

Question: How do I write this in CUDA C++ usingOpenCV? You have to fill in the code where it says TODO. Theimage is grayscale. See image
How do I write this in CUDA C++ usingOpenCV?
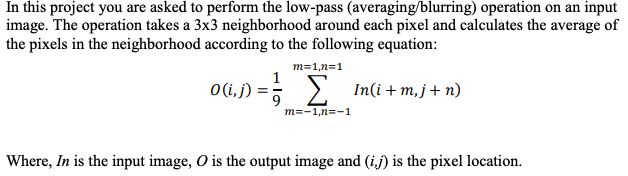
You have to fill in the code where it says TODO. Theimage is grayscale. See image below code:

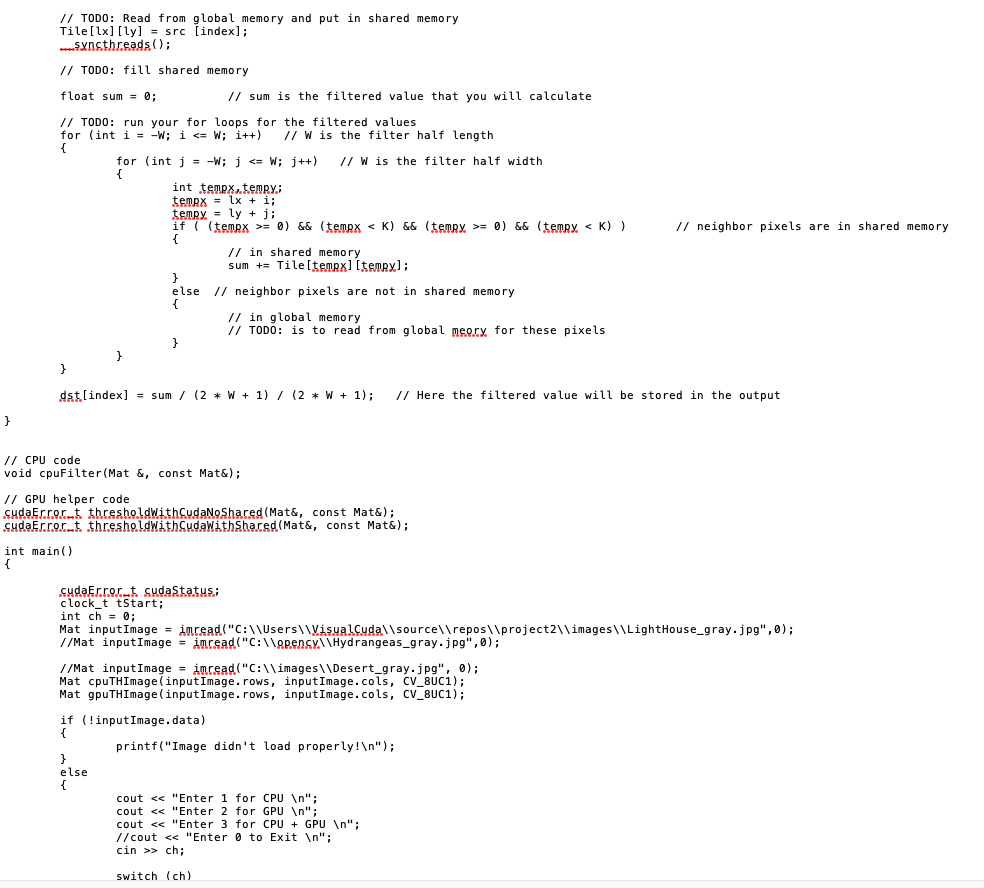
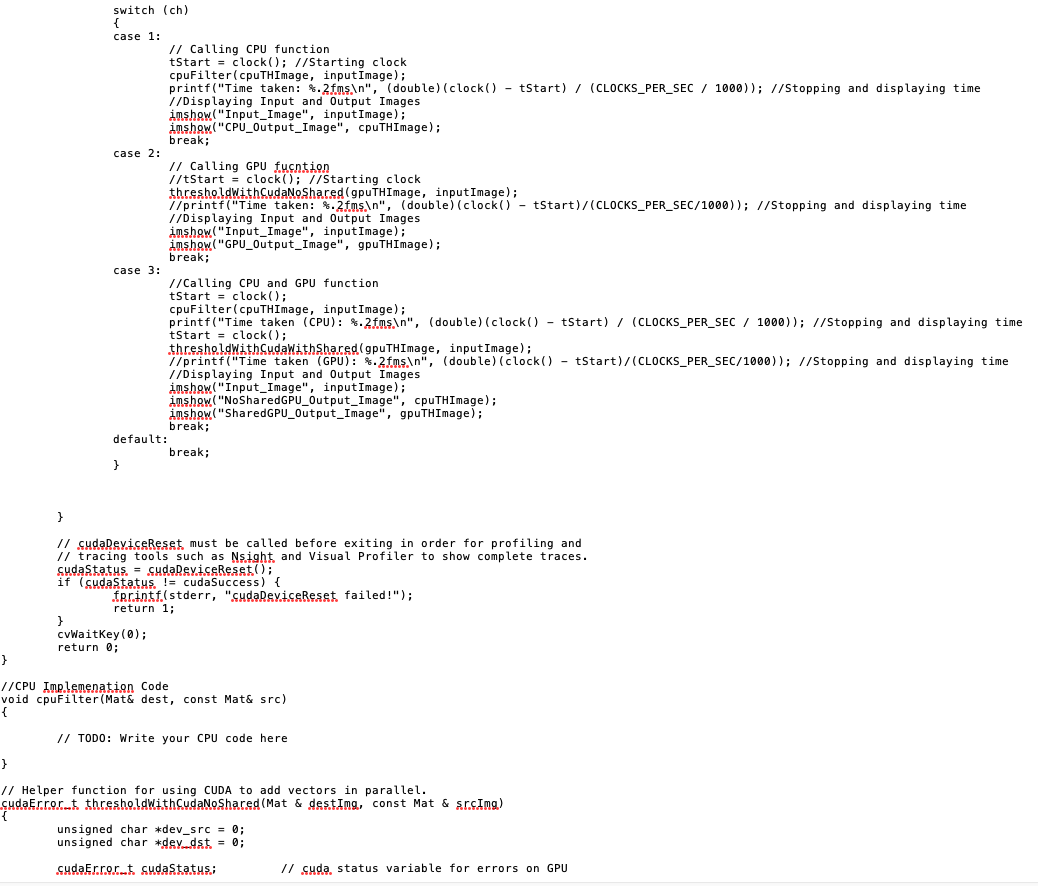



This is what the result should be:
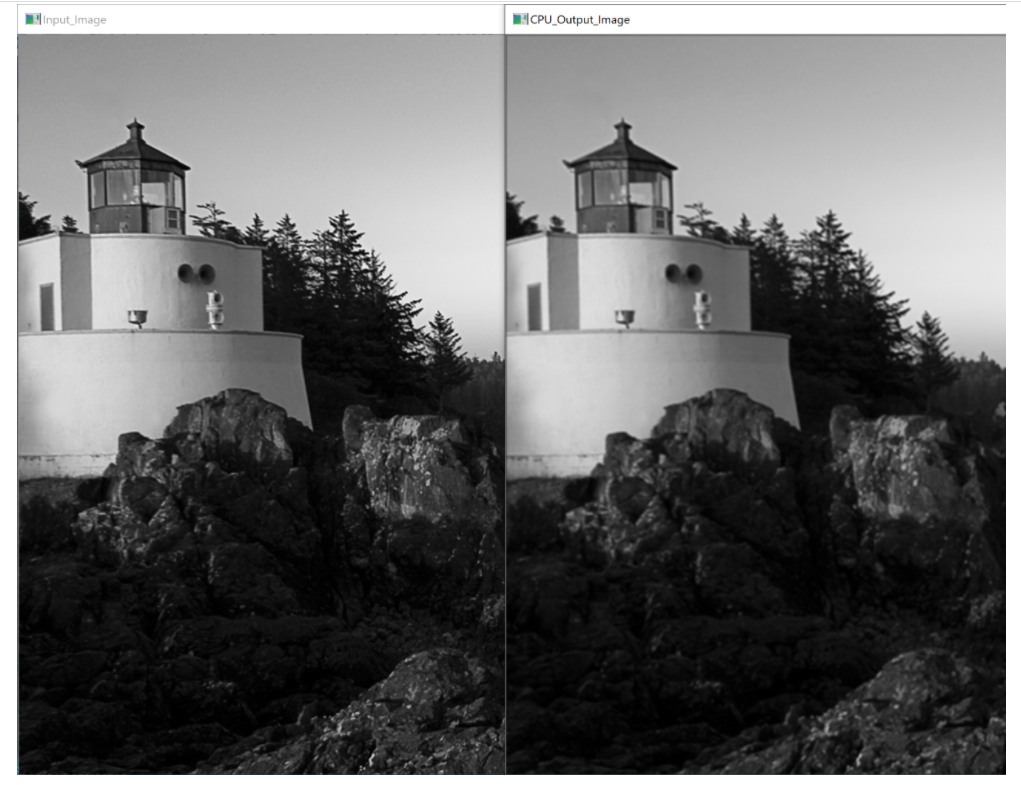
In this project you are asked to perform the low-pass (averaging/blurring) operation on an input image. The operation takes a 3x3 neighborhood around each pixel and calculates the average of the pixels in the neighborhood according to the following equation: 0 (i, j) m=1,n=1 In(i+mj+n) m=-1,n=-1 Where, In is the input image, O is the output image and (ij) is the pixel location. #include cuda_runtime.h #include device_launch_parameters.h #include #include #include #include #define K 16 #define W 1 using namespace cv; using namespace std; } _global_ void gpuKernel (unsigned char * dst, const unsigned char * src) // this kernel uses the global memory without shared memory { int index = 0; int neighbor; // K is the size of block Kxk // size of filter is (2W+1) x (2W+1) float sum= 0; // TODO: define global X and global Y and use these to calculate global offset int X, Y; // Pixel X and Y in global memory // TODO: if global X and global Y are within the image proceed } // TODO: run the filter 3x3 with two nested for loops for (int i = -W; i } // TODO: Read from global memory and put in shared memory Tile [lx] [ly]=src [index]; syncthreads(); // TODO: fill shared memory float sum = 0; // TODO: run your for loops for the filtered values for (int i = W; i = 0) && (tempy < K) ) { } else } } else { // in shared memory sum + Tile [tempx] [tempx]; // neighbor pixels are not in shared memory // in global memory // TODO: is to read from global meory for these pixels dst[index] = sum / (2* W + 1) / (2* W + 1); // Here the filtered value will be stored in the output. // CPU code void cpuFilter (Mat &, const Mat&); // GPU helper code cudaErrort thresholdWith CudaNoShared (Mat&, const Mat&); cudaErrort thresholdWithCudaWithShared (Mat&, const Mat&); cudaErrort sudaStatus: clock_t tStart; int ch = 0; Mat inputImage = imread( C:\\Users\\VisualCuda\\source\epos\\project2\\images\\LightHouse_gray.jpg ,0); //Mat inputImage = imread( C:\\opency\\Hydrangeas_gray.jpg ,0); //Mat input Image = imread( C:\\images\\Desert_gray.jpg , 0); Mat cpuTHImage (inputImage.rows, inputImage.cols, CV_8UC1); Mat gpuTHImage (inputImage.rows, inputImage.cols, CV_8UC1); if (!inputImage.data) printf( Image didn t load properly! ); // neighbor pixels are in shared memory cout < < Enter 1 for CPU ; cout < < Enter 2 for GPU ; cout < < Enter 3 //cout < < Enter cin >> ch; switch (ch) for CPU + GPU ; to Exit ; switch (ch) { case 1: } case 2: case 3: default: } // Calling CPU function tStart clock(); //Starting clock cpuFilter(cpuTHImage, inputImage); printf( Time taken: %.2fms , (double) (clock() - tStart) / (CLOCKS_PER_SEC / 1000)); //Stopping and displaying time //Displaying Input and Output Images imshow( Input_Image , input Image); imshow( CPU_Output_Image , cpu THImage); break; // Calling GPU fucntion //tStart = clock(); //Starting clock. thresholdWith CudaNoShared (gpu THImage, inputImage); //printf( Time taken: %.2fms , (double) (clock() - tStart)/(CLOCKS_PER_SEC/1000)); //Stopping and displaying time //Displaying Input and Output Images cvWaitKey(0); return 0; imshow( Input_Image , inputImage); imshow( GPU_Output_Image , gpu THImage); break; //Calling CPU and GPU function tStart = clock(); cpuFilter (cpuTHImage, input Image); printf( Time taken (CPU): %.2fms , (double) (clock() tStart) / (CLOCKS_PER_SEC / 1000)); //Stopping and displaying time tStart = clock(); thresholdWithCudaWithShared (gpuTHImage, inputImage); //printf( Time taken (GPU): %.2fms , (double) (clock() tStart)/(CLOCKS_PER_SEC/1000)); //Stopping and displaying time //Displaying Input and Output Images imshow( Input_Image , input Image); imshow( NoShared GPU_Output_Image , cpuTHImage); imshow( Shared GPU_Output_Image , gpuTHImage); } // cudaDeviceReset must be called before exiting in order for profiling and // tracing tools such as Nsight, and Visual Profiler to show complete traces. sudaStatus, cudaDeviceReset(); break; break; if (sudaStatus, != cudaSuccess) { fprintf(stderr, cudaDeviceReset failed! ); return 1; } //CPU Implemenation Code void cpuFilter (Mat& dest, const Mat& src) { // TODO: Write your CPU code here } // Helper function for using CUDA to add vectors in parallel. cudaError_t thresholdWithCudaNoShared (Mat & destImg, const Mat & sr.cImg) unsigned char *dev_src = 0; unsigned char *dey dst = 0; cudaErrort cudaStatus; // cuda, status variable for errors on GPU cudaEvent t start, stop; float time = 0; // TODO: register your events for GPU // These are your start and stop events to calculate your GPU performance // This is the gpu time // Choose which GPU to run on, change this on a multi-GPU system. sudaStatus. cudaSet Device(0); if (sudaStatus!= cudaSuccess) { fprintf(stderr, cudaSetDevice failed! Do you have a CUDA-capable GPU installed? ); goto Error; } // Allocate GPU buffers for two vectors (One input, one output) sudaStatus = sudaMalloc((void **)& dev_src, sizeof(unsigned char) * srcimg.rows. * srcima..co.ls.); if (cudaStatus. != cudaSuccess.) { } fprintf(stderr, cudaMallos failed! ); goto Error; //target image cudaStatus. = cudaMalloc((void **)& dey__dst, sizeof(unsigned char) * destimg.rows. * destimg.cols); if (cudaStatus != cudaSuccess) { } fprintf(stderr, cudaMallos failed! ); goto Error; // Copy input vectors from host memory to GPU buffers. sudaStatus = cudaMemcpy(dev_src, srcimg.data, sizeof(unsigned char) * srcima..rows. * srcimg.cols, cudaMemcpyHostToDevice); if (cudaStatus != cudaSuccess) { fprintf(stderr, sudaMemcRY. (CPU ->GPU) failed! ); goto Error; // Launch a kernel on the GPU with one thread for each element. dim3 block(K, K, 1); dim3 grid(srcima..cols. / K, srcima..rows. / K, 1); // TODO: record your start event on GPU gpukernel < < >> (dev dst, dev_src); // TODO: record your stop event on GPU // TODO: Synchronize stop event // TODO: calculate the time ellaped on GPU printf( Global Memory time=%3.2f ms , time); // Check for any errors launching the kernel cudaStatus = cudaGetLastError(); // invoking the kernel if (cudaStatus != cudaSuccess) { fprintf(stderr, addKernel launch failed: %s , sudaGetErrorString(cudaStatus.)); goto Error; Error: } // cudaDeviceSynchronize waits for the kernel to finish, and returns // any errors encountered during the launch. sudaStatus = sudaReviseSynchronize(); if (cudaStatus. != cudaSuccess) { fprintf(stderr, cudaDeviceSynchronize returned error code %d after launching addKernel! , cudaStatus.); goto Error; } // Copy output vector from GPU buffer to host memory. sudaStatus = cudaMemcpy(destImg.data, dev dst, sizeof(unsigned char) * destimg.rows. * destimg.cols, sudaMemcpyDeviceToHost); if (cudaStatus != cudaSuccess) { fprintf(stderr, cudaMemcRY. (GPU CPU) failed! ); goto Error; } cudaFree (dev_src); cudaFree (dey_dat); return cudaStatus; SudaErrort threshold With Cudawithshared (Mat & desting, const Mat & s.r.cImg) unsigned char *dev_src = 0; unsigned char *dey_dst = 0; cudaError_t sudaStatus; cudaEvent t start, stop; float time = 0; // cuda, status variable for errors on GPU // These are your start and stop events to calculate your GPU performance // This is the gpu time // TODO: register your events for GPU // Choose which GPU to run on, change this on a multi-GPU system. Sudastatus. cudaSet Device(0); if (sudaStatus != cudaSuccess) { fprintf(stderr, cudaSetDevice failed! Do you have a CUDA-capable GPU installed? ); goto Error; } // Allocate GPU buffers for two vectors (One input, one output) cudaStatus = sudaMalloc((void**) & dev_src, sizeof(unsigned char) * srcimg.rows. * srcimg.cols); if (cudaStatus. != cudaSuccess) { fprintf(stderr, cudaMalloc, failed! ); goto Error; //target image cudaStatus = cudaMalloc((void **)& dey dst, sizeof(unsigned char) * destimg.rows. * destimg.cols); } if (cudaStatus != cudaSuccess) { fprintf(stderr, cudaMallas failed! ); goto Error; // Copy input vectors from host memory to GPU buffers. cudaStatus = cudaMemcpy(dev_src, srcimg.data, sizeof(unsigned char) * srcimg..rows. * srcimg.cols, cudaMemcpyHostToDevice); if (cudastatus. != cudaSuccess) { fprintf(stderr, cudaMemcpy. (CPU ->GPU) failed! ); Error: } // Launch a kernel on the GPU with one thread for each element. dim3 block (K, K, 1); dim3 grid (srcimg.cols. /K, srcimg.rows / K, 1); // TODO: record your start event on GPU gpukernelTiled < < >> (dev dst, dev_src); // TODO: record your stop event on GPU // TODO: Synchronize stop event // TODO: calculate the time ellaped on GPU printf( Global Memory time=%3.2f ms , time); // Check for any errors launching the kernel sudastatus. cudaGetLastError(); if (cudaStatus. != cudaSuccess) { fprintf(stderr, addKernel launch failed: %s , cudaGetErrorString(sudaStatus.)); goto Error; // invking the kernel with tiled shared memory } // cudaDeviceSynchronize waits for the kernel to finish, and returns // any errors encountered during the launch. sudastatus. sudaDeviceSynchronize(); if (cudaStatus != cudaSuccess) { fprintf(stderr, cudaDeviceSynchronize returned error code %d after launching addKernel! , cudaStatus); goto Error; } // Copy output vector from GPU buffer to host memory. cudaStatus = cudaMemcpy(destImg.data, dev dst, sizeof(unsigned char) * destimg.rows. * destimg.cols, cudaMemcpyDeviceToHost); if (cudaStatus != cudaSuccess) { fprintf(stderr, sudaMemcRY. (GPU -> CPU) failed! ); goto Error; } cudaFree (dev_src); cudaFree (dey.dst.); return cudaStatus; Input Image CPU_Output_Image
Step by Step Solution
There are 3 Steps involved in it
Answer import cv2 import numpy as np Load the input image inputimage cv2imreadinputjpg Create a ... View full answer

Get step-by-step solutions from verified subject matter experts