

Question: /** A2.input **/ /** keywords (such as read and if) and identifiers should not be counted in * comments. * Comments can be longer than
/** A2.input **/
/** keywords (such as read and if) and identifiers should not be counted in * comments. * Comments can be longer than one line. **/ MAIN f() BEGIN you are not required to check the syntax of the program; so all these words are identifiers; except "quoted" strings and keywords; to check how many lines and words I have; type "wc A2.input" in "luna.cs"; your number of characters and lines may vary from sample output, depends on how you save this file; to count the identifers and keywords; you have to count me one by one; note that A1_A2 is not ONE identifier; as defined in the language lexicon specification; A1 and A2 should returned as two identifiers; special characters such as !@#$% and tab may also appear to test your program; both 123 and 123.45 are numbers; while 12,34 are two numbers; /** you can put more than one comment line with characters like * and ) **/ here is some more tricky part: " /** this is a quoted string **/ " but /** "this is a comment " **/ END
/** end of A2.input **/
/** A2.output **/
identifiers: 116 keywords: 3 numbers: 4 comments: 3 quotedString: 4
/** End of A2.output **/
/** how to answer **/
// import the classes needed %% %{ // internal code such as variable declararions to be used in RE section public static void main(String argv[]) throws java.io.IOException { A2 yy = new A2(new FileInputStream(new File("A2.input"))); //add code for scanning //create the a file writer //the following write the counters to the file. fw.write("keywords: "+new Integer(k).toString()+" "); // write other things fw.close(); } %} //add some directives here %% // write your regular expressions and the actions (counting)
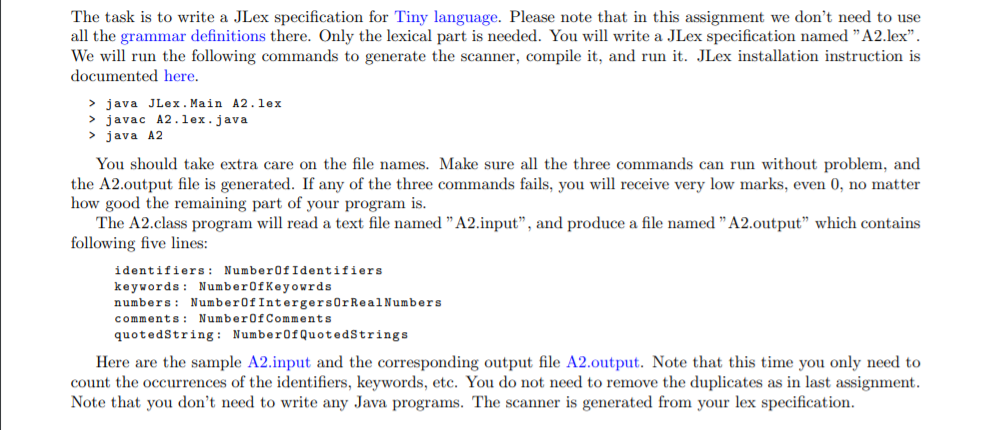
The task is to write a JLex specification for Tiny language. Please note that in this assignment we don't need to use all the grammar definitions there. Only the lexical part is needed. You will write a JLex specification named "A2.lex". We will run the following commands to generate the scanner, compile it, and run it. JLex installation instruction is documented here. > java JLex. Main A2.lex > javac A2.lex.java > java A2 You should take extra care on the file names. Make sure all the three commands can run without problem, and the A2.output file is generated. If any of the three commands fails, you will receive very low marks, even 0, no matter how good the remaining part of your program is. The A2.class program will read a text file named "A2.input, and produce a file named "A2.output which contains following five lines: identifiers : NumberOf Identifiers keywords : Number of Keyourds numbers: NumberOf Intergers Or Real Numbers comments: Number of Comments quotedString: NumberOfQuotedStrings Here are the sample A2.input and the corresponding output file A2.output. Note that this time you only need to count the occurrences of the identifiers, keywords, etc. You do not need to remove the duplicates as in last assignment. Note that you don't need to write any Java programs. The scanner is generated from your lex specification. The task is to write a JLex specification for Tiny language. Please note that in this assignment we don't need to use all the grammar definitions there. Only the lexical part is needed. You will write a JLex specification named "A2.lex". We will run the following commands to generate the scanner, compile it, and run it. JLex installation instruction is documented here. > java JLex. Main A2.lex > javac A2.lex.java > java A2 You should take extra care on the file names. Make sure all the three commands can run without problem, and the A2.output file is generated. If any of the three commands fails, you will receive very low marks, even 0, no matter how good the remaining part of your program is. The A2.class program will read a text file named "A2.input, and produce a file named "A2.output which contains following five lines: identifiers : NumberOf Identifiers keywords : Number of Keyourds numbers: NumberOf Intergers Or Real Numbers comments: Number of Comments quotedString: NumberOfQuotedStrings Here are the sample A2.input and the corresponding output file A2.output. Note that this time you only need to count the occurrences of the identifiers, keywords, etc. You do not need to remove the duplicates as in last assignment. Note that you don't need to write any Java programs. The scanner is generated from your lex specification
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts