Question: For this assignment, you will write a program to process a file named word.data containing information about some number of English words. (Note that I
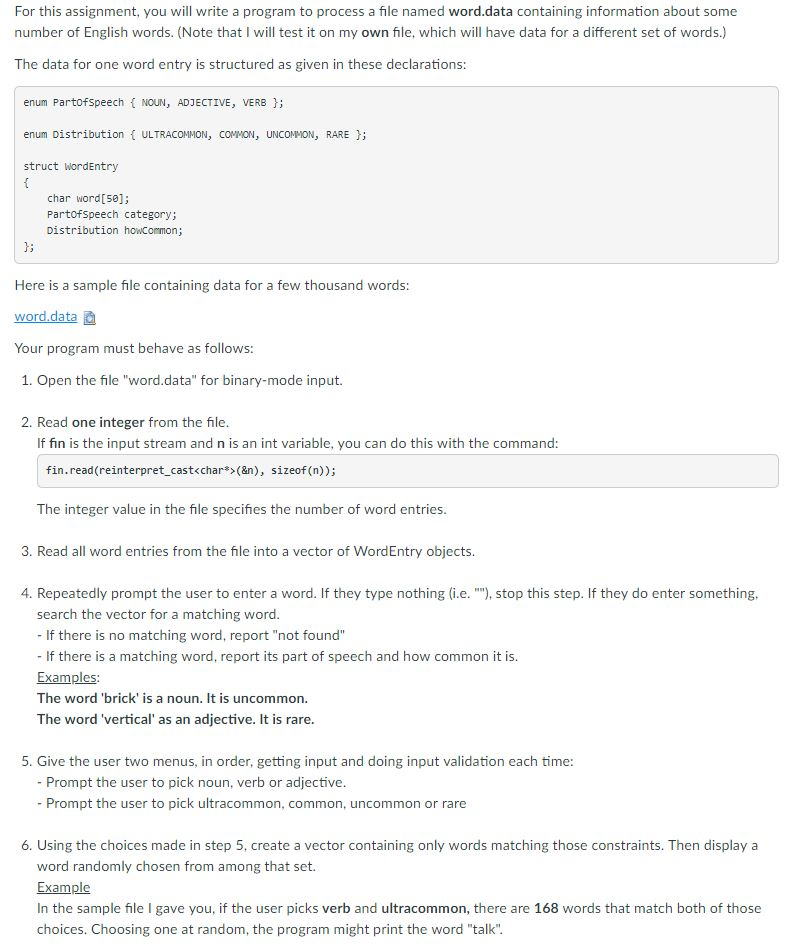
For this assignment, you will write a program to process a file named word.data containing information about some number of English words. (Note that I will test it on my own file, which will have data for a different set of words.) The data for one word entry is structured as given in these declarations: enum Partofspeech NOUN, ADJECTIVE, VERB enum Distribution ULTRACOMMON, COMMON, UNCOMMON, RARE struct WordEntry char word s0]; Partofspeech category; Distribution howComon Here is a sample file containing data for a few thousand words word.data Your program must behave as follows: 1. Open the file "word.data" for binary-mode input. 2. Read one integer from the file If fin is the input stream and n is an int variable, you can do this with the command fin.read(reinterpret cast(&n), sizeof (n)); The integer value in the file specifies the number of word entries 3. Read all word entries from the file into a vector of WordEntry objects. 4. Repeatedly prompt the user to enter a word. If they type nothing (i.e. ""), stop this step. If they do enter something. search the vector for a matching word - If there is no matching word, report "not found" - If there is a matching word, report its part of speech and how common it is. Examples The word 'brick' is a noun. It is uncommon. The word 'vertical' as an adjective. It is rare 5. Give the user two menus, in order, getting input and doing input validation each time: - Prompt the user to pick noun, verb or adjective - Prompt the user to pick ultracommon, common, uncommon or rare 6. Using the choices made in step 5, create a vector containing only words matching those constraints. Then display a word randomly chosen from among that set. Example In the sample file I gave you, if the user picks verb and ultracommon, there are 168 words that match both of those choices. Choosing one at random, the program might print the word "talk". For this assignment, you will write a program to process a file named word.data containing information about some number of English words. (Note that I will test it on my own file, which will have data for a different set of words.) The data for one word entry is structured as given in these declarations: enum Partofspeech NOUN, ADJECTIVE, VERB enum Distribution ULTRACOMMON, COMMON, UNCOMMON, RARE struct WordEntry char word s0]; Partofspeech category; Distribution howComon Here is a sample file containing data for a few thousand words word.data Your program must behave as follows: 1. Open the file "word.data" for binary-mode input. 2. Read one integer from the file If fin is the input stream and n is an int variable, you can do this with the command fin.read(reinterpret cast(&n), sizeof (n)); The integer value in the file specifies the number of word entries 3. Read all word entries from the file into a vector of WordEntry objects. 4. Repeatedly prompt the user to enter a word. If they type nothing (i.e. ""), stop this step. If they do enter something. search the vector for a matching word - If there is no matching word, report "not found" - If there is a matching word, report its part of speech and how common it is. Examples The word 'brick' is a noun. It is uncommon. The word 'vertical' as an adjective. It is rare 5. Give the user two menus, in order, getting input and doing input validation each time: - Prompt the user to pick noun, verb or adjective - Prompt the user to pick ultracommon, common, uncommon or rare 6. Using the choices made in step 5, create a vector containing only words matching those constraints. Then display a word randomly chosen from among that set. Example In the sample file I gave you, if the user picks verb and ultracommon, there are 168 words that match both of those choices. Choosing one at random, the program might print the word "talk


