

Question: Consider a labeled data set containing 100 data instances, which is randomly partitioned into two sets A and B, each containing 50 instances. We use
Consider a labeled data set containing 100 data instances, which is randomly partitioned into two sets A and B, each containing 50 instances. We use A as the training set to learn two decision trees, T10 with 10 leaf nodes and T100 with 100 leaf nodes. The accuracies of the two decision trees on data sets A and B are shown in Table 3.7.
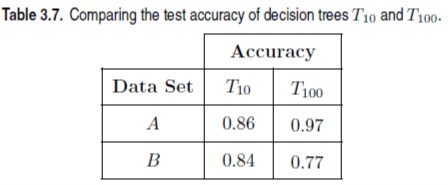 (a) Based on the accuracies shown in Table 3.7, which classification model would you expect to have better performance on unseen instances? (b) Now, you tested T10 and T100 on the entire data set (A + B) and found that the classification accuracy of T10 on data set (A+B) is 0.85, whereas the classification accuracy of T100 on the data set (A + B) is 0.87. Based on this new information and your observations from Table 3.7, which classification model would you finally choose for classification?
(a) Based on the accuracies shown in Table 3.7, which classification model would you expect to have better performance on unseen instances? (b) Now, you tested T10 and T100 on the entire data set (A + B) and found that the classification accuracy of T10 on data set (A+B) is 0.85, whereas the classification accuracy of T100 on the data set (A + B) is 0.87. Based on this new information and your observations from Table 3.7, which classification model would you finally choose for classification?
Table 3.7. Comparing the test accuracy of decision trees Tio and T1oo. Accuracy Data SetTioTioo 100 0.86 0.97 0.84 0.77
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts