

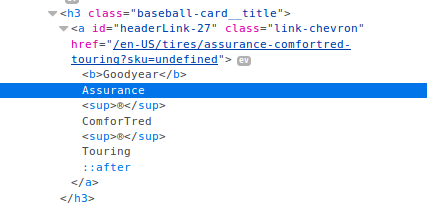
Question: I am scraping this webpage using python and beautiful soup. There are several tire names I want to scrape, like Goodyear Assurance Comfortred Touring. There
I am scraping this webpage using python and beautiful soup. There are several tire names I want to scrape, like Goodyear Assurance Comfortred Touring. There are rougly 30 of these on the page with the same html structure, that being class name is baseball-card___title and have a class link-chevron, but the a id's are all different. How do I scrape this information for all the tires?
import requests import csv from datetime import datetime from bs4 import BeautifulSoup
# for tire and review page
# download the page #myurl = requests.get("https://en.wikipedia.org/wiki/Goodyear_Tire_and_Rubber_Company") myurl = requests.get("https://www.goodyearautoservice.com/en-US/tires/all-season")
# create BeautifulSoup object soup = BeautifulSoup(myurl.text, 'html.parser')
ev Goodyear Assurance esup ComforTred Touring ::after /h3>
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts