

Question: given code: emcee.l %option noyywrap A [a-zA-Z] /* 1. include other pattern definitions here, if needed. Digits maybe? */ %{ #include tokens.h /* Leave this
![given code: emcee.l %option noyywrap A [a-zA-Z] /* 1. include other](https://dsd5zvtm8ll6.cloudfront.net/si.experts.images/questions/2024/09/66f50eea04b99_16966f50ee94f30c.jpg)


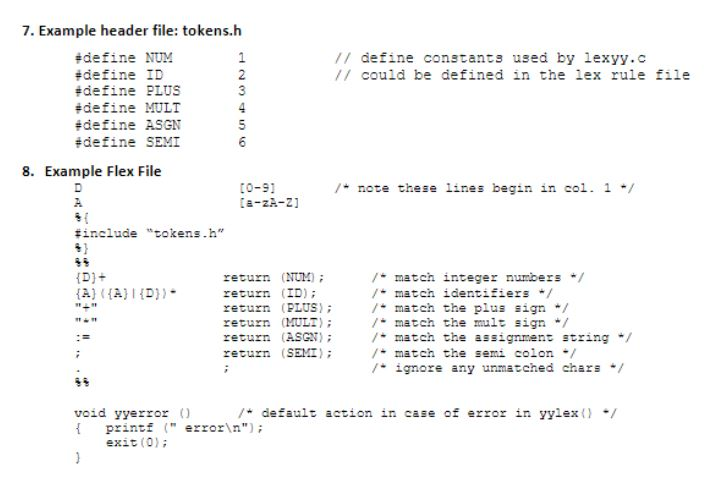
given code: emcee.l
%option noyywrap
A [a-zA-Z]
/* 1. include other pattern definitions here, if needed. Digits maybe? */
%{
#include "tokens.h" /* Leave this section untouched */
%}
%%
def return (DEF);
/* 2. Add other keywords here AND DELETE THIS COMMENT! */
{A}+ return (ID);
/* 3. Add other pattern words here AND DELETE THIS COMMENT! */
";" return (SEMI);
/* 4. Add other punctuation here AND DELETE THIS COMMENT! */
/* 5. Remember to recognize and ignore unknown punctuation, new-lines and comments AND DELETE THIS COMMENT! */
%%
void yyerror () /* Leave this section untouched */
{
printf (" error ");
exit(0);
}
given code: emcee.c
#include
#include "tokens.h"
int yylex (); // scanner prototype
extern char* yytext;
main ()
{ int n;
printf("Emcee Compiler ver. 0.1 ");
while (n = yylex()) { // call scanner until it returns 0 for EOF
switch (n) {
case REAL_CONST:
case ID:
case INT_CONST:
case STRING_CONST: printf (" %d (%s)", n, yytext); break;
default: printf (" %d", n); break;
}
}
printf(" ");
}
given code: sqrt.mc
# First program written in Emcee
def guess : real;
def n : real;
# Set the input variables
guess := 1.0;
n := inputReal();
if [ n >= 0.0 ] then
{
# Continue until the root has been found
while [ abs(guess^2 - n) > 0.01 ]
{
guess := (n + (n / guess)) / 2;
};
# Print the result
print("Root is ", guess);
};
given code: token.h
#define DEF 1
#define INTEGER 2
#define REAL 3
#define STRING 4
#define IF 5
#define THEN 6
#define WHILE 7
#define REAL_CONST 8
#define ID 9
#define INT_CONST 10
#define STRING_CONST 11
#define SEMI 12
#define COLON 13
#define LEFT_PAREN 14
#define RIGHT_PAREN 15
#define PLUS 16
#define MINUS 17
#define MULT 18
#define DIVIDE 19
#define CARAT 20
#define MOD 21
#define EQUAL 22
#define NOT_EQUAL 23
#define LESS_THAN 24
#define GREATER_THAN 25
#define LESS_EQUAL 26
#define GREATER_EQUAL 27
#define ASSIGN 28
#define LEFT_SQUARE 29
#define RIGHT_SQUARE 30
#define LEFT_BRACE 31
#define RIGHT_BRACE 32
#define COMMA 33
Lexical Analyzer for Emcee 1. Problem Description we are building our own computer language called Emcee. As we have learned in class, there are four different levels of analysis Lexical- identifiers, keywords, punctuation, comments, etc. Syntactic-the structures within the language (e.g. definitions, if-statements) . Contextual -static checking of variables, type, name, initialization, etc. Semantic-meaning and behavior of a program When building a compiler for this language, we must account for each level. The first step in compilation is the Lexical Analyzer. It is responsible for reading the input source code file and breaking it up into the various tokens defined by the language. This is your assignment. First, review a description of the Emcee language which is defined in the file "Emcee Language Overview.doc". Create a list of all the different tokens you will need for the language. Here is a hint: there are four patterns that need to be recognized (for example, identifiers), seven keywords and 22 punctuation marks. Multiple characters that go together to form a single symbol are considered a single token, for example,:- for assignment. Don't forget to recognize comments, new-lines and any other characters and ignore them. If the source code happens to have an unrecognized character (e.g. $), it will simple be ignored Next, write a program that reads from Standard Input (a UNIX concept) and produces a list of token numbers. If the token recognized is one of the 4 patterns, then also print the pattern that was recognized. You can look at the example output to get a better idea of what is required here. Such a program is called a Lexical Analyzer, or simple a Scanner. Writing a Scanner is not a simple task but programmers have been building them since the dawn of high level languages. Because of that, tools have been developed that will generate the Scanner for you. All you need to do is describe the tokens that the language expects to find and the tool will create the analyzer code One such Scanner-generator tool is called Lex. Lex was originally written in 1975 and was used on many Unix systems. Lex reads a file that specifies the lexical analyzer and outputs source code implementing the Scanner in the C programming language. Since then, a new open-source tool called Flex ("fast lexical analyzer") has been written and should have been downloaded when you set up your Pi. A good introduction to the Flex tool can be found in the document "Lex Overview.doc" Lexical Analyzer for Emcee 1. Problem Description we are building our own computer language called Emcee. As we have learned in class, there are four different levels of analysis Lexical- identifiers, keywords, punctuation, comments, etc. Syntactic-the structures within the language (e.g. definitions, if-statements) . Contextual -static checking of variables, type, name, initialization, etc. Semantic-meaning and behavior of a program When building a compiler for this language, we must account for each level. The first step in compilation is the Lexical Analyzer. It is responsible for reading the input source code file and breaking it up into the various tokens defined by the language. This is your assignment. First, review a description of the Emcee language which is defined in the file "Emcee Language Overview.doc". Create a list of all the different tokens you will need for the language. Here is a hint: there are four patterns that need to be recognized (for example, identifiers), seven keywords and 22 punctuation marks. Multiple characters that go together to form a single symbol are considered a single token, for example,:- for assignment. Don't forget to recognize comments, new-lines and any other characters and ignore them. If the source code happens to have an unrecognized character (e.g. $), it will simple be ignored Next, write a program that reads from Standard Input (a UNIX concept) and produces a list of token numbers. If the token recognized is one of the 4 patterns, then also print the pattern that was recognized. You can look at the example output to get a better idea of what is required here. Such a program is called a Lexical Analyzer, or simple a Scanner. Writing a Scanner is not a simple task but programmers have been building them since the dawn of high level languages. Because of that, tools have been developed that will generate the Scanner for you. All you need to do is describe the tokens that the language expects to find and the tool will create the analyzer code One such Scanner-generator tool is called Lex. Lex was originally written in 1975 and was used on many Unix systems. Lex reads a file that specifies the lexical analyzer and outputs source code implementing the Scanner in the C programming language. Since then, a new open-source tool called Flex ("fast lexical analyzer") has been written and should have been downloaded when you set up your Pi. A good introduction to the Flex tool can be found in the document "Lex Overview.doc
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts