

Question: a ) Suppose you design a multilayer perceptron with a single hidden layer that has a hard threshold activation function. The output layer uses the
a Suppose you design a multilayer perceptron with a single hidden layer that has a hard threshold activation function. The output layer uses the softmax activation function. What will go wrong if you try to train this network using gradient descent?
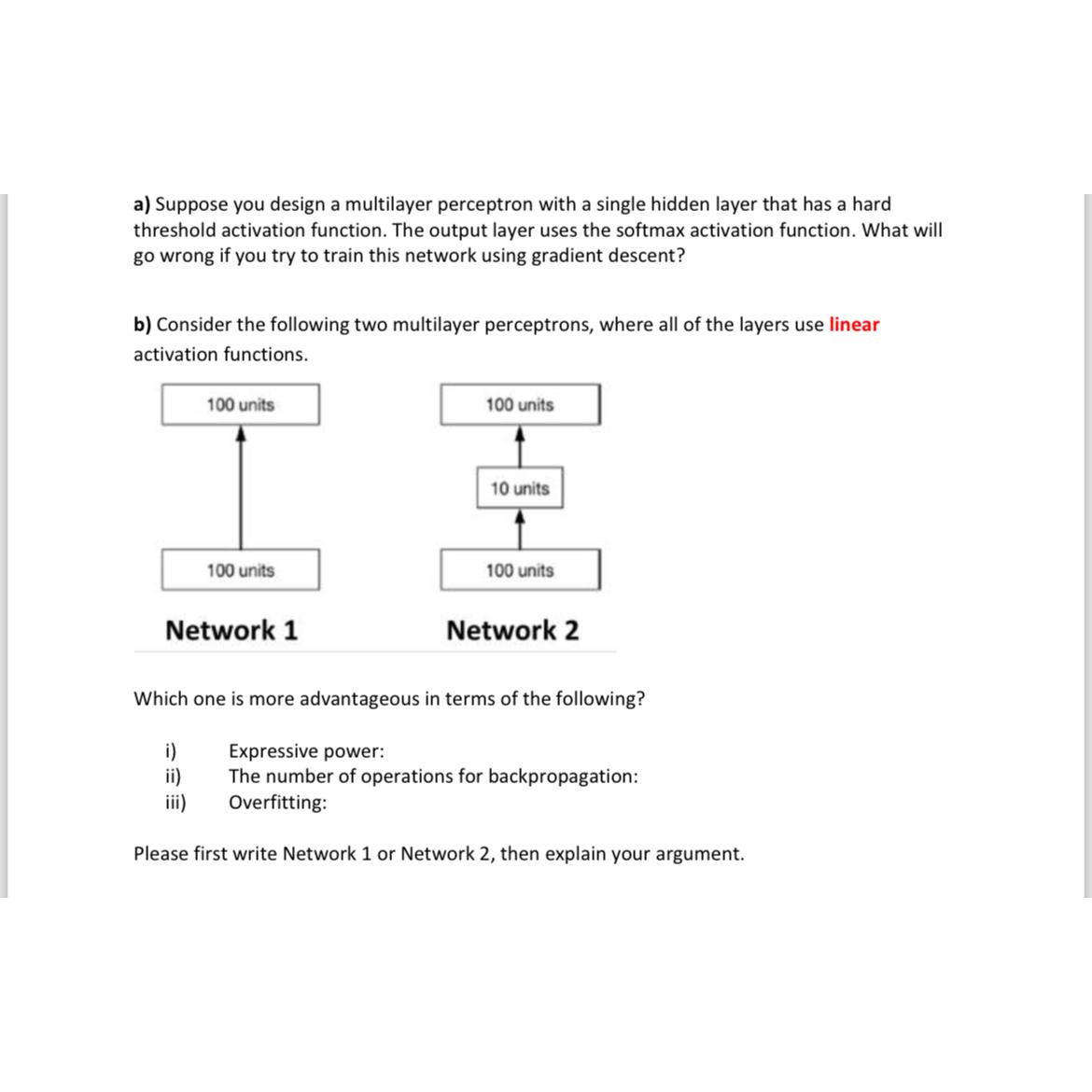
b Consider the following two multilayer perceptrons, where all of the layers use linear activation functions.
Which one is more advantageous in terms of the following?
i Expressive power:
ii The number of operations for backpropagation:
iii Overfitting:
Please first write Network or Network then explain your argument.
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock