

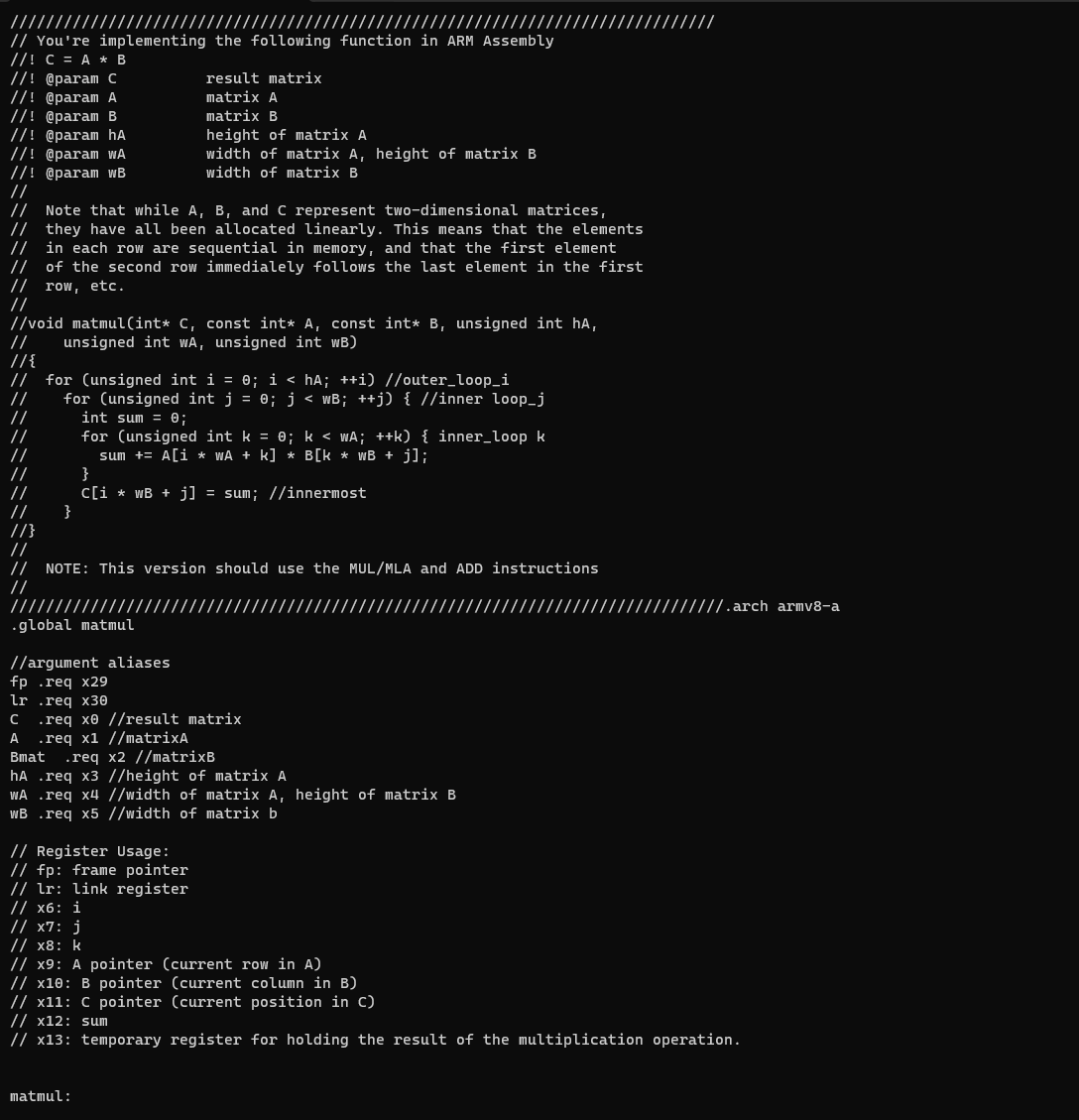
Question: Implementation of matrix multiplcation in Armv 8 using the built in operations in the architecture. You may assume that the intermediate and final results can
Implementation of matrix multiplcation in Armv using the built in operations in the architecture. You may assume that the intermediate and final results can be represented using butoverflow does not occur I have to translate this C code to armv assembly and have doen this code, but all i get is zeros in my matrix and i have to test for martices of size and You're implementing the following function in ARM Assembly
@param C result matrix
@param A matrix A
@param B matrix B
@param hA height of matrix A
@param wA width of matrix height of matrix
@param wB width of matrix
Note that while and represent twodimensional matrices,
they have all been allocated linearly. This means that the elements
in each row are sequential in memory, and that the first element
of the second row immedialely follows the last element in the first
row
void matmulint const int const int unsigned int
unsigned int unsigned int
for unsigned int ;::;
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock