

Question: In this question we will compare two different architectures . The first is x86: an extended accumulator, CISC architecture with variable-length instructions and 32-bit data

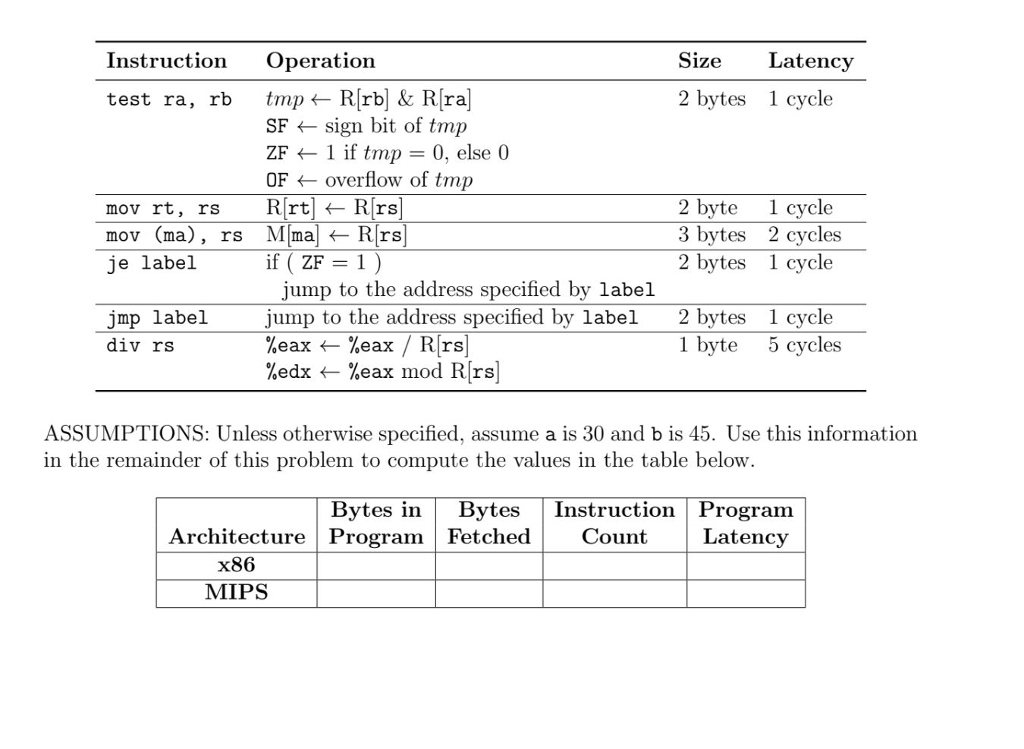


In this question we will compare two different architectures . The first is x86: an extended accumulator, CISC architecture with variable-length instructions and 32-bit data values . The second is MIPS, a register-register RISC architecture with 32-bit fixed-length in structions and 32-bit data values Consider the following C code which takes two integers (a and b) as inputs, computes the Greatest Common Divisor (GCD) between them, and stores the result in memory. 1 void gcd( int a, int b, int* result) 3 while (bl=0){ 4 int temp b; b=a%b; a temp ; 8 *result = a; If we were to take this code and compile it on an x86 machine (like your laptop), we would get the following assembly code. You can try this at home. I loop : test %esi, %esi 2 je End mov %eax, mov %edi, div %esi mov %esi, jmp loop mov (%rcx), %edi %esi 4 %eax 6 7 8 End : %edi If you were to try compiling this yourself, you would get the above output. In this assembly, %edi contains a. %esi contains b, and %rcx contains result. All other similar terms are names referring to registers in the processor. The table at the top of the next page describes the operation of the x86 instructions as well as the size of the encoding and the latency of the instruction execution In this question we will compare two different architectures . The first is x86: an extended accumulator, CISC architecture with variable-length instructions and 32-bit data values . The second is MIPS, a register-register RISC architecture with 32-bit fixed-length in structions and 32-bit data values Consider the following C code which takes two integers (a and b) as inputs, computes the Greatest Common Divisor (GCD) between them, and stores the result in memory. 1 void gcd( int a, int b, int* result) 3 while (bl=0){ 4 int temp b; b=a%b; a temp ; 8 *result = a; If we were to take this code and compile it on an x86 machine (like your laptop), we would get the following assembly code. You can try this at home. I loop : test %esi, %esi 2 je End mov %eax, mov %edi, div %esi mov %esi, jmp loop mov (%rcx), %edi %esi 4 %eax 6 7 8 End : %edi If you were to try compiling this yourself, you would get the above output. In this assembly, %edi contains a. %esi contains b, and %rcx contains result. All other similar terms are names referring to registers in the processor. The table at the top of the next page describes the operation of the x86 instructions as well as the size of the encoding and the latency of the instruction execution
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts