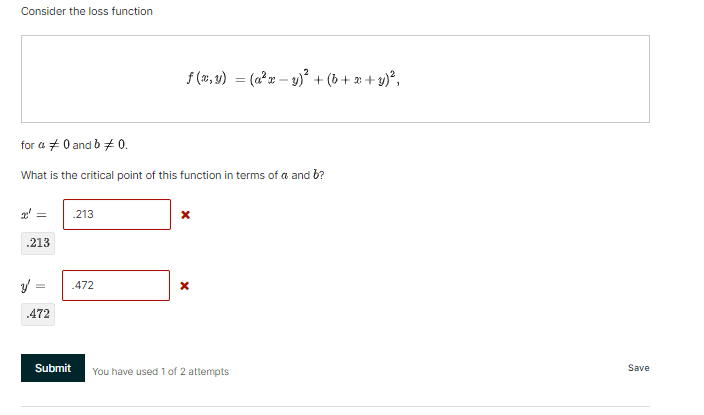
Question: Hessian example 4 points possible (graded) Recall your earlier solution for the loss function f(,y) = (a'x-y) + ( b+x+y), for a # 0 and
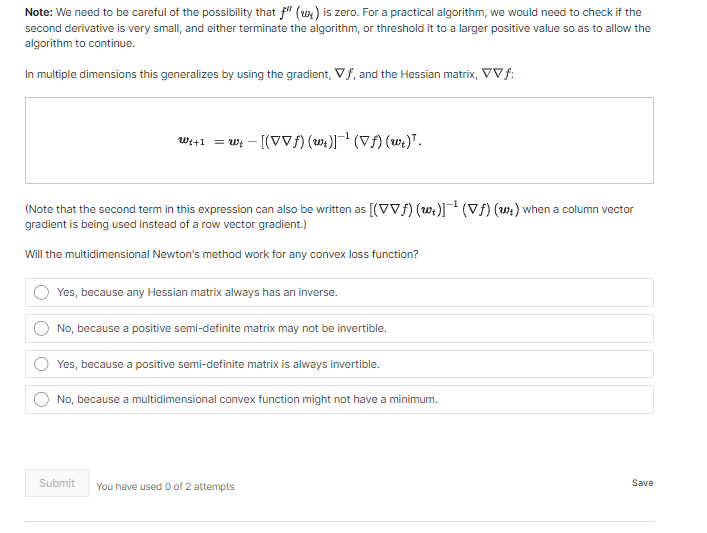
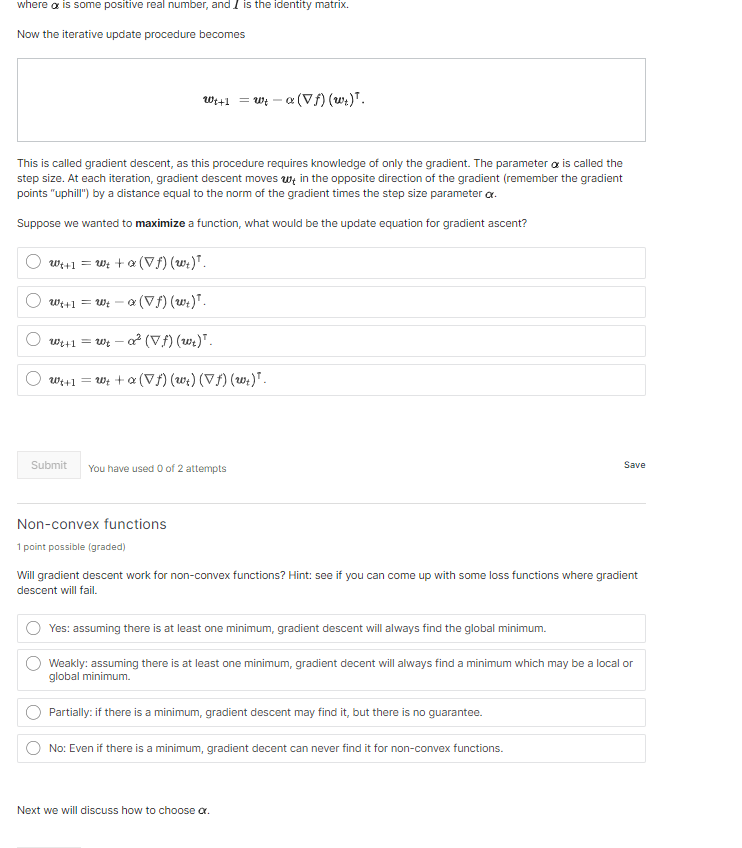
Hessian example 4 points possible (graded) Recall your earlier solution for the loss function f(,y) = (a'x-y) + ( b+x+y), for a # 0 and b / 0. Now, calculate the hessian Arby = (AA) = H 8- f Brdy H =Consider the loss function f ( @,y) = (ax-y) +(b+x+y), for a * 0 and b / 0. What is the critical point of this function in terms of a and b? .213 X .213 472 X .472 Submit You have used 1 of 2 attempts SaveNote: We need to be careful of the possibility that f" (wy ) is zero. For a practical algorithm, we would need to check if the second derivative is very small, and either terminate the algorithm, or threshold it to a larger positive value so as to allow the algorithm to continue. In multiple dimensions this generalizes by using the gradient, Vf, and the Hessian matrix, VV f: With=w -[(VVA(w.)](VA(w.)T. Note that the second term in this expression can also be written as [(VV/) (w.)]"(Vf) (w;) when a column vector gradient is being used instead of a row vector gradient.) Will the multidimensional Newton's method work for any convex loss function? () Yes, because any Hessian matrix always has an inverse. No, because a positive semi-definite matrix may not be invertible. Yes, because a positive semi-definite matrix is always invertible. )No, because a multidimensional convex function might not have a minimum. Submit You have used 0 of 2 attempts Savewhere a is some positive real number, and / is the identity matrix. Now the iterative update procedure becomes With =w - a( Vf) ( w) . This is called gradient descent, as this procedure requires knowledge of only the gradient. The parameter o is called the step size. At each iteration, gradient descent moves wit in the opposite direction of the gradient (remember the gradient points "uphill") by a distance equal to the norm of the gradient times the step size parameter or. Suppose we wanted to maximize a function, what would be the update equation for gradient ascent? J Will = w to ( Vf ) ( w ). With = wt - a (Vf) () . O with = wt - o' (Vf ) (w.) . Owl= w to ( VA) (w.) (VA) (w). Submit You have used 0 of 2 attempts Save Non-convex functions 1 point possible (graded) Will gradient descent work for non-convex functions? Hint: see if you can come up with some loss functions where gradient descent will fail. Yes: assuming there is at least one minimum, gradient descent will always find the global minimum. O Weakly: assuming there is at least one minimum, gradient decent will always find a minimum which may be a local or global minimum. Partially: if there is a minimum, gradient descent may find it, but there is no guarantee. No: Even if there is a minimum, gradient decent can never find it for non-convex functions. Next we will discuss how to choose c
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock
Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock
Students Have Also Explored These Related Mathematics Questions!