

Question: I need a solution quickly please Markov Decision Processes The following figure shows an MDP with N states. All states have two actions (North and
I need a solution quickly please 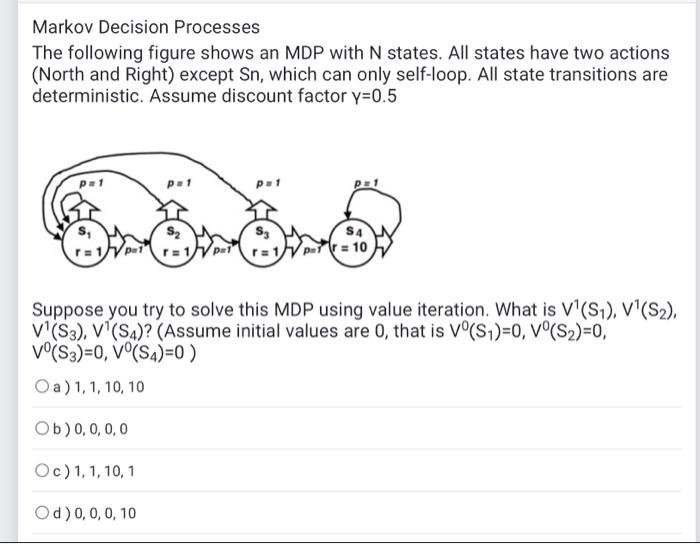
Markov Decision Processes The following figure shows an MDP with N states. All states have two actions (North and Right) except Sn, which can only self-loop. All state transitions are deterministic. Assume discount factor y=0.5 Suppose you try to solve this MDP using value iteration. What is V1(S1),V1(S2), V1(S3),V(S4) ? (Assume initial values are 0 , that is V0(S1)=0,V0(S2)=0, V0(S3)=0,V0(S4)=0) a) 1,1,10,10 b) 0,0,0,0 c) 1,1,10,1 d) 0,0,0,10
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock