

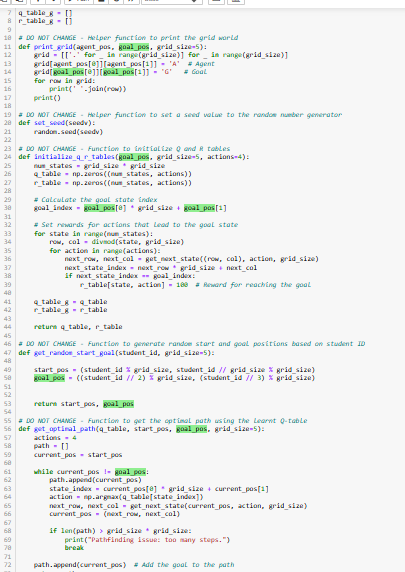
Question: # Global Paramaters ( Do not change these parameter names ) STUDENTID = # Enter your student ID ( You may change this to try
# Global Paramaters Do not change these parameter names STUDENTID # Enter your student ID You may change this to try different start and goal positions GRIDSIZE # ACTIONS # DO NOT CHANGE EPISODES # CHANGE to an appropriate number to ensure agent learns to find the optimal path and that Q table converges # Do not change number of episodes parametervariable anywhere else in the code ALPHA # DO NOT CHANGE EPSILON # DO NOT CHANGE GAMMA # DO NOT CHANGE # TASK Complete the function to get next state based on given action def getnextstatecurrentstatepos, action, gridsize: # DO NOT CHANGE THIS LINE row, column currentstatepos # DO NOT CHANGE THIS LINE if action and row : # Move up # Task update row andor column as needed # YOUR CODE HERE elif action and row gridsize : # Move down # Task update row andor column as needed # YOUR CODE HERE elif action and column : # Move left # Task update row andor column as needed elif action and column gridsize : # Move right # Task update row andor column as needed # YOUR CODE HERE return row, column # DO NOT CHANGE THIS LINE # TASK # Complete the getaction function in Task # This function will be called from the qlearning function see below # Inputs: # qtable, epsilon, currentstateindex # Outputs: # action: based on epsilongreedy decision making policy, should be either or # def getactionqtable, epsilon, currentstateindex: # Task Choose an action using epsilongreedy policy # YOUR CODE HERE return action # TASK # Complete the updateqtable function in Task # This function will be called from the qlearning function # Inputs: # qtable, rtable, currentstateindex, action, nextstateindex, alpha gamma # Outputs: # qtable: with updated Q values def updateqtableqtable, rtable, currentstateindex, action, nextstateindex, alpha gamma: # Task Update the qtable using the Q learning equations taught in class # YOUR CODE HERE return qtable # TASKS and : Qlearning algorithm following epsilongreedy policy # Inputs: # qtable, rtable: initialized by calling the initializeqrtables function inside the main function # startpos, goalpos: given by the getrandomstartgoal function based on studentid and gridsize # numepisodes: taken from the global constant EPISODES you need to determine the episodes needed to train the agent to find the optimal path # gridsize: To try different grid sizes, change the GRIDSIZE global constant # alpha, gamma, epsilon: DO NOT CHANGE # Outputs: # qtable: the final qtable after training def qlearningstartpos, goalpos, qtableqtableg rtablertableg numepisodesEPISODES, alpha gamma epsilon gridsize: for episode in rangenumepisodes: # Initialize the state index corresponding to the starting position currentstateindex startpos gridsize startpos currentstatepos startpos # currentstatepos has current row, column position of the agent done False while not done: # Task COMPLETE THE CODE IN getaction FUNCTION ABOVE action getactionqtable, epsilon, currentstateindex # Task Get next state based on the chosen action # YOUR CODE HERE nextstatepos # Complete this line of code, DO NOT CHANGE VARIABLE NAMES nextstateindex # Complete this line of code, DO NOT CHANGE VARIABLE NAMES # Task COMPLETE THE CODE IN updateqtable FUNCTION ABOVE qtable updateqtableqtable, rtable, currentstateindex, action, nextstateindex, alpha, gamma # Update the 'state' to the next state index currentstatepos nextstatepos currents # Do not change number of episodes parametervariable anywhere else in the code ALPHA # DO NOT CHANGE EPSILON # DO NOT CHANGE GAMMA # DO NOT CHANGE
helper methods are attached
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock