

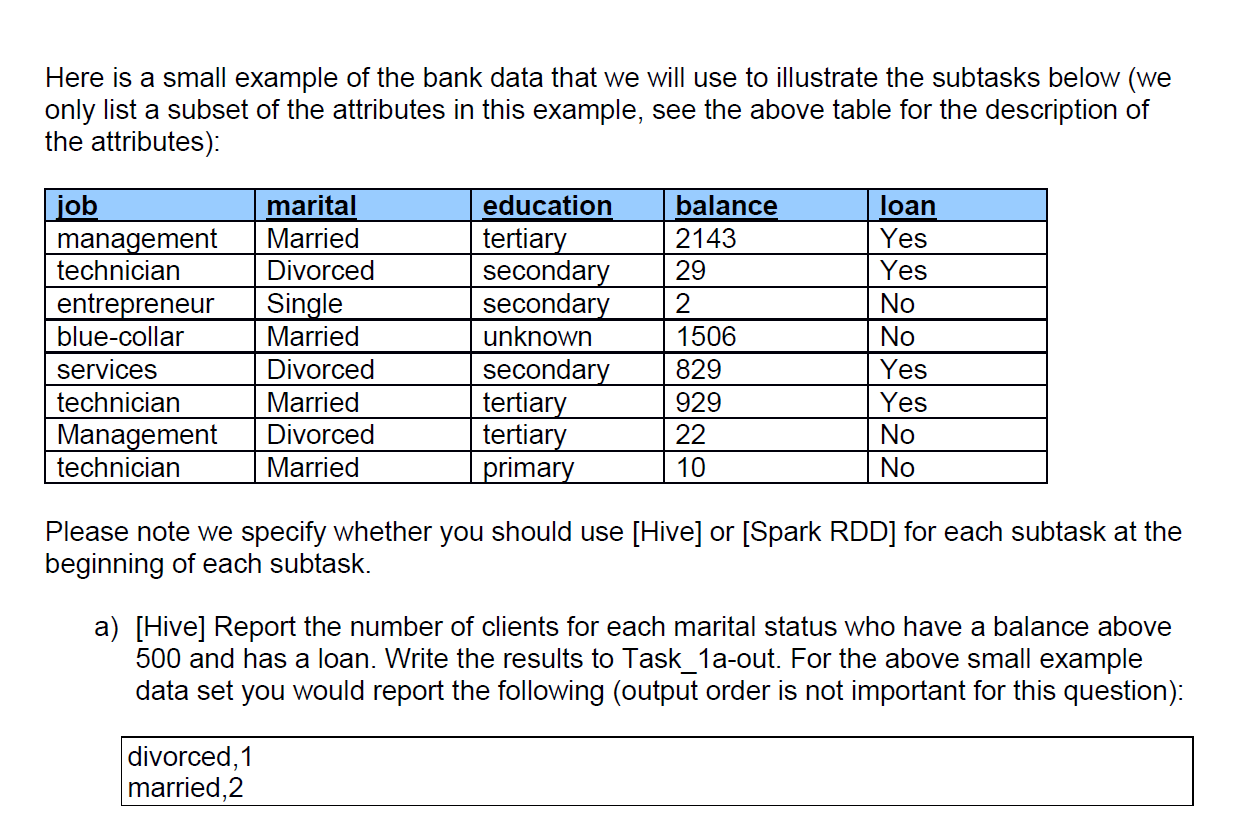
Question: Here is a small example of the bank data that we will use to illustrate the subtasks below (we only list a subset of
![b) [Hive] Report the average yearly balance for all people in each job category in descending order of](https://dsd5zvtm8ll6.cloudfront.net/questions/2023/11/654a1fb8dd35a_600654a1fb8d9b28.jpg)
![c) [Spark RDD] Group balance into the following three categories: a. Low: -infinity to 500 b. Medium: 501 to](https://dsd5zvtm8ll6.cloudfront.net/questions/2023/11/654a1fb962a67_601654a1fb95f495.jpg)
![d) [Spark RDD] Output the following details for each person whose job category has an average balance above](https://dsd5zvtm8ll6.cloudfront.net/questions/2023/11/654a1fba264b5_602654a1fba227e2.jpg)
Here is a small example of the bank data that we will use to illustrate the subtasks below (we only list a subset of the attributes in this example, see the above table for the description of the attributes): job management technician entrepreneur blue-collar services technician Management technician marital Married Divorced Single Married Divorced Married Divorced Married divorced, 1 married,2 education tertiary secondary secondary unknown secondary tertiary tertiary primary balance 2143 29 2 1506 829 929 22 10 loan Yes Yes No No Yes Yes No No Please note we specify whether you should use [Hive] or [Spark RDD] for each subtask at the beginning of each subtask. a) [Hive] Report the number of clients for each marital status who have a balance above 500 and has a loan. Write the results to Task_1a-out. For the above small example data set you would report the following (output order is not important for this question): b) [Hive] Report the average yearly balance for all people in each job category in descending order of average yearly balance. Write the results to Task_1b-out. For the small example data set you would report the following: blue-collar, 1506.0 management, 1082.5 services,829.0 technician, 322.6666666666667 entrepreneur,2.0 c) [Spark RDD] Group balance into the following three categories: a. Low: -infinity to 500 b. Medium: 501 to 1500 => c. High: 1501 to +infinity Report the number of people in each of the above categories. Write the results to "Task_1c-out" in text file format. For the small example data set you should get the following results (output order is not important in this question): High,2 Medium,2 Low,4 d) [Spark RDD] Output the following details for each person whose job category has an average balance above 500: education, balance, job, marital, loan. Make sure the output is in decreasing order of individual balance. Write the results to Task_1d-out in text file format (output to a single file). For the small example data set you would report the following: tertiary, 2143.0, management, married, yes unknown, 1506.0, blue-collar, married, no secondary, 829.0, services, divorced, yes tertiary, 22.0, management, divorced, no
Step by Step Solution
There are 3 Steps involved in it
Solutions for Bank Data Analysis a Hive Query for Clients with Loan and Balance 500 by Marital Statu... View full answer

Get step-by-step solutions from verified subject matter experts