

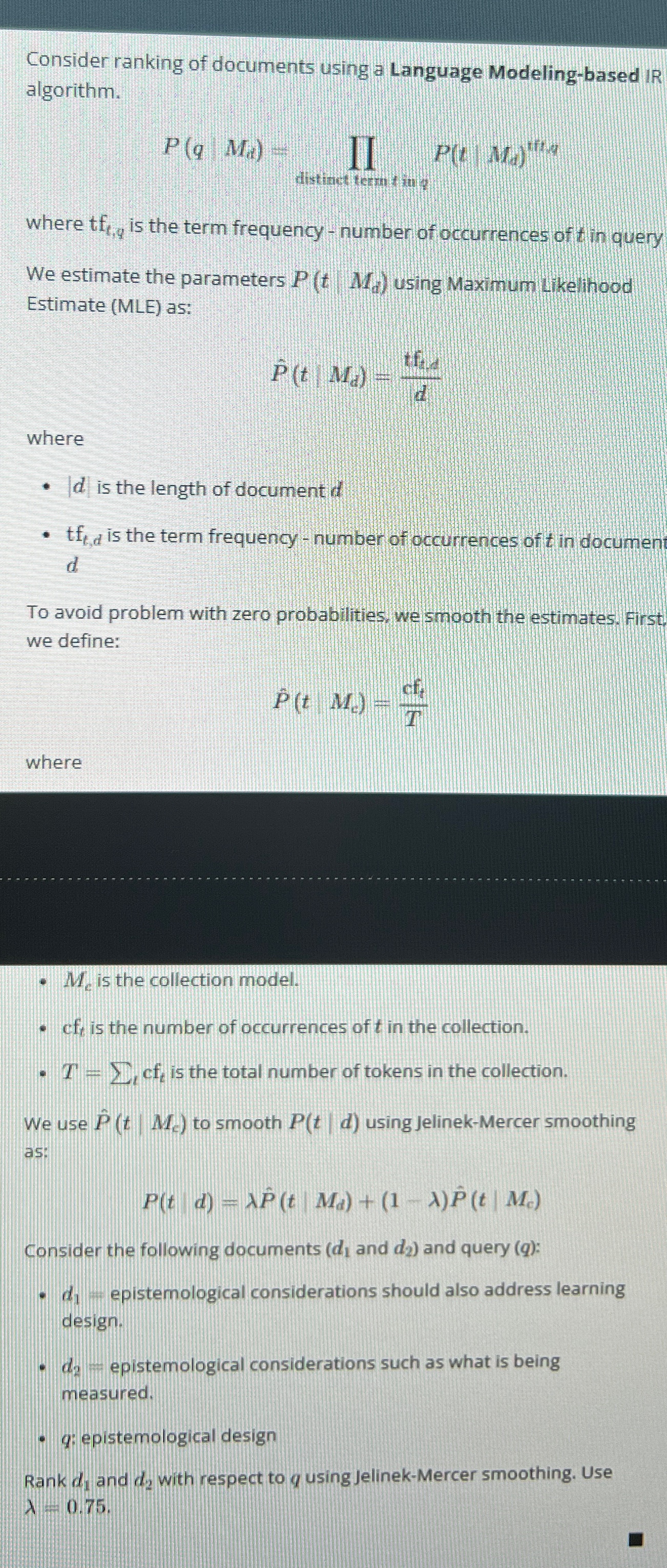
Question: Consider ranking of documents using a Language Modeling - based IR algorithm. P ( q , M d ) = p r o d d
Consider ranking of documents using a Language Modelingbased IR algorithm.
where is the term frequency number of occurrences of in query
We estimate the parameters using Maximum Likelihood Estimate MLE as:
where
is the length of document
is the term frequency number of occurrences of in documen d
To avoid problem with zero probabilities, we smooth the estimates. First, we define:
where
is the collection model.
is the number of occurrences of in the collection.
is the total number of tokens in the collection.
We use to smooth using JelinekMercer smoothing as:
Consider the following documents and and query :
epistemological considerations should also address learning design.
epistemological considerations such as what is being measured.
: epistemological design
Rank and with respect to using JelinekMercer smoothing. Use
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock