

Question: Compare and contrast Apache Spark with MapReduce. List each features, advantages, disadvantages. What are the important components of Apache Spark ecosystem? Why the transformations are
Compare and contrast Apache Spark with MapReduce. List each features, advantages, disadvantages.
What are the important components of Apache Spark ecosystem?
Why the transformations are lazy in Apache Spark? Using marks.csv file, create a Spark DataFrame.
Explicitly define name as StringType and marks as FloatType. Show the initial and final output of printSchema().
Explain withColumn() and withColumnRenamed() with the help of sample data and PySpark code.
Using SparkSession, select and print only the marks column from marks.csv.
Using SparkSession, collect and print only the name of fourth student from marks.csv.
For all the names in marks.csv, append LNU (Last Name Unknown) to the name yield and print the output. Sample Output:
Explain the difference between show() and collect() with the help of sample data and PySpark code.
For marks.csv, create a new column called scaled_marks defined as 1.2 times of original marks and print the output.
marks.csv file:
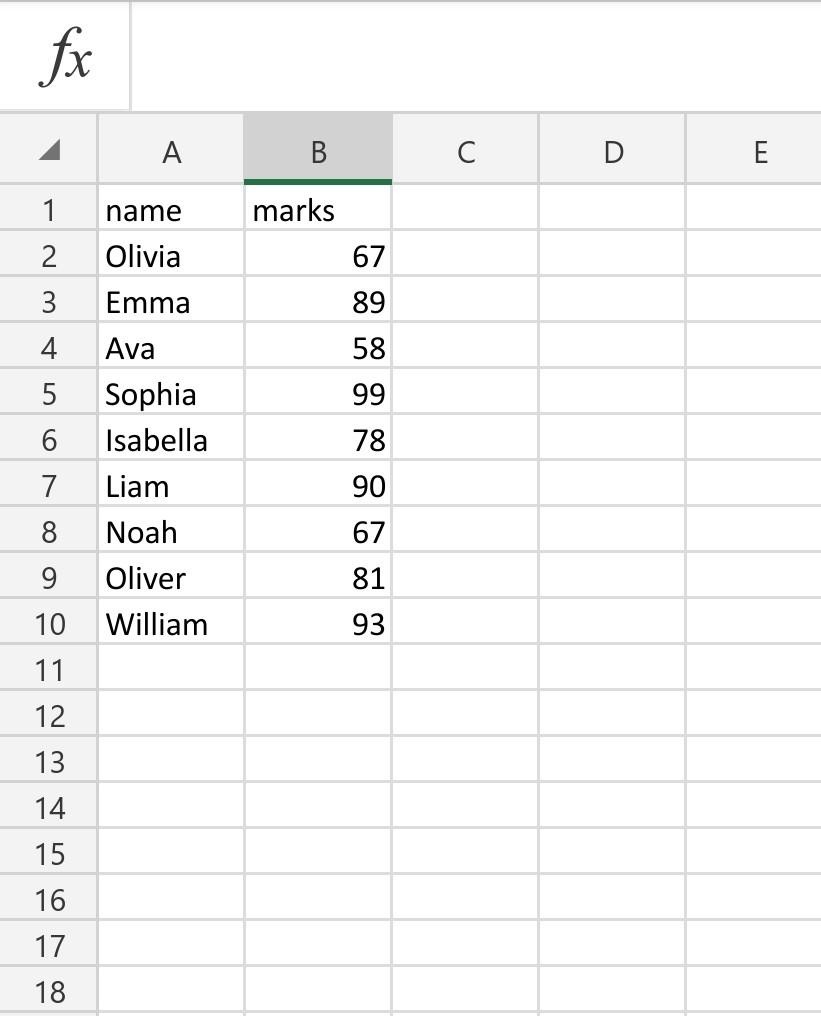
fx A B D E name marks 67 1 2 3 4 Olivia Emma 89 Ava 58 5 99 6 78 90 7 Sophia Isabella Liam Noah Oliver William 8 67 81 9 10 93 11 12 13 14 15 16 17 18
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts