

Question: i generated a model with random data like so: rca = ['High', 'Medium', 'Low'] cr = ['Positive', 'Negative'] ms = ['Married', 'Single', 'Not Specified'] nod
i generated a model with random data like so:
rca = ['High', 'Medium', 'Low']
cr = ['Positive', 'Negative']
ms = ['Married', 'Single', 'Not Specified']
nod = ['No dependent', 'Less than two', 'More than two']
yoe = np.random.randint(0, 8, size=30)
mi = ['Very Low', 'Low', 'Moderate', 'High', 'Very High']
me = ['Very Low', 'Low', 'Moderate', 'High', 'Very High']
df = pd.DataFrame()
a = []
b = []
c = []
d = []
e = []
f = []
for i in range(30):
a.append(random.choice(rca))
b.append(random.choice(cr))
c.append(random.choice(ms))
d.append(random.choice(nod))
e.append(random.choice(mi))
f.append(random.choice(me))
df['Credit Rating'] = b
df['Requested credit amount'] = a
df['Marital status'] = c
df['Number of Dependents'] = d
df['Years of education after high school'] = yoe.tolist()
df['Monthly income'] = e
df['Monthly expense'] = f
with this data I am unable to fit logistic regression. Below is the error , please help in resolving
![1gr = LogisticRegression() pipe2=make_pipeline (scaler,lgr) pipe2.fit((x_train,y_train)) ValueError Input In [31], in ()](https://dsd5zvtm8ll6.cloudfront.net/si.experts.images/questions/2024/02/65c36d67625a8_34365c36d673172a.jpg)
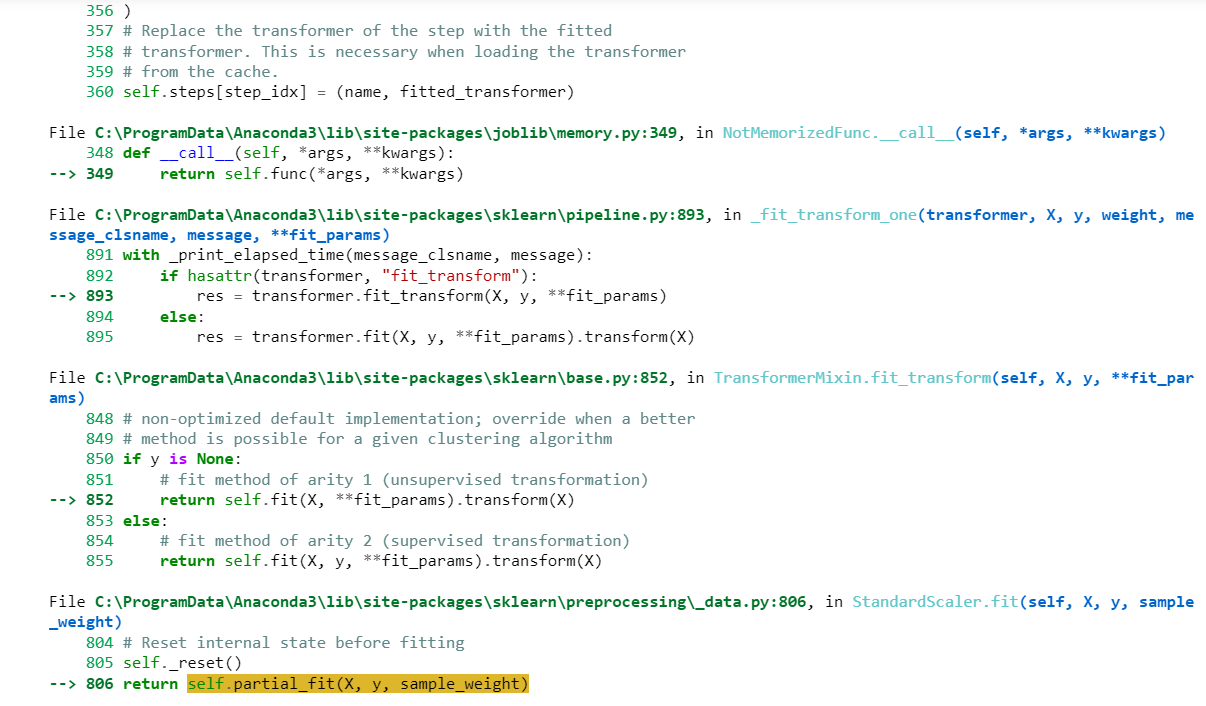
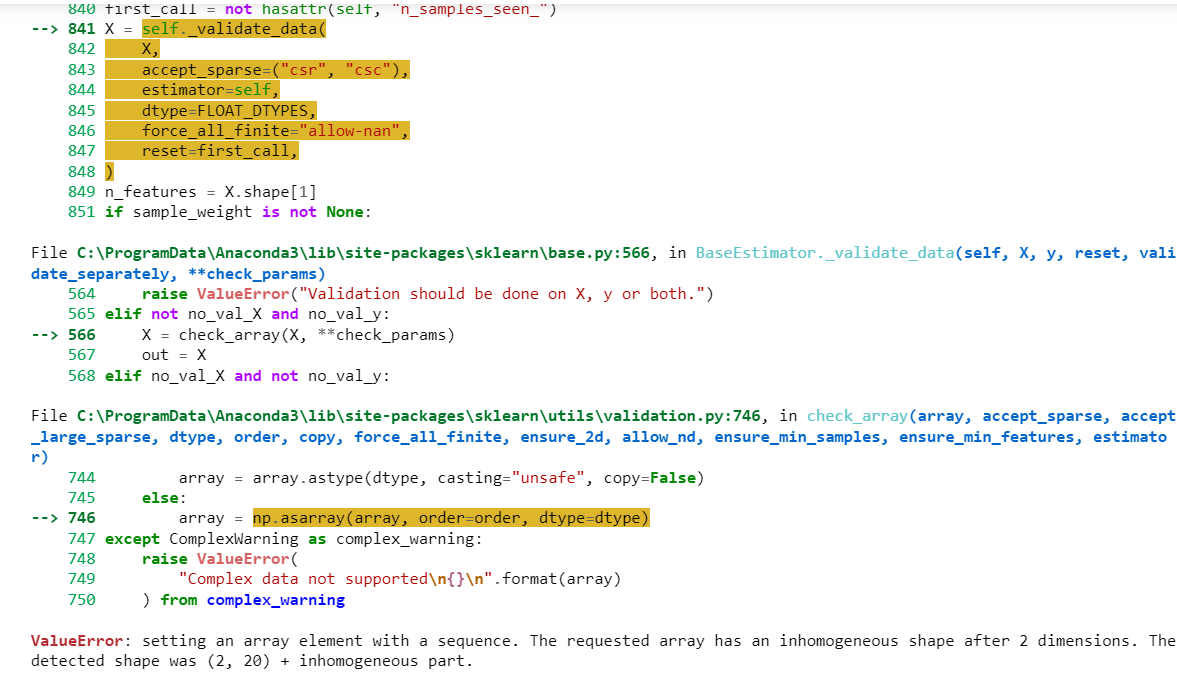
1gr = LogisticRegression() pipe2=make_pipeline (scaler,lgr) pipe2.fit((x_train,y_train)) ValueError Input In [31], in () --> 1 pipe2.fit((x_train,y_train)) File C:\ProgramData\Anaconda3\lib\site-packages\sklearn\pipeline.py: 390, in Pipeline.fit (self, x, y, **fit_params) 364 """Fit the model. 365 366 Fit all the transformers one after the other and transform the (...) 387 388 Pipeline with fitted steps. 389 fit_params_steps = self._check_fit_params (**fit_params) --> 390 Xt= self._fit(x, y, **fit_params_steps) 391 with _print_elapsed_time("Pipeline", self._log_message(len(self.steps) - 1)): 392 if self._final_estimator != "passthrough": || || || Traceback (most recent call last) File C:\ProgramData\Anaconda3\lib\site-packages\sklearn\pipeline.py:348, in Pipeline._fit(self, X, y, **fit_params_steps 346 cloned_transformer = clone (transformer) 347 # Fit or load from cache the current transformer 351 352 --> 348 X, fitted_transformer = fit_transform_one_cached ( 349 cloned_transformer, 350 X, y, None, 353 message_clsname="Pipeline", 354 355 356 ) message=self._log_message(step_idx), **fit_params_steps [name],
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts