

Question: How can I compute MDP in Machine Learning! I add the formulas for it C. Compute the state-action value functions obtained by Sarsa and Q-learning
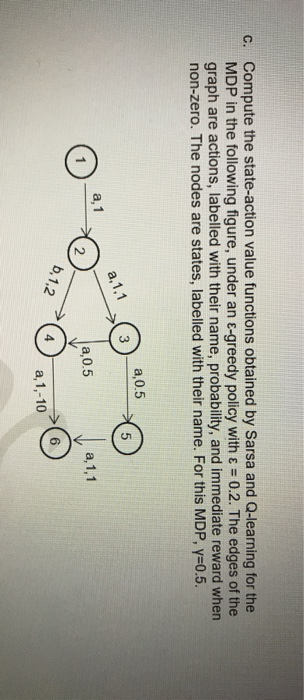

C. Compute the state-action value functions obtained by Sarsa and Q-learning for the MDP in the following figure, under an E-greedy policy with = 0.2. The edges of the graph are actions, labelled with their name, probability, and immediate reward when non-zero. The nodes are states, labelled with their name. For this MDP, y=0.5. 2,0.5 a 0.5 Ja,0.5 a,1,1 a,1,-10 Sarsa update: Qx+1(s, a) = (x(s, a) + a(R4+1 + y Q(s', a') - Ox(s,a)). Q-learning update: Qx+1(s, a) = (x(s, a) + a(Rt+1 + max ' Y Qx(s', a') - Qx(s, a)) C. Compute the state-action value functions obtained by Sarsa and Q-learning for the MDP in the following figure, under an E-greedy policy with = 0.2. The edges of the graph are actions, labelled with their name, probability, and immediate reward when non-zero. The nodes are states, labelled with their name. For this MDP, y=0.5. 2,0.5 a 0.5 Ja,0.5 a,1,1 a,1,-10 Sarsa update: Qx+1(s, a) = (x(s, a) + a(R4+1 + y Q(s', a') - Ox(s,a)). Q-learning update: Qx+1(s, a) = (x(s, a) + a(Rt+1 + max ' Y Qx(s', a') - Qx(s, a))
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts