

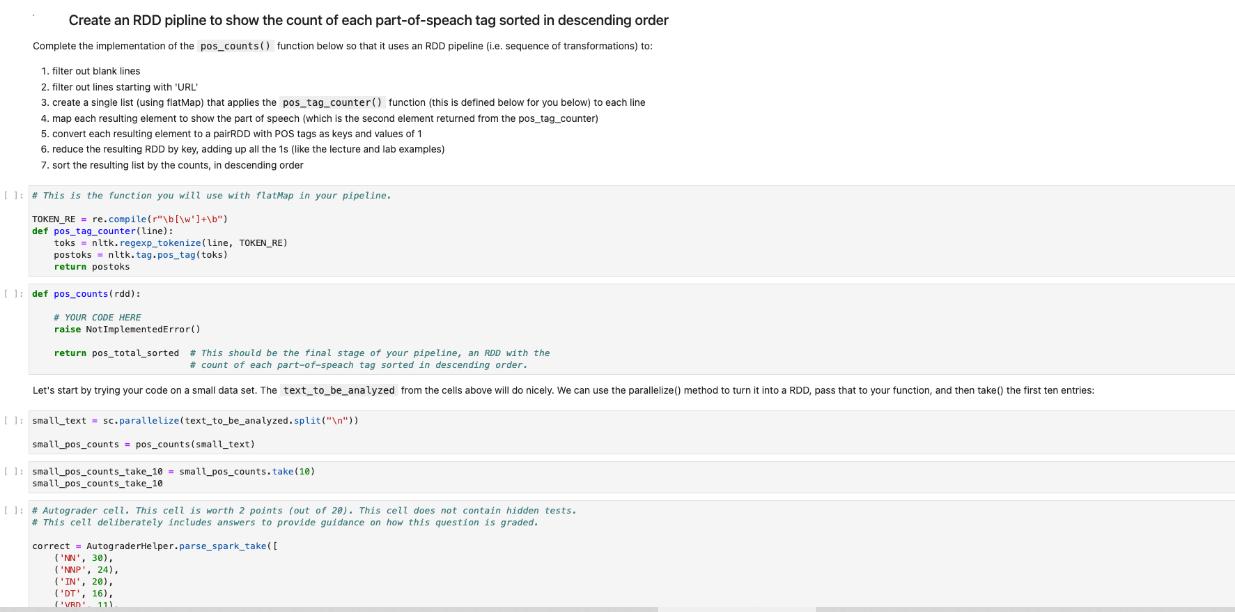
Create an RDD pipline to show the count of each part-of-speach tag sorted in descending order...
Fantastic news! We've Found the answer you've been seeking!
Question:
Transcribed Image Text:
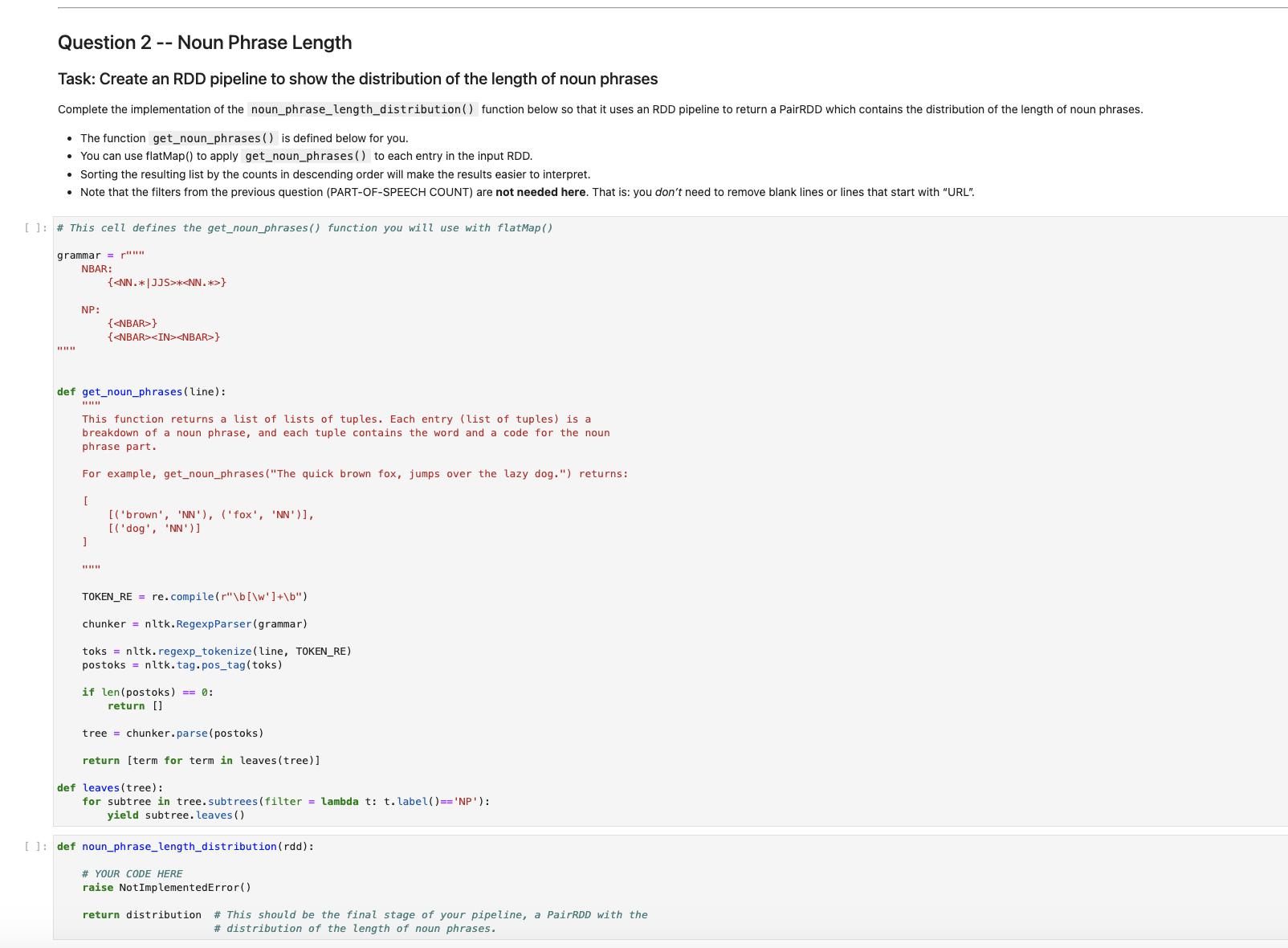
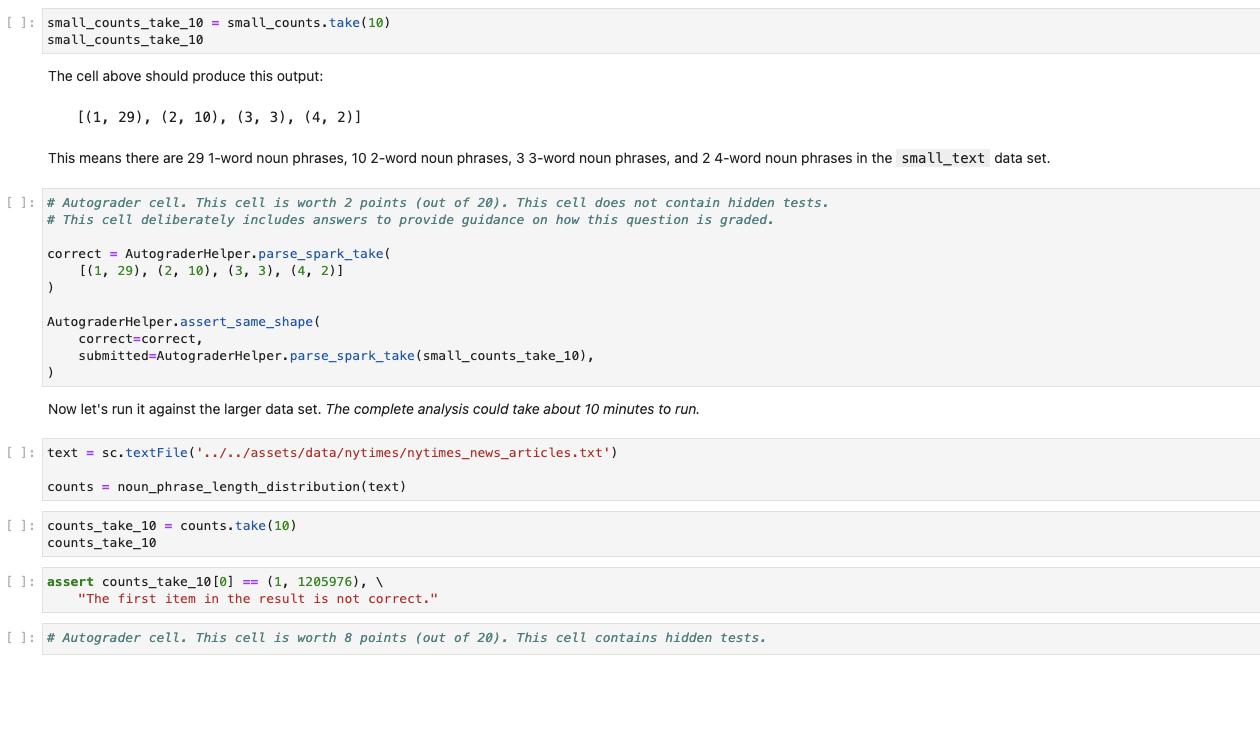
Create an RDD pipline to show the count of each part-of-speach tag sorted in descending order Complete the implementation of the pos_counts() function below so that it uses an RDD pipeline (i.e. sequence of transformations) to: 1. filter out blank lines 2. filter outlines starting with "URL" 3. create a single list (using flatMap) that applies the pos_tag_counter() function (this is defined below for you below) to each line 4. map each resulting element to show the part of speech (which is the second element returned from the pos_tag_counter) 5. convert each resulting element to a pairRDD with POS tags as keys and values of 1 6. reduce the resulting RDD by key, adding up all the 1s (like the lecture and lab examples) 7. sort the resulting list by the counts, in descending order 11:# This is the function you will use with flatMap in your pipeline. TOKEN_RE = re.compile(r"\b[\w]+\b") def pos_tag_counter(line): toks = nltk.regexp_tokenize (line, TOKEN_RE) postoks nltk.tag.pos_tag(toks) return postoks [1: def pos_counts (rdd): # YOUR CODE HERE raise Not ImplementedError() return pos_total_sorted # This should be the final stage of your pipeline, an RDD with the # count of each part-of-speach tag sorted in descending order. Let's start by trying your code on a small data set. The text_to_be_analyzed from the cells above will do nicely. We can use the parallelize() method to turn it into a RDD, pass that to your function, and then take() the first ten entries: II:small_text= sc.parallelize (text_to_be_analyzed.split("\n")) small_pos_counts = pos_counts (small_text) 11: small_pos_counts_take_10= small_pos_counts.take (10) small_pos_counts_take_10 11: # Autograder cell. This cell is worth 2 points (out of 280). This cell does not contain hidden tests. # This cell deliberately includes answers to provide guidance on how this question is graded. correct = AutograderHelper.parse_spark_take([ ('NN', 30), ('NNP', 24), ('IN', 20), ('DT', 16), (VRD 11) Question 2 -- Noun Phrase Length Task: Create an RDD pipeline to show the distribution of the length of noun phrases Complete the implementation of the noun_phrase_length_distribution () function below so that it uses an RDD pipeline to return a PairRDD which contains the distribution of the length of noun phrases. • The function get_noun_phrases () is defined below for you. • You can use flat Map() to apply get_noun_phrases () to each entry in the input RDD. • Sorting the resulting list by the counts in descending order will make the results easier to interpret. • Note that the filters from the previous question (PART-OF-SPEECH COUNT) are not needed here. That is: you don't need to remove blank lines or lines that start with "URL". [ ]: # This cell defines the get_noun_phrases() function you will use with flatMap() grammar="" NBAR: ww NP: *** ] {<NN.*|JJS>*<NN.*>} def get_noun_phrases (line): This function returns a list of lists of tuples. Each entry (list of tuples) is a breakdown of a noun phrase, and each tuple contains the word and a code for the noun phrase part. For example, get_noun_phrases ("The quick brown fox, jumps over the lazy dog.") returns: [ www {<NBAR>} {<NBAR><IN><NBAR>} [('brown', 'NN'), ('fox', 'NN')], [('dog', 'NN')] TOKEN_RE= re.compile(r"\b[\w']+\b") chunker nltk.RegexpParser (grammar) toks = nltk. regexp_tokenize (line, TOKEN_RE) postoks nltk. tag.pos_tag (toks) if len(postoks) == 0: return [] tree chunker.parse(postoks) return [term for term in leaves (tree)] def leaves (tree): for subtree in tree. subtrees(filter = lambda t: t. label()== 'NP') : yield subtree. leaves () []: def noun_phrase_length_distribution (rdd): # YOUR CODE HERE raise NotImplementedError() return distribution # This should be the final stage of your pipeline, a PairRDD with the # distribution of the length of noun phrases. [ ]:small_counts_take_10=small_counts.take (10) small_counts_take_10 The cell above should produce this output: This means there are 29 1-word noun phrases, 10 2-word noun phrases, 3 3-word noun phrases, and 2 4-word noun phrases in the small_text data set. [(1, 29), (2, 10), (3, 3), (4, 2)] [ ]: # Autograder cell. This cell is worth 2 points (out of 20). This cell does not contain hidden tests. # This cell deliberately includes answers to provide guidance on how this question is graded. correct AutograderHelper.parse_spark_take( [(1, 29), (2, 10), (3, 3), (4, 2)] ) AutograderHelper.assert_same_shape ( correct correct, submitted=Autog raderHelper.parse_spark_take (small_counts_take_10), ) Now let's run it against the larger data set. The complete analysis could take about 10 minutes to run. []: text = sc.textFile('../../assets/data/nytimes/nytimes_news_articles.txt') counts = noun_phrase_length_distribution (text) [ ]: counts_take_10 = counts.take (10) counts_take_10 [ ]: assert counts_take_10 [0]== (1, 1205976), \ "The first item in the result is not correct." [ ]: # Autograder cell. This cell is worth 8 points (out of 20). This cell contains hidden tests. Create an RDD pipline to show the count of each part-of-speach tag sorted in descending order Complete the implementation of the pos_counts() function below so that it uses an RDD pipeline (i.e. sequence of transformations) to: 1. filter out blank lines 2. filter outlines starting with "URL" 3. create a single list (using flatMap) that applies the pos_tag_counter() function (this is defined below for you below) to each line 4. map each resulting element to show the part of speech (which is the second element returned from the pos_tag_counter) 5. convert each resulting element to a pairRDD with POS tags as keys and values of 1 6. reduce the resulting RDD by key, adding up all the 1s (like the lecture and lab examples) 7. sort the resulting list by the counts, in descending order 11:# This is the function you will use with flatMap in your pipeline. TOKEN_RE = re.compile(r"\b[\w]+\b") def pos_tag_counter(line): toks = nltk.regexp_tokenize (line, TOKEN_RE) postoks nltk.tag.pos_tag(toks) return postoks [1: def pos_counts (rdd): # YOUR CODE HERE raise Not ImplementedError() return pos_total_sorted # This should be the final stage of your pipeline, an RDD with the # count of each part-of-speach tag sorted in descending order. Let's start by trying your code on a small data set. The text_to_be_analyzed from the cells above will do nicely. We can use the parallelize() method to turn it into a RDD, pass that to your function, and then take() the first ten entries: II:small_text= sc.parallelize (text_to_be_analyzed.split("\n")) small_pos_counts = pos_counts (small_text) 11: small_pos_counts_take_10= small_pos_counts.take (10) small_pos_counts_take_10 11: # Autograder cell. This cell is worth 2 points (out of 280). This cell does not contain hidden tests. # This cell deliberately includes answers to provide guidance on how this question is graded. correct = AutograderHelper.parse_spark_take([ ('NN', 30), ('NNP', 24), ('IN', 20), ('DT', 16), (VRD 11) Question 2 -- Noun Phrase Length Task: Create an RDD pipeline to show the distribution of the length of noun phrases Complete the implementation of the noun_phrase_length_distribution () function below so that it uses an RDD pipeline to return a PairRDD which contains the distribution of the length of noun phrases. • The function get_noun_phrases () is defined below for you. • You can use flat Map() to apply get_noun_phrases () to each entry in the input RDD. • Sorting the resulting list by the counts in descending order will make the results easier to interpret. • Note that the filters from the previous question (PART-OF-SPEECH COUNT) are not needed here. That is: you don't need to remove blank lines or lines that start with "URL". [ ]: # This cell defines the get_noun_phrases() function you will use with flatMap() grammar="" NBAR: ww NP: *** ] {<NN.*|JJS>*<NN.*>} def get_noun_phrases (line): This function returns a list of lists of tuples. Each entry (list of tuples) is a breakdown of a noun phrase, and each tuple contains the word and a code for the noun phrase part. For example, get_noun_phrases ("The quick brown fox, jumps over the lazy dog.") returns: [ www {<NBAR>} {<NBAR><IN><NBAR>} [('brown', 'NN'), ('fox', 'NN')], [('dog', 'NN')] TOKEN_RE= re.compile(r"\b[\w']+\b") chunker nltk.RegexpParser (grammar) toks = nltk. regexp_tokenize (line, TOKEN_RE) postoks nltk. tag.pos_tag (toks) if len(postoks) == 0: return [] tree chunker.parse(postoks) return [term for term in leaves (tree)] def leaves (tree): for subtree in tree. subtrees(filter = lambda t: t. label()== 'NP') : yield subtree. leaves () []: def noun_phrase_length_distribution (rdd): # YOUR CODE HERE raise NotImplementedError() return distribution # This should be the final stage of your pipeline, a PairRDD with the # distribution of the length of noun phrases. [ ]:small_counts_take_10=small_counts.take (10) small_counts_take_10 The cell above should produce this output: This means there are 29 1-word noun phrases, 10 2-word noun phrases, 3 3-word noun phrases, and 2 4-word noun phrases in the small_text data set. [(1, 29), (2, 10), (3, 3), (4, 2)] [ ]: # Autograder cell. This cell is worth 2 points (out of 20). This cell does not contain hidden tests. # This cell deliberately includes answers to provide guidance on how this question is graded. correct AutograderHelper.parse_spark_take( [(1, 29), (2, 10), (3, 3), (4, 2)] ) AutograderHelper.assert_same_shape ( correct correct, submitted=Autog raderHelper.parse_spark_take (small_counts_take_10), ) Now let's run it against the larger data set. The complete analysis could take about 10 minutes to run. []: text = sc.textFile('../../assets/data/nytimes/nytimes_news_articles.txt') counts = noun_phrase_length_distribution (text) [ ]: counts_take_10 = counts.take (10) counts_take_10 [ ]: assert counts_take_10 [0]== (1, 1205976), \ "The first item in the result is not correct." [ ]: # Autograder cell. This cell is worth 8 points (out of 20). This cell contains hidden tests.
Expert Answer:
Answer rating: 100% (QA)
To complete the implementation of the poscounts function and the nounphraselengthdistribution function using RDD pipelines in PySpark you can follow t... View the full answer

Related Book For 

Posted Date:
Students also viewed these programming questions
-
What is the magnetic field where the electrons are traveling that results from this 1 A current in the Helmholtz coils? Hint: Evaluate the expression given for the field between two Helmholtz coils...
-
In the last chapter you added and modified some tables for Kelly's Boutique. She would now like you to create, run, and print some select, parameter, and action queries. Make the following changes...
-
ConAir (CA) commercial airlines company requires you experience in database design and have approached you to assist in the design of their new airline database system. They urgently need to have...
-
Oliver owns Wifit, an unincorporated sports store. Wifit earned $100,000 before Oliver drew out a salary of $60,000. What is Oliver's deduction for self-employment taxes? Group of answer choices A....
-
Ramirez Company has an available-for-sale investment in the 6%, 20-year bonds of Soto Company. The investment was originally purchased for $1,200,000 in 2009. Early in 2010, Ramirez recorded an...
-
Estimate the Joule-Thomson coefficient of steam at 800 psia and 800F, and then estimate the value for Cp at that state using Eq. 7.53. Compare with the value found by using Cp = (h / T)P.
-
Why are financial statements translated from one currency to another?
-
Turner, Roth, and Lowe are partners who share income and loss in a 1:4:5 ratio. After lengthy disagreements among the partners and several unprofitable periods, the partners decide to liquidate the...
-
6. The number of (staircase) paths in the xy-plane from (0, 0) to (7, 5) where each such path is made up of individual steps going one unit upward (U) or one unit to the right (R). (a) 12C5 (b) 12!...
-
A welding torch is remotely controlled to achieve high accuracy while operating in changing and hazardous environments [21]. A model of the welding arm position control is shown in Figure DP7.4, with...
-
When new technologies make cleaner production possible, a) emissions would fall under a system of fees, but would not fall under a system of transferable emissions permits unless the government...
-
Why is the gross estate different from the probate estate?
-
If a taxpayer is on the fiscal year, what is the requirement regarding the taxpayer's books?
-
Is it possible to defer gain through the purchase of a new residence?
-
Explain the fruit-of-the-tree doctrine and why it was established by the courts.
-
Explain the doctrines of "continuity of business enterprise" and "continuity of proprietary interest."
-
A person starts from his home and walks the following distances: i) 1500 yards, 50 N of E ii) 1800 yards, 50 W of N iii) 1000 yards, due south. What direction is the person relative to his home? 000...
-
Select a mass spectrometric technique with the highest mass resolution for identifying an unknown compound being eluted from a liquid chromatography column
-
For each buyer name, create a form (using the Forms Wizard) that contains the product name, quantity, and unit price of each product that the buyer is responsible for. Use the sub form option with a...
-
Create new queries for Coast Jewelers a. Create and print a query for Coast Jewelers that lists the supplier name, contact name, and phone number of every supplier. Save the query as Supplier Query...
-
Why does the typical cash budget spread payment of purchases over more than one month?
-
A steam turbine operates on a Carnot cycle, with a maximum pressure of 20 bar and a condenser pressure of 0.5 bar. Calculate the salient points of the cycle, the energy addition and work output per...
-
Van der Waals equation for water is given by \[p=\frac{0.004619 T}{v-0.0016891}-\frac{0.017034}{v^{2}}\] where \(p=\) pressure (bar), \(v=\) specific volume \(\left(\mathrm{m}^{3} / \mathrm{kmol}...
-
A steam power plant operating on a basic Rankine cycle has the following parameters: maximum (boiler) pressure 20 bar; minimum (condenser) pressure 0.5 bar. Calculate the thermal efficiency of the...

Study smarter with the SolutionInn App