

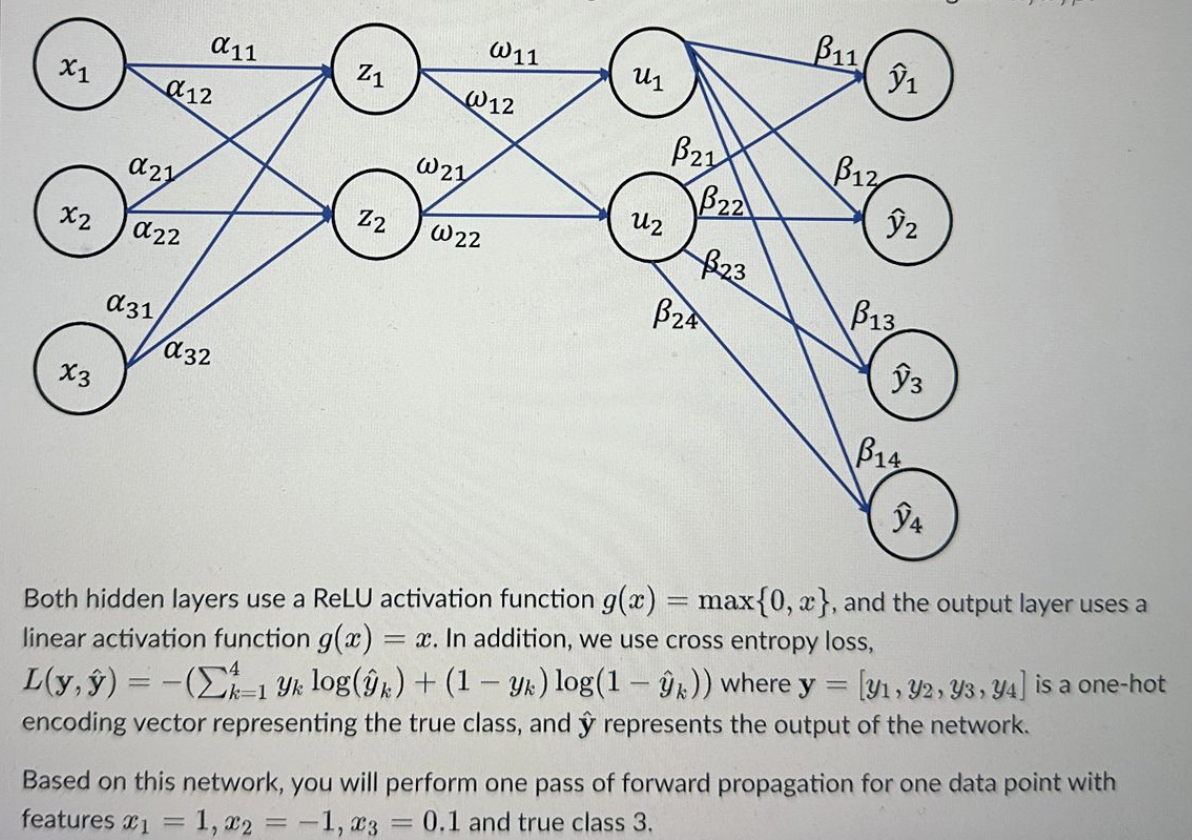
Question: Both hidden layers use a ReLU activation function g ( x ) = max { 0 , x } , and the output layer uses
Both hidden layers use a ReLU activation function max and the output layer uses a
linear activation function In addition, we use cross entropy loss,
hathat where is a onehot
encoding vector representing the true class, and hat represents the output of the network.
Based on this network, you will perform one pass of forward propagation for one data point with
features and true class
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock