as l increases. Aside from size, do you notice any particular kinds of values for that seem better than others? (e.g. odd/even, prime, etc.) Discuss briefly
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts