

Question: In Python 3: Part 1: Data preparation (5 Points) Create a data preparation and cleaning function that does the following Has a single input that
In Python 3:
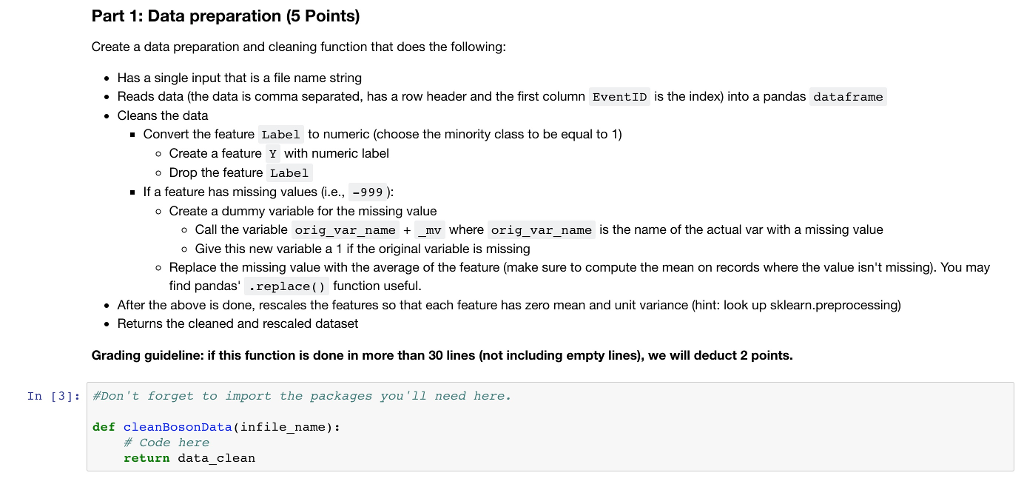
Part 1: Data preparation (5 Points) Create a data preparation and cleaning function that does the following Has a single input that is a file name string Reads data (the data is comma separated, has a row header and the first column EventID is the index) into a pandas dataframe Cleans the data Convert the feature Label to numeric (choose the minority class to be equal to 1) Create a feature Y with numeric label o Drop the feature Label If a feature has missing values (i.e., -999 ) o Create a dummy variable for the missing value Call the variable orig_var_name _mv where orig_var_name is the name of the actual var with a missing value o Give this new variable a 1 if the original variable is missing o Replace the missing value with the average of the feature (make sure to compute the mean on records where the value isn't missing). You may find pandas' .replace() function useful. After the above is done, rescales the features so that each feature has zero mean and unit variance (hint: look up sklearn.preprocessing) Returns the cleaned and rescaled dataset Grading guideline: if this function is done in more than 30 lines (not including empty lines), we will deduct 2 points. In [3]: #Don't forget to import the packages you'll need here. def cleanBosonData(infile_name): # code here return data_clean Part 1: Data preparation (5 Points) Create a data preparation and cleaning function that does the following Has a single input that is a file name string Reads data (the data is comma separated, has a row header and the first column EventID is the index) into a pandas dataframe Cleans the data Convert the feature Label to numeric (choose the minority class to be equal to 1) Create a feature Y with numeric label o Drop the feature Label If a feature has missing values (i.e., -999 ) o Create a dummy variable for the missing value Call the variable orig_var_name _mv where orig_var_name is the name of the actual var with a missing value o Give this new variable a 1 if the original variable is missing o Replace the missing value with the average of the feature (make sure to compute the mean on records where the value isn't missing). You may find pandas' .replace() function useful. After the above is done, rescales the features so that each feature has zero mean and unit variance (hint: look up sklearn.preprocessing) Returns the cleaned and rescaled dataset Grading guideline: if this function is done in more than 30 lines (not including empty lines), we will deduct 2 points. In [3]: #Don't forget to import the packages you'll need here. def cleanBosonData(infile_name): # code here return data_clean
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts