

Question: In this lab you will use the Performance API (PAPI) to study the performance of the matrix multiplication of two matrices B and C of
In this lab you will use the Performance API (PAPI) to study the performance of the matrix multiplication of two matrices B and C of type double.
A = B * C
A, B and C are all M x M matrices, where M = 1024.
You may use the program you wrote in Lab 3 and add calls to PAPI to collect data such as floating point operations (PAPI_FP_OPS) and data cache misses (PAPI_L1_DCM).
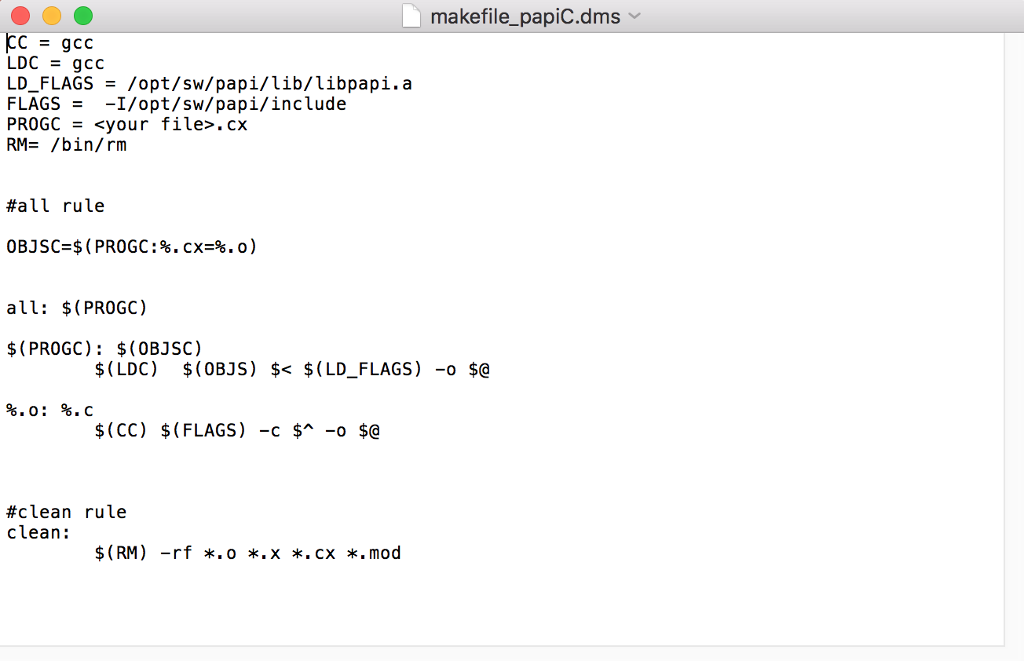
The PAPI installation is at /opt/sw/papi.
Look at the attached makefilefor the changes to the FLAGS and LD_FLAGS arguments.
The program will NOT use OMP. In other words, you will not parallelize matrix multiplication. You will just collect statistics and contents of some counters. Hopefully you can collect statistics on data cache misses. Next you modify the algorithm so you do are not optimizing the cache behavior and run the program again. Collect the statistics one more time compare the statistics from both the runs. Write a report explaining the differences in the statistics, if any, and the reasons for the differences.
LAB 3:
#include
#include
#include "omp.h"
double** allocate_matrix(int size) {
double * vals = (double *)malloc(size * size * sizeof(double));
double ** ptrs = (double **)malloc(size * sizeof(double*));
int i;
for(i = 0; i
ptrs[i] = &vals[i * size];
}
return ptrs;
}
void assignMat(double **matrix, int size) {
int i, j;
for(i = 0; i
for(j = 0; j
matrix[i][j] = 2.0;
}
}
}
void freeMat(double **matrix, int size) {
int i;
for(i = 0; i
free(matrix[i]);
}
free(matrix);
}
void printMat(double **matrix, int size) {
int i, j;
for(i = 0; i
for(j = 0; j
printf("%lf", matrix[i][j]);
}
printf("%lf", matrix[i][j]);
putchar(' ');
}
}
double** matMult(double **matrix1, double **matrix2, int size) {
int i, j, k;
double **matrix3;
double sum = 0;
#pragma omp parallel for shared(matrix1, matrix2, matrix3, chunksize) private(i, j, k, sum) schedule(static, chunksize)
for(i = 0; i
for(j = 0; j
sum = 0;
for(k = 0; k
sum += matrix1[i][k] * matrix2[k][j];
}
matrix3[i][j] = sum;
}
}
}
int main(int argc, char * argv[]) {
double** matrix1;
double** matrix2;
double** matrix3;
int size; // Number of threads. Get from command line
int chunksize, numthreads;
if(argc != 3) {
fprintf(stderr, "%s
return -1;
}
size = atoi(argv[1]);
numthreads = atoi(argv[2]);
if(size % numthreads != 0) {
fprintf(stderr, "matrix size %d must be a multiple of number of threads %d! ", size, numthreads);
return -1;
}
omp_set_num_threads(numthreads);
chunksize = size / numthreads;
matrix1 = allocate_matrix(size);
matrix2 = allocate_matrix(size);
matrix3 = allocate_matrix(size);
assignMat(matrix1, size);
assignMat(matrix2, size);
if(size
printMat(matrix1, size);
printMat(matrix2, size);
}
matrix3 = matMult(matrix1, matrix2, size);
printMat(matrix3, size);
freeMat(matrix2, size);
free(matrix1);
free(matrix3);
return 0;
}
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts