

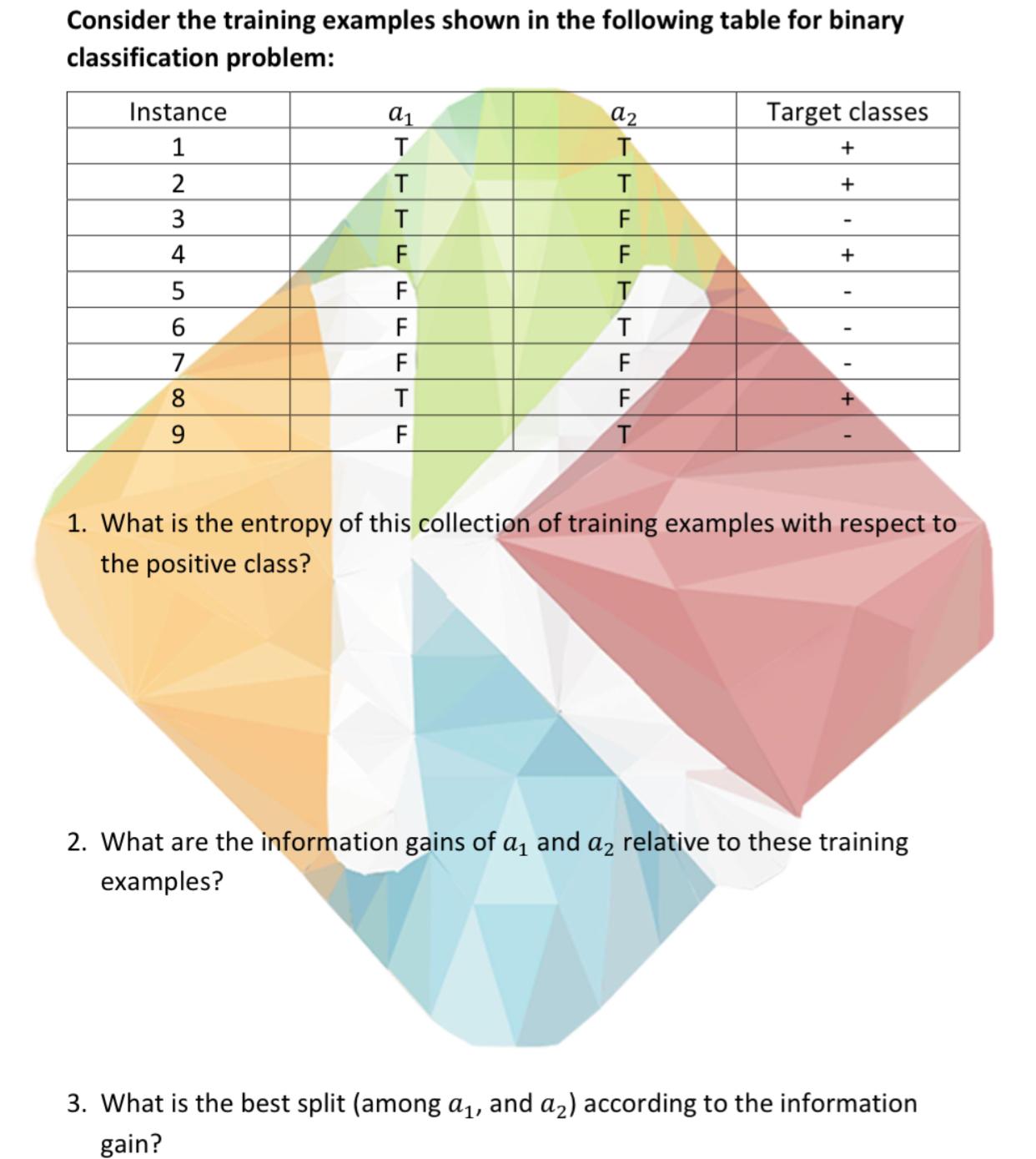
Question: Consider the training examples shown in the following table for binary classification problem: table [ [ Instance , a 1 , a 2 ,
Consider the training examples shown in the following table for binary classification problem:
tableInstanceTarget classes
What is the entropy of this collection of training examples with respect to the positive class?
What are the information gains of and relative to these training examples?
What is the best split among and according to the information gain?
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock