

Question: ( d ) Suppose max pooling is applied on an 8 8 image with a 2 2 filter and stride 2 pixels. What will be
d Suppose max pooling is applied on an image with a filter
and stride pixels. What will be the number of parameters in this
layer?
mark
e Consider the following plot of the number of stochastic gradient
descent SGD iterations required to reach a given loss, as a function
of the batch size:
For small batch sizes, the number of iterations required to reach the target
loss decreases as the batch size increases. Why is that?
marks
f Write down the number of parameters in each field. Assume the
convolution filter is of shape what would be the values in
the fields II III, and V
marksg You are given a black box optimizer which produces the loss curve
shown in Figure A You see a big red button on the optimizer and
decide to push it After doing this, you notice the loss curve shown in
Figure B You press the button one more time and finally notice the
loss curve shown in Figure C
gure
The red button modifies a single hyperparameter. Which hyperparameter is
most likely to be modified by pressing the button?
mark
Also, of experiments and which corresponds to largest magnitude of
the hyperparameter?
mark
Lastly, the loss curve for experiment seems to be the most desirable.
Despite this, give two reasons why you would choose the hyperparameter
in experiment for training your model.
marksNeural networks.
a Let us say you have a training set containing pairs where
vector is to be assigned to one of classes in a supervised setting
and the labels yi are the vectors in containing a single
representing the target class, ie if there are classes and some
should be assigned to class then To do this, it is
proposed that you use neural networks. The ith network has
parameters wi and computes the function wi You may make no
further assumptions regarding the function
You aim to treat the output of the th network as an estimate of the
probability class that should be in the th class,
where collects together all the vectors dots, It is
proposed that to do this you should modify the setup described to
compute
class prob
expexp
Explain why this modification is required, and how it achieves the
stated aim?
marks
b Suppose a convolution layer takes a input volume, and
applies ten filters with stride pixel and padding pixels. What
will be the size of the output volume?
marks
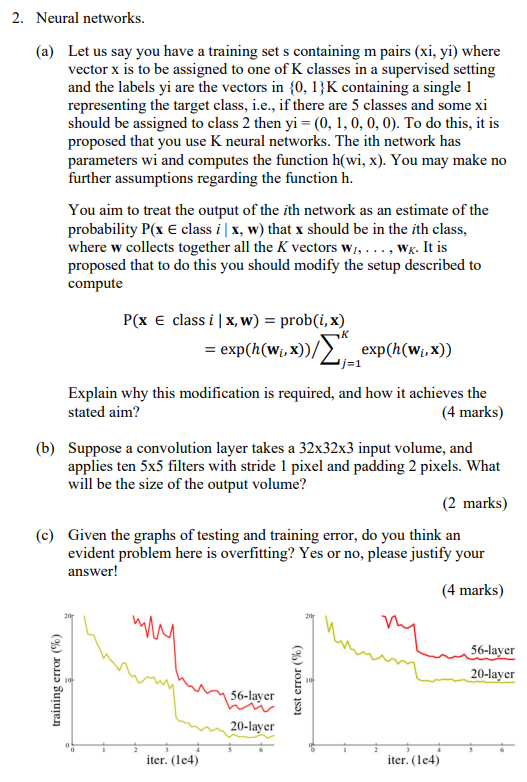
c Given the graphs of testing and training error, do you think an
evident problem here is overfitting? Yes or no please justify your
answer!
marks
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock