

Question: Can I get help fixing, completing my python code? Our program will open and read the urls contained in the file, and it will report
Can I get help fixing, completing my python code?
Our program will open and read the urls contained in the file, and it will report back on the subset of urls that contain a reference to the specified topic.
I have included comments.
#------------------------------------------
sources.txt file:
http://web.archive.org/web/20180307004551/https://foothill.eduews/ http://web.archive.org/web/20151030182314/https://www.deanza.eduews/ http://web.archive.org/web/20151030182406/http://blogs.sjsu.eduewsroom/ http://web.archive.org/web/20151030182501/http:/ews.stanford.edu/ http://invalidurlurlcs21a.com/ http://web.archive.org/web/20151030182547/http:/ews.berkeley.edu/ http://web.archive.org/web/20151030182644/http://www.scu.edu/scunews/ http://web.archive.org/web/20151030172714/http:/ews.ucsc.edu/ http://web.archive.org/web/20151030183138/http://www.news.ucsb.edu/ http://web.archive.org/web/20151030183532/http://ucsdnews.ucsd.edu/ http://www.deanza.edu/counseling/documents/Substitution%20Petition.pdf
#------------------------------
EXAMPLE output
artsummary.txt file:
Source url:
http://web.archive.org/web/20151030182314/https://www.deanza.eduews/
Euphrat Museum of Art
Chain link fence art installation explores civil liberties issues
Euphrat Museum of Art exhibition features two student projects
Source url:
http://web.archive.org/web/20151030183138/http://www.news.ucsb.edu/
Recent acquisitions by the Art, Design & Architecture Museum explore
narratives of art and architecture
art
--------------
Test case 1:
python aggregator.py sources.txt art
The following error messages should be generated:
Error opening url: http://invalidurlurlcs21a.com/
Error decoding url: http://www.deanza.edu/counseling/documents/Substitution%20Petition.pdf 'utf-8' codec can't decode byte 0xc4 in position 10: invalid continuation byte
The output file (artsummary.txt) should match the file artsummary.txt .
.
Make sure you pick up references to Art and art and make sure you do NOT pick up the reference to arts.
Make sure you pick up the reference to Art when it is followed by punctuation as in: Recent acquisitions by the Art, Design...
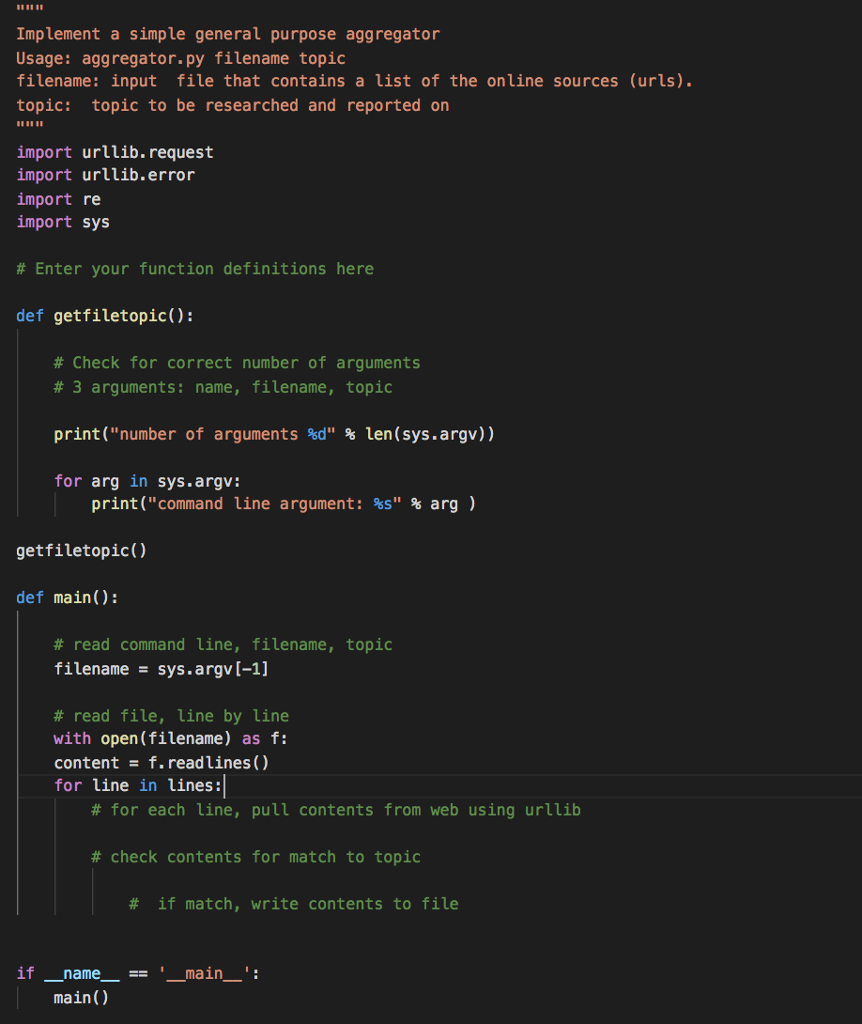
ImpLement a simple general purpose aggregator Usage: aggregator.py filename topic filename: input file that contains a list of the online sources (urls). topic: topic to be researched and reported on import urllib.request import urllib.error import re import sys # Enter your function definitions here def getfiletopic): # Check for correct number of arguments #3 arguments: name, filename, topic print( "number of arguments %d" len (sys.argv)) for arg in sys.argv: print( "command line argument: %s" % arg ) getfiletopic) def main): # read command ine, flename, topic filenamesys.argv[-1] # read file, line by line with open (filename) as f: contentf.readlines() for line in lines: # for each line, pull contents from web using urllib # check contents for match to topic # if match, write contents to file if-name?== ' main-' : main() ImpLement a simple general purpose aggregator Usage: aggregator.py filename topic filename: input file that contains a list of the online sources (urls). topic: topic to be researched and reported on import urllib.request import urllib.error import re import sys # Enter your function definitions here def getfiletopic): # Check for correct number of arguments #3 arguments: name, filename, topic print( "number of arguments %d" len (sys.argv)) for arg in sys.argv: print( "command line argument: %s" % arg ) getfiletopic) def main): # read command ine, flename, topic filenamesys.argv[-1] # read file, line by line with open (filename) as f: contentf.readlines() for line in lines: # for each line, pull contents from web using urllib # check contents for match to topic # if match, write contents to file if-name?== ' main-' : main()
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts