Question: Need help getting started on these questions. I am supposed to add code where it says implement me and write the answer where it says
Need help getting started on these questions. I am supposed to add code where it says "implement me" and write the answer where it says answer in one or two line.
Need to fill in the "Implement me" parts and the write answer in one or two lines
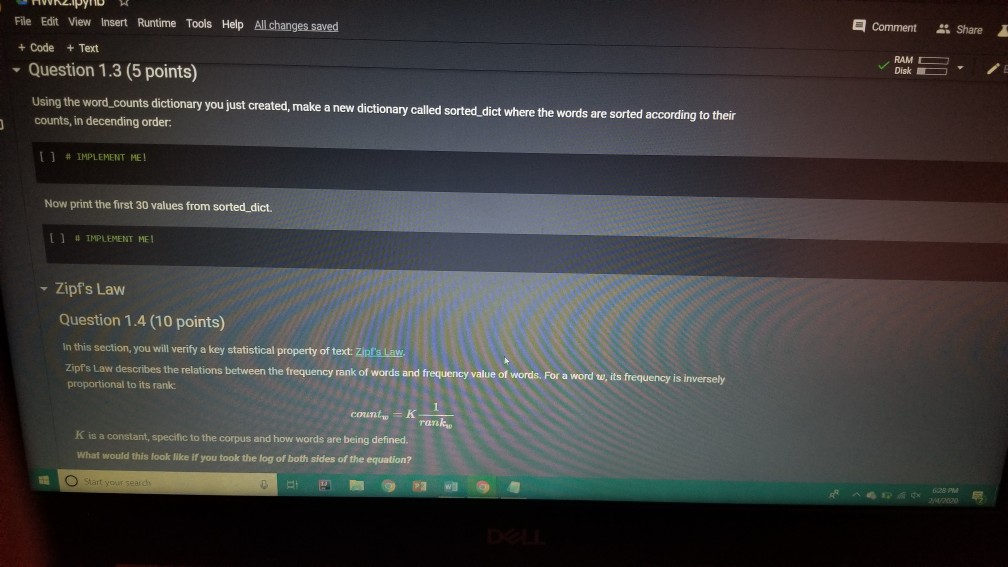
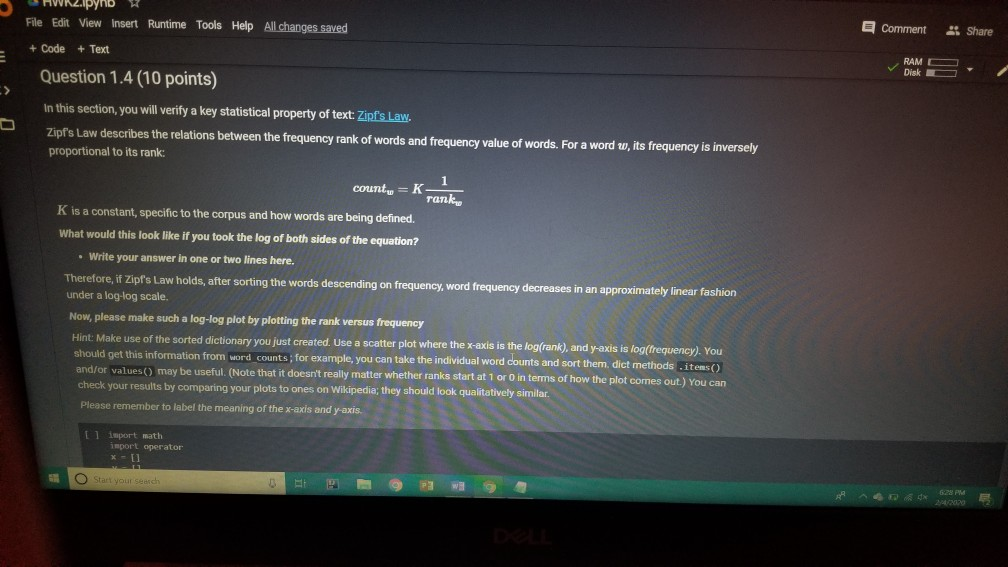
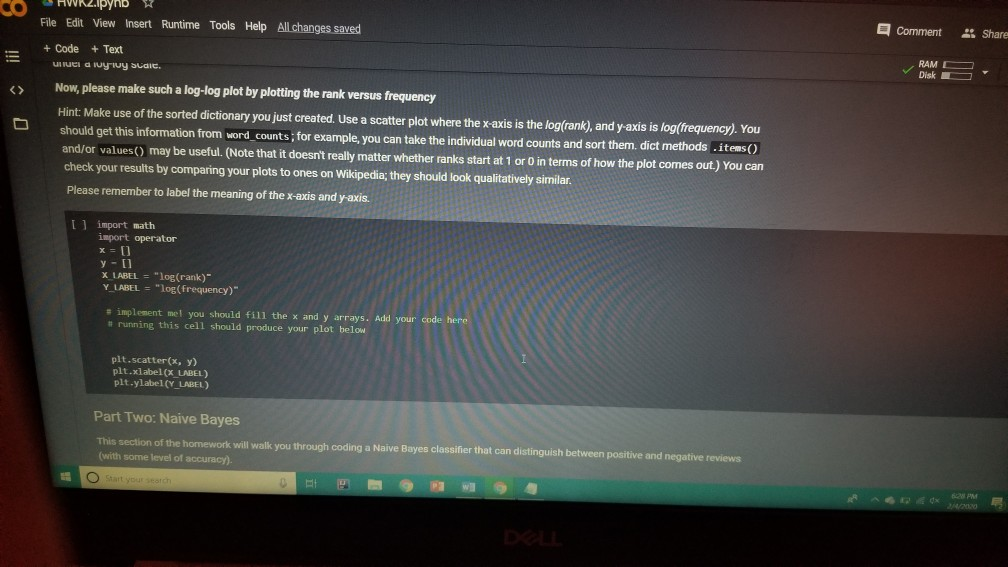
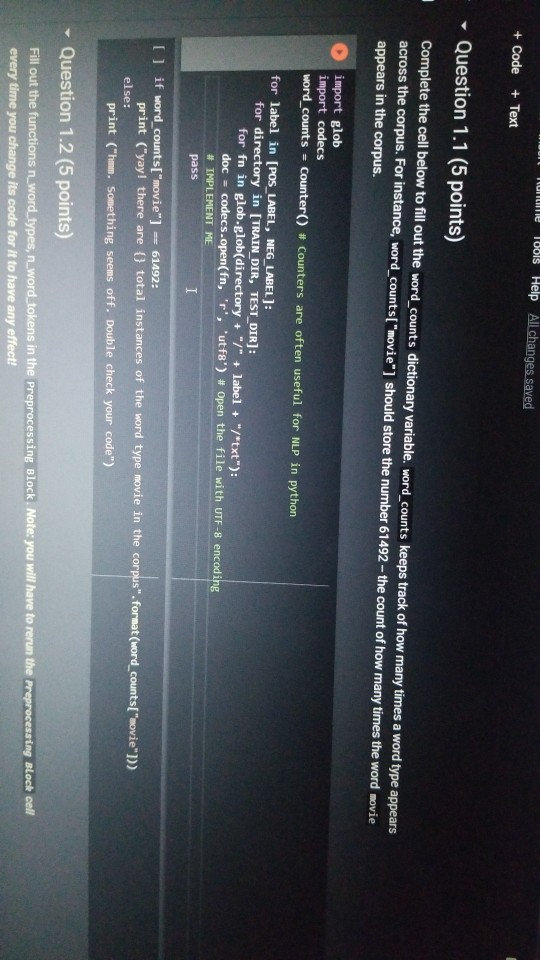
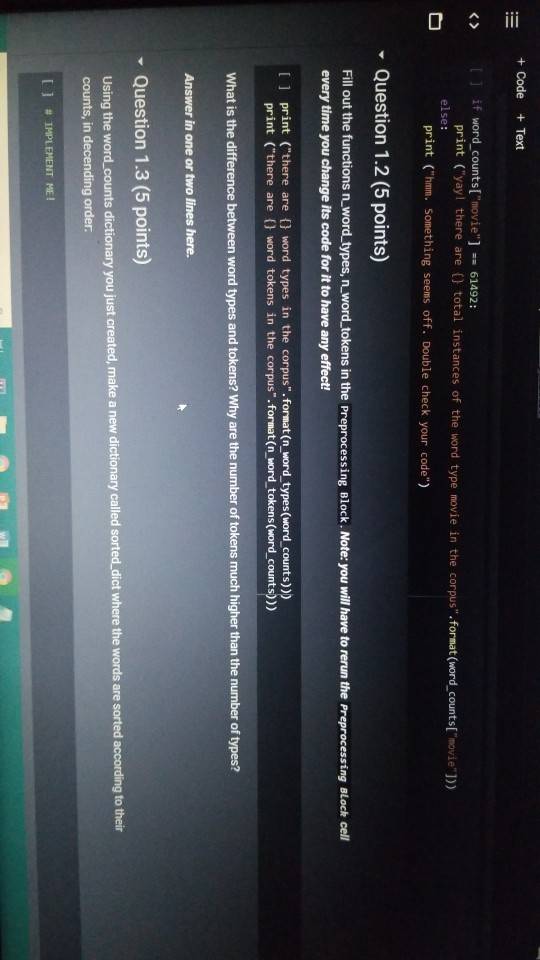
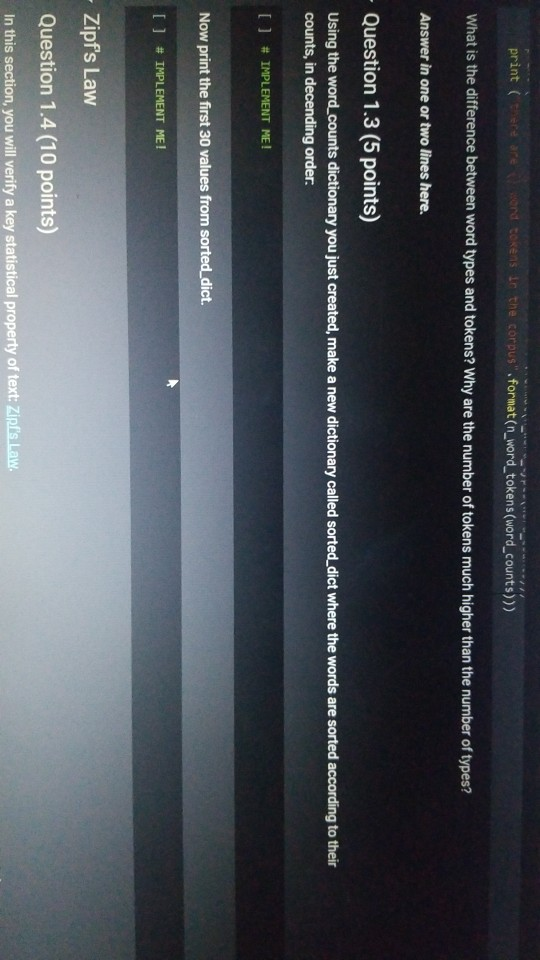
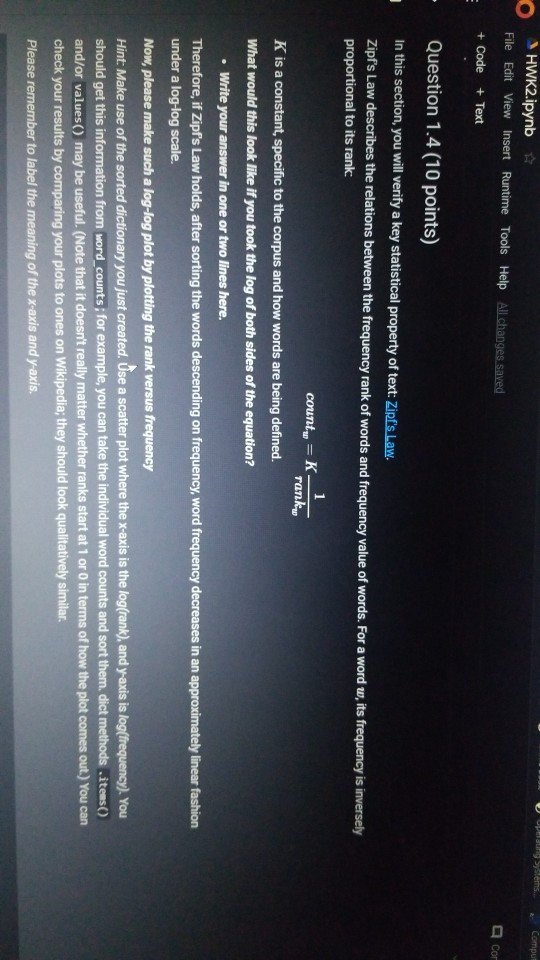
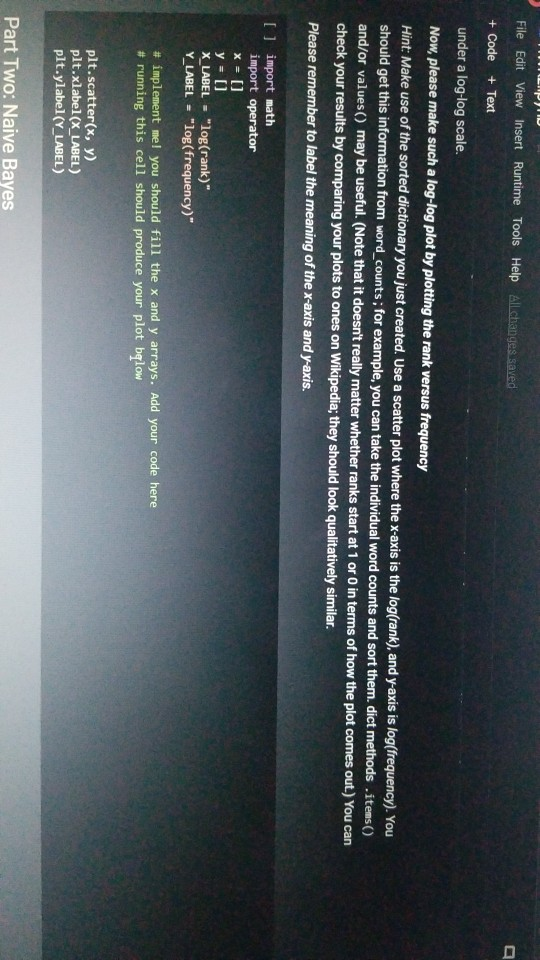
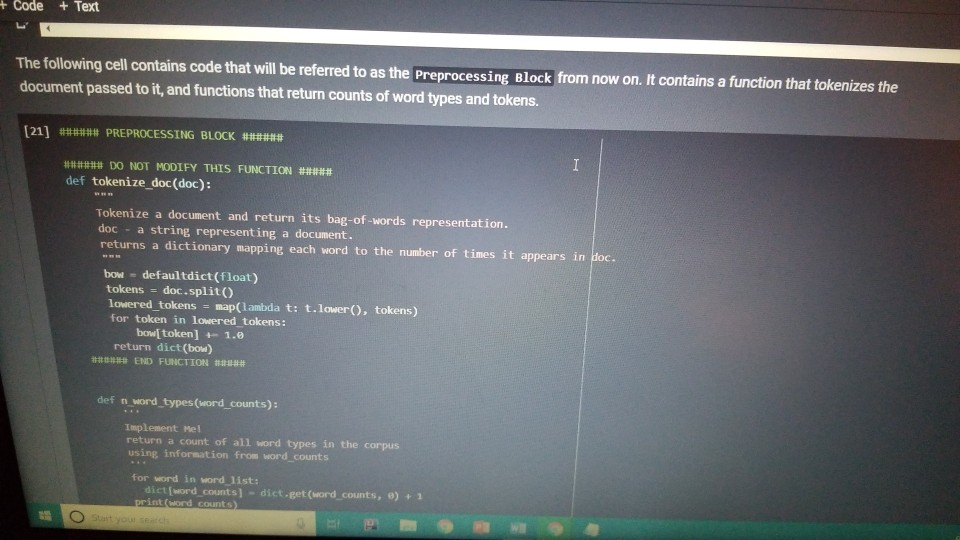
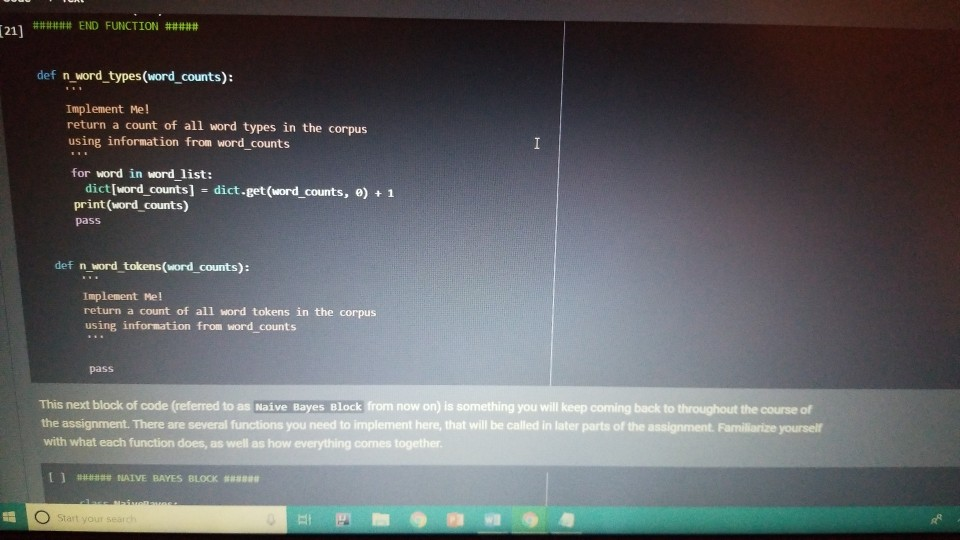
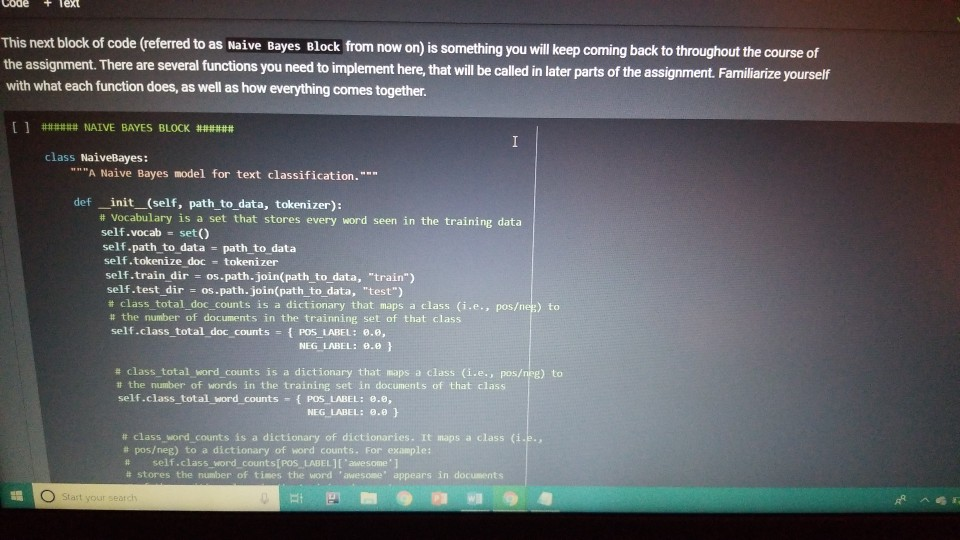
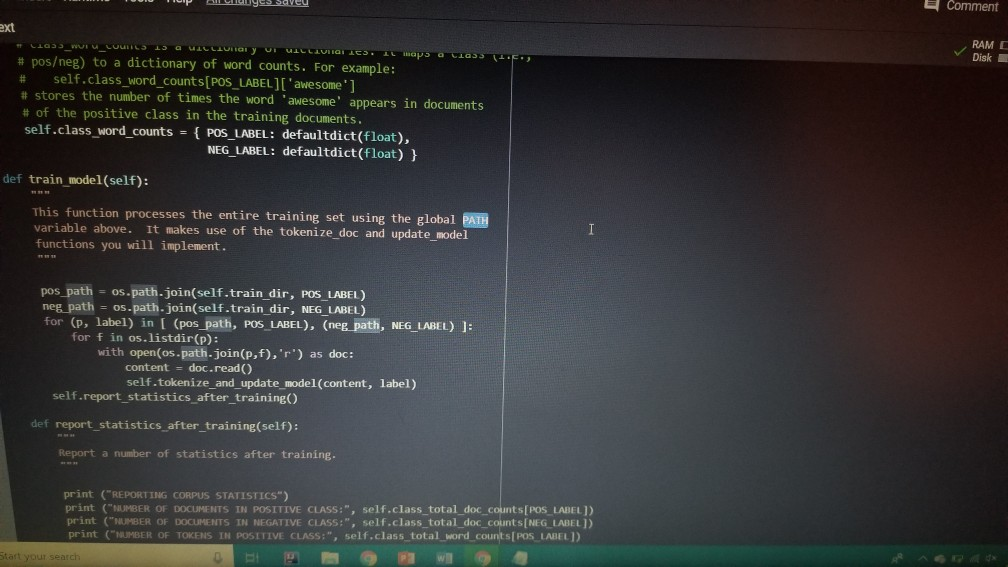
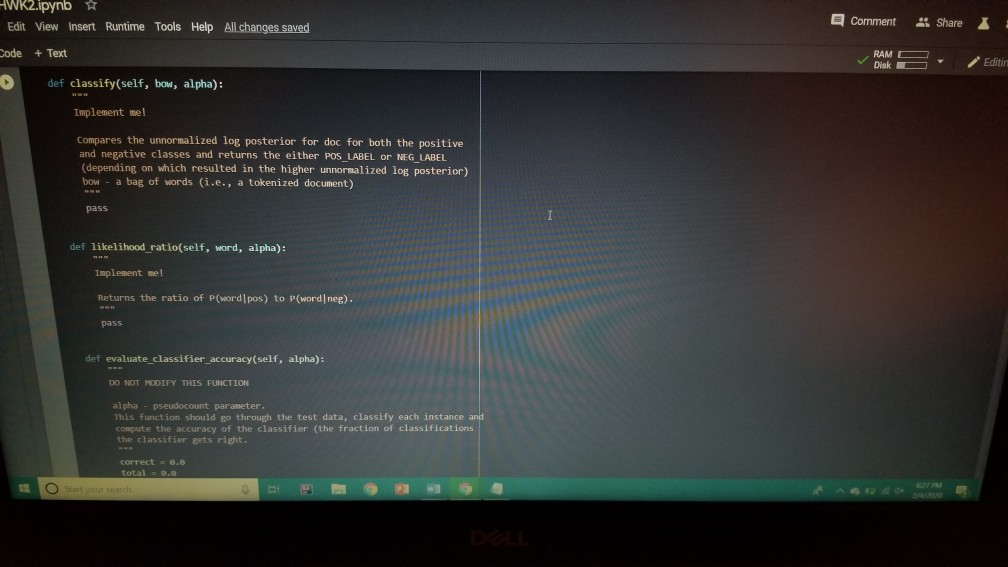
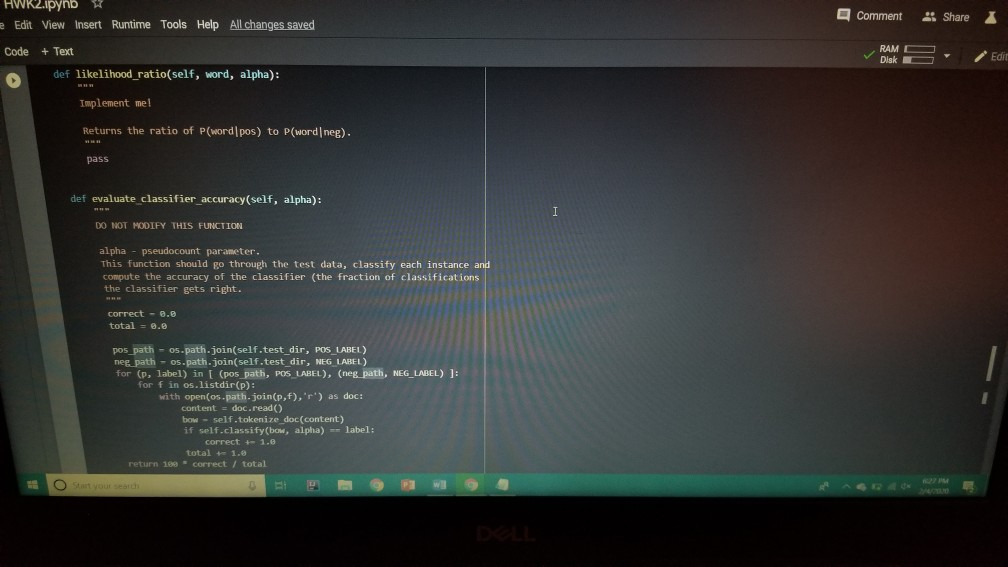
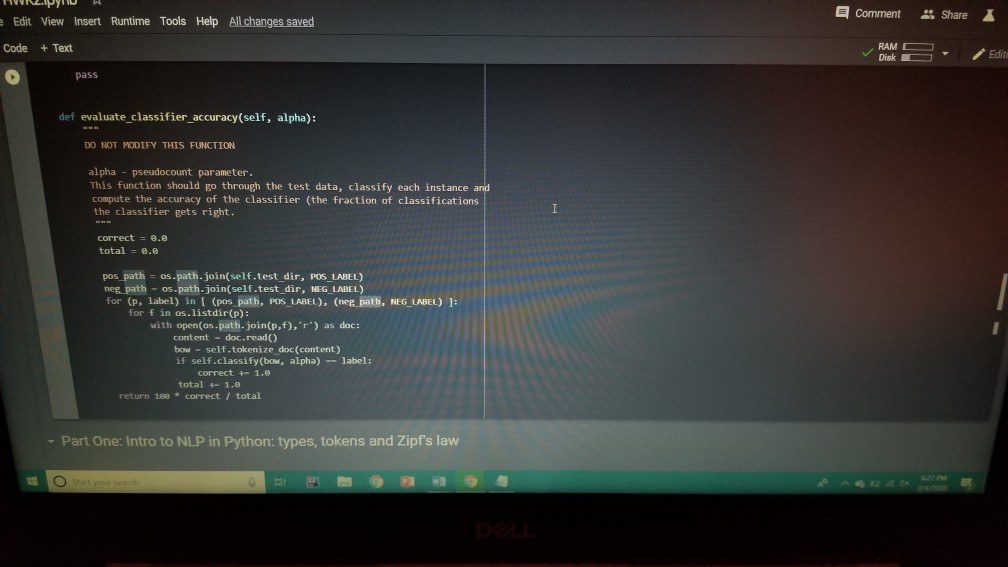
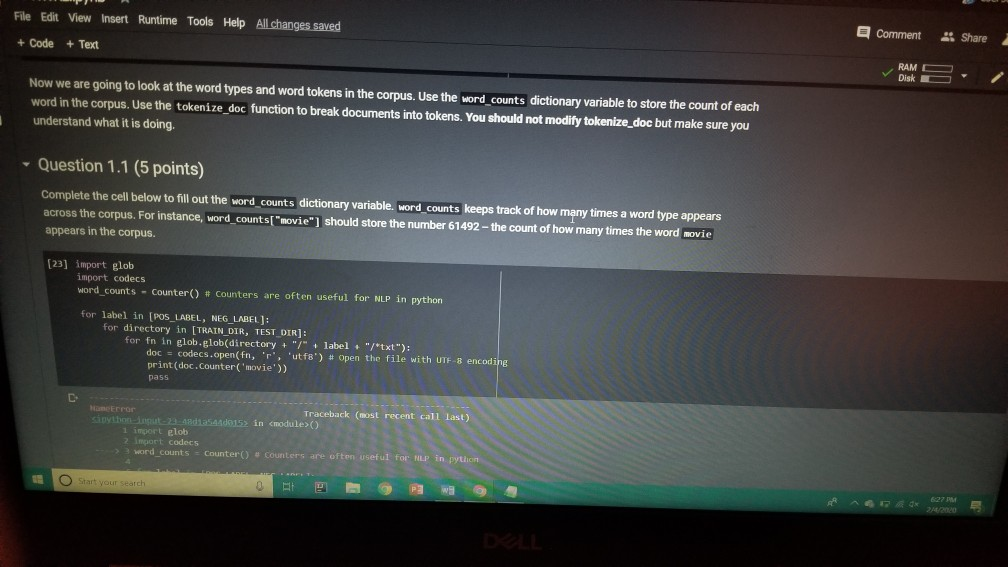
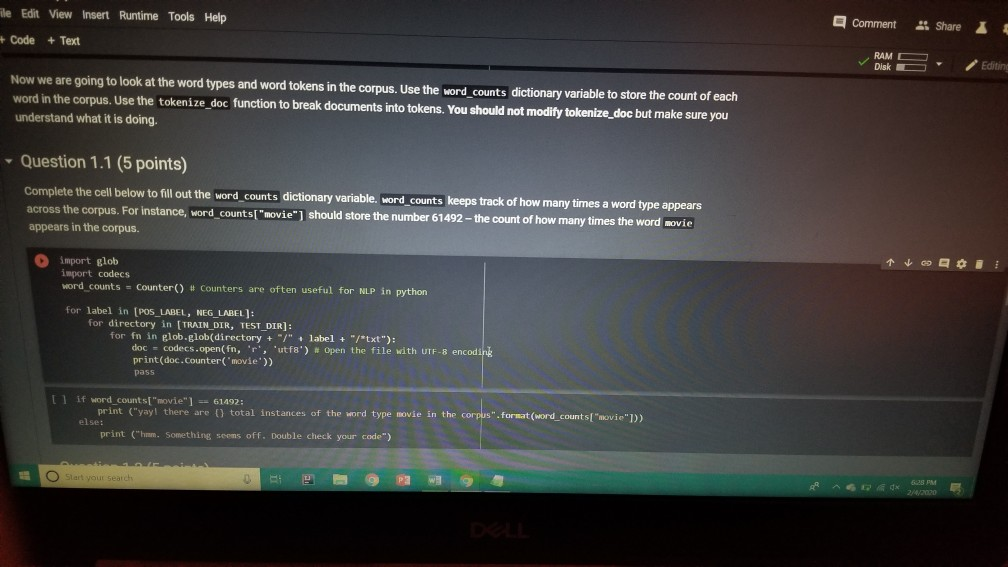
1001 Hue Tools Help All changes saved + Code + Text - - Question 1.1 (5 points) Complete the cell below to fill out the word_counts dictionary variable, word_counts keeps track of how many times a word type appears across the corpus. For instance, word_counts("movie") should store the number 61492 - the count of how many times the word movie appears in the corpus. import glob import codecs word_counts - Counter() # Counters are often useful for NLP in python for label in [POS_LABEL, NEG_LABEL): for directory in [TRAIN_DIR, TEST DIR]: for fn in glob.glob(directory + "/" + label + "/"txt"): doc - codecs.open(fn, 'r', 'utf8') # Open the file with UTF-8 encoding # IMPLEMENT ME pass U if word_counts["movie"] = 61492: print ("yay! there are t) total instances of the word type movie in the corpus".Format(word_counts("movie"))) else: print ("hmm. Something seems off. Double check your code") - Question 1.2 (5 points) Fill out the functions n word_types, n.word_tokens in the Preprocessing Block. Note: you will have to rerun the preprocessing Block cell every time you change its code for it to have any effect! ji + Code + Text [ if word_counts["movie" ] -- 61492: print (yayl there are 0 total instances of the word type movie in the corpus".Format(word_counts ["movie" 1) else: print ("hmm. Something seems off. Double check your code") o Question 1.2 (5 points) Fill out the functions n_word_types, n_word_tokens in the Preprocessing Block. Note: you will have to rerun the Preprocessing Block cell every time you change its code for it to have any effect! D print ("there are {} word types in the corpus".Format(n_word_types(word_counts))) print ("there are () word tokens in the corpus".Format(n_word_tokens(word_counts))) What is the difference between word types and tokens? Why are the number of tokens much higher than the number of types? Answer in one or two lines here. - Question 1.3 (5 points) Using the word counts dictionary you just created, make a new dictionary called sorted_dict where the words are sorted according to their counts, in decending order. [] # IMPLEMENT ME! print (r o nd tokensIr the corpus'.format(n_word_tokens(word_counts)>> What is the difference between word types and tokens? Why are the number of tokens much higher than the number of types? Answer in one or two lines here. - Question 1.3 (5 points) Using the word_counts dictionary you just created, make a new dictionary called sorted_dict where the words are sorted according to their counts, in decending order. O # IMPLEMENT ME! Now print the first 30 values from sorted_dict. [] # IMPLEMENT ME! - Zipf's Law Question 1.4 (10 points) In this section, you will verify a key statistical property of text: Zipf's Law. O lang systems. e Comput HWK2.ipynb File Edit View Insert Runtime Tools Help All changes saved a com + Code + Text Question 1.4 (10 points) In this section, you will verify a key statistical property of text: Zipf's Law. Zipf's Law describes the relations between the frequency rank of words and frequency value of words. For a word w, its frequency is inversely proportional to its rank: count = K- rank, K is a constant, specific to the corpus and how words are being defined. What would this look like if you took the log of both sides of the equation? Write your answer in one or two lines here. Therefore, if Zipf's Law holds, after sorting the words descending on frequency, word frequency decreases in an approximately linear fashion under a log-log scale. Now, please make such a log-log plot by plotting the rank versus frequency Hint Make use of the sorted dictionary you just created. Use a scatter plot where the x-axis is the log(rank), and y-axis is 109 liegen should get this information from word counts, for example, you can take the individual word counts and sort them, dictmemester and/or values() may be useful. (Note that it doesn't really matter whether ranks start at 1 or 0 in terms of how the plot comes out.) You can check your results by comparing your plots to ones on Wikipedia; they should look qualitatively similar Please remember to label the meaning of the x-axis and y-axis. File Edit View Insert Runtime Tools Help All changes saved + Code + Text under a log-log scale. Now, please make such a log-log plot by plotting the rank versus frequency Hint: Make use of the sorted dictionary you just created. Use a scatter plot where the x-axis is the log(rank), and y-axis is log(frequency). You should get this information from word_counts; for example, you can take the individual word counts and sort them. dict methods .items() and/or values() may be useful. (Note that it doesn't really matter whether ranks start at 1 or 0 in terms of how the plot comes out.) You can check your results by comparing your plots to ones on Wikipedia; they should look qualitatively similar. Please remember to label the meaning of the x-axis and y-axis. [] import math import operator x = [] y = [] X_LABEL = "log(rank)" Y_LABEL = "log(frequency)" # implement me! you should fill the x and y arrays. Add your code here #running this cell should produce your plot below plt.scatter(x, y) plt.xlabel(X_LABEL) plt.ylabel (Y_LABEL) Part Two: Naive Bayes Code + Text The following cell contains code that will be referred to as the Preprocessing Block from now on. It contains a function that tokenizes the document passed to it, and functions that return counts of word types and tokens. [21] ****** PREPROCESSING BLOCK #***** #**### DO NOT MODIFY THIS FUNCTION ##### def tokenize_doc(doc): Tokenize a document and return its bag-of-words representation. doc - a string representing a document. returns a dictionary mapping each word to the number of times it appears in doc. bow - defaultdict(float) tokens = doc.split() lowered_tokens = map(lambda t: t.lower(), tokens) for token in lowered tokens: bow[token] + 1.0 return dict(bow) # END FUNCTION def n word_types(word_counts): Implement Mel return a count of all word types in the corpus using information from word_counts for word in word list: die word countsdicteet (word counts, o print word counts) Start you O 121] #*****# END FUNCTION #***# def n_word_types(word_counts): Implement Me! return a count of all word types in the corpus using information from word_counts for word in word list: dict[word_counts] = dict.get(word_counts, e) + 1 print(word_counts) pass def n_word_tokens(word_counts): Implement Me! return a count of all word tokens in the corpus using information from word_counts pass This next block of code (referred to as Naive Bayes Block from now on) is something you will keep coming back to throughout the course of the assignment. There are several functions you need to implement here, that will be called in later parts of the assignment. Familiarize yourself with what each function does, as well as how everything comes together. O NAIVE BAYES BLOCK *** O Start your search Code + Text This next block of code (referred to as Naive Bayes Block from now on) is something you will keep coming back to throughout the course of the assignment. There are several functions you need to implement here, that will be called in later parts of the assignment. Familiarize yourself with what each function does, as well as how everything comes together. [1#****# NAIVE BAYES BLOCK ##**## class NaiveBayes: A Naive Bayes model for text classification, def __init__(self, path_to_data, tokenizer): # Vocabulary is a set that stores every word seen in the training data self.vocab = set() self.path to data = path to data self.tokenize doc - tokenizer self.train dir = os.path.join(path to data, "train") self.test dir = os. path.join(path to data, "test") # class total_doc_counts is a dictionary that maps a class (i.e., poses) to # the number of documents in the training set of that class self.class total doc counts = { POS LABEL: 0.0, NEG LABEL: 0.0 } # class total word counts is a dictionary that maps a class (i.e., poseg) to # the number of words in the training set in documents of that class self.class_total word_counts = { POS LABEL: 0., NEG LABEL: 0.0 } # classword_counts is a dictionary of dictionaries. It maps a class (i.. # poses) to a dictionary of word counts. For example: # self.class_word_counts(POS LABEL][awesome'] # stores the number of times the word 'awesome' appears in documents Start your search O 0 0 Top L ys saveu Comment RAME Disk - + class wiu LUULILS 13 GULLUQIY UI UIL LAVIGT es. El maps # poseg) to a dictionary of word counts. For example: # self.class_word_counts [POS_LABEL][ 'awesome'] # stores the number of times the word 'awesome' appears in documents # of the positive class in the training documents. self.class_word_counts = { POS_LABEL: defaultdict(float), NEG_LABEL: defaultdict(float) } def train_model(self): This function processes the entire training set using the global PATH variable above. It makes use of the tokenize_doc and update model functions you will implement. pos path = os.path.join(self.train dir, POS LABEL) neg_path = os.path.join(self.train dir, NEG LABEL), for (P, label) in [ (pos path, POS LABEL), (neg path, NEG LABEL) : for fin os.listdir(P): with open(os.path.join(p,f), 'r') as doc: content = doc.read() self.tokenize_and_update_model(content, label) self.report_statistics_after_training) def report_statistics_after_training (self): Report a number of statistics after training. print ("REPORTING CORPUS STATISTICS") print (NUMBER OF DOCUMENTS IN POSITIVE CLASS", self.class total doc counts POS LABEL print (NUMBER OF DOCUMENTS IN NEGATIVE CLASS", self.class total doc count SNEG LABEL 1), print "NUMBER OF TOKENS IN POSITIVE CLASS", self.class total word counts[POS LABEL DI Start your search ULIRE ..ipynb View Insert Runtime Tools Help All changes saved e Comment + Text IL YULE RAM O Disk C for (p, label) in C (pos_path, POS_LABEL), (neg path, NEG_LABEL) ); for f in os.listdir(): with open(os.path.join(p,f), 'r') as doc: content - doc.read() self.tokenize and update model(content, label) self.report_statistics after training() def report_statistics_after_training(self): Report a number of statistics after training. print ("REPORTING CORPUS STATISTICS") print ("NUMBER OF DOCUMENTS IN POSITIVE CLASS", self.class_total_doc_count S[POS LABEL 1) print ("NUMBER OF DOCUMENTS IN NEGATIVE CLASS", self.class_total_doc_count S[NEG LABEL)) print ("NUMBER OF TOKENS IN POSITIVE CLASS:", self.class total_word counts [POS LABEL 1), print ("NUMBER OF TOKENS IN NEGATIVE CLASS:", self.class total word_counts [NEG LABEL 1) print ("VOCABULARY SIZE: NUMBER OF UNIQUE WORDTYPES IN TRAINING CORPUS", len(self.vocab)) def update_model(self, bow, label): IMPLEMENT ME! Update internal statistics given a document represented as a bag-of-words bow - a map from words to their counts Label - the class of the document whose bag of words representation was input This function doesn't return anything but should update a number of internal statistics. Specifically, it updates: - the internal map the counts, per class, how many times each word was seen (self.class_word_counts) - the number of words seen for each label (self.class total word count) - the vocabulary seen so far (self.vocab) LJUSLINTUKAUDE frateport 15 BlackBoard E-mail | ECU & ECU Canvas NHL Handshake Chegg Turning Point Networking Book Ronnie Book Operating Systems. Computer Science. a HWK2.ipynb File Edit View Insert Runtime Tools Help All changes saved, Comment LSH + Code + Text Disk IMPLEMENT ME! Update internal statistics given a document represented as a bag-of-words bow - a map from words to their counts label - the class of the document whose bag-of-words representation was input This function doesn't return anything but should update a number of internal statistics. Specifically, it updates: - the internal map the counts, per class, how many times each word was seen (self.class word_counts) - the number of words seen for each label (self.class_total word_counts) - the vocabulary seen so far (self.vocab) - the number of documents seen of each label (self.class_total_doc counts) pass def tokenize_and_update_model(self, doc, label): Implement me! Tokenizes a document doc and updates internal count statistics. doc - a string representing a document. label - the sentiment of the document (either postive or negative) stop_word - a boolean flag indicating whether to stop word or not Make sure when tokenizing to lower case all of the tokens! pass colab.research.google.com/drive/lwtKNp9D2b3mn vyAK13_uQpEV.m5b7#scrollTo=A4Z2CKADPDCP BlackBoard E-mail ECU & ECU Canvas NHL H Handshake C Chegg Turning Point Networking Book Ronnie Book Operating Systems... Computer Science CSC 30 Comment Share HWK2.ipynb Edit View Insert Runtime Tools Help All changes saved ode + Text def tokenize_and_update_model(self, doc, label): RAM O Disk S . Implement me! Tokenizes a document doc and updates internal count statistics. doc - a string representing a document. label - the sentiment of the document (either postive or negative) stop word - a boolean flar indicating whether to stop word or not Make sure when tokenizing to lower case all of the tokens ! pass def top_n(self, label, n): Implement me! Returns the most frequent a tokens for documents with class Tabel'. pass def p_word_given_label(self, word, label): Implement me! Returns the probability of word given Label according to this MB sodel. T U D I VYANIS UPEV-5b/#scrolllo=A4Z2CKADPDCP Port 1 BlackBoard E-mail ECU ECU Canvas NHL Handshake C Chegg Turning Point Networking Book Ronnie Book Operating Systems Computer Science. CSC 3650 Hom HWK2.ipynb e Edit View Insert Runtime Tools Help All changes saved Comment Share I Code + Text RAM - pass Editing def top_n(self, label, n): Implement me! Returns the most frequent n tokens for documents with class 'label'. pass def p_word given_label(self, word, label): Implement me! Returns the probability of word given label according to this NB model. pass def word given_label_and_alpha(self, word, label, alpha), Implement me! Returns the probability of word given label wrt psuedo counts. alpha pseudocount parameter pass O Start your search D W Port BlackBoard E-mail ECU ECU Canvas NHL Handshake C Chegg Turning Point Networking Book Ronnie Book Operating Systems... Computer Science SCI 3650 Hom HWK2.ipynb le Edit View Insert Runtime Tools Help - Code + Text All changes saved Comment Share I BAM B . Editing Returns the probability of word given label according to this NB model. pass def p_word given_label_and_alpha(self, word, label, alpha): Implement me! Returns the probability of word given label writ psuedo counts alpha - pseudocount parameter pass def log_likelihood (self, bow, label, alpha): Implement me! Computes the log likelihood of a set of words given a label and pseudocount. bow a bag of words (i.e., a tokenized document) label - either the positive or negative label alpha - float; pseudocount parameter pass def log_prior(self, label): Implement met O Start your search LILUULJ Turning Point Networking Book Ronnie Book Operating System. Computer Science A CSCI 3650 HWK2.ipynb File Edit View Insert Runtime Tools Help + Code + Text All changes saved Comment Shares von B Edita pass def log prior(self, label): Implement me! Returns the log prior of a document having the class 'label'. pass def unnormalized log posterior(self, bow, label, alpha): Implement me! Computes the unnormalized log posterior (of doc being of class "label". bow - a bag of words (i.e., a tokenized document) pass def classify(self, bow, alpha): Implement me! Compares the unormalized log posterior for doc for both the positive and negative classes and returns the either POS LABEL or NEG LABEL (depending on which resulted in the higher unormalized log posterior) bow - a bag of words (i.e., a tokenized document) O Start your search -WR2.ipynb View Insert Runtime Tools Help Code + Text All changes saved Comment Share blick - Editin def classify(self, bow, alpha): Implement me! Compares the unnormalized log posterior for doc for both the positive and negative classes and returns the either POS LABEL or NEG_LABEL depending on which resulted in the higher unnormalized log posterior) bow - a bag of words (i.e., a tokenized document) pass def likelihood_ratio(self, word, alpha): Implement me! Returns the ratio of P(word[pos) to P(word neg). pass der evaluate_classifier_accuracy(self, alpha): DO NOT MODIFY THIS FUNCTION alpha - pseudocount parameter. This function should go through the test data, classify each instance and compute the accuracy of the classifier (the fraction of classifications the classifier gets right. Correct 2.0 total = 0. O Start your search HWR2.upynb e Edit View Insert Runtime Tools Help Comment Shares All changes saved Code + Text def likelihood_ratio(self, word, alpha): Ba B , Edie Implement me! Returns the ratio of P(word|pos) to P(word|neg). pass det evaluate classifier accuracy(self, alpha): DO NOT MODIFY THIS FUNCTION alpha - pseudocount parameter. This function should go through the test data, classify each instance and compute the accuracy of the classifier (the fraction of classifications the classifier gets right. correct - 0.0 total = . 5 pos_path-os-path.join(self.test_dir, POS_LABEL) neg_path - os.path.join(self.test_dir, NEG LABEL) for (o. label) in I (pos path, POS LABEL), (neg path, NEG LABEL) for fin os.listdir(): with open(os.path.join(p,f), 'r') as doc: content = doc.read() bow - self.tokenize_doc(content) if self.classify(bow, alpha) = label: correct 1.6 total 1.0 return 188 correct / total 22 HUN2. Edit View W Insert Runtime Tools Help All changes saved Comment Share X Code + Text RAM S Disk . Editi pass def evaluate_classifier_accuracy(self, alpha): DO NOT MODIFY THIS FUNCTION alpha - pseudocount parameter. This function should go through the test data, classify each instance and compute the accuracy of the classifier (the fraction of classifications the classifier gets right. correct = 0.0 total = 0.0 : pos path = os path.join(self.test dir, POS LABEL) neg path - OS-path.join(self.test_dir, NEG_LABEL) for (P, label) in I (pos path, POS LABEL), (neg path, NEG LABEL) for fin os.listdir(P): with open(os.path.join(p,f), 'r') as doc: content - doc.read() bow - self.tokenize doc(content) if self.classify(bow, alpha) -- label: correct 1.0 total 1.0 return 100 % correct / total Part One: Intro to NLP in Python: types, tokens and Zipf's law Start your search File Edit View Insert Runtime Tools Help All changes saved Comment + Code + Text Share Now we are going to look at the word types and word tokens in the corpus. Use the word counts dictionary variable to store the count of each word in the corpus. Use the tokenize_doc function to break documents into tokens. You should not modify tokenize_doc but make sure you understand what it is doing. - Question 1.1 (5 points) Complete the cell below to fill out the word counts dictionary variable. word counts keeps track of how many times a word type appears across the corpus. For instance, word_counts("movie") should store the number 61492 - the count of how many times the word movie appears in the corpus. [23] import glob import codecs word counts - Counter() # Counters are often useful for NLP in python for label in [POS_LABEL, NEG_LABEL): for directory in [TRAIN_DIR, TEST_DIR]: for fn in glob.glob(directory + "/" label + "/"txt"): doc = codecs.open(fn, 'r', 'utf8') # Open the file with UTF-8 encoding print (doc.Counter('movie')) pass Traceback (most recent call last) Sobo -23 Ada 440015> in () 1 Ort glob 2 Import codecs word counts Counter Counters are often useful for NLP in python O Start your search D ox 627 PM 2A/ Comment Shares Edit View Insert Runtime Tools Help Code + Text RAM 2 . Disk En Now we are going to look at the word types and word tokens in the corpus. Use the word counts dictionary variable to store the count of each word in the corpus. Use the tokenize_doc function to break documents into tokens. You should not modify tokenize_doc but make sure you understand what it is doing. Question 1.1 (5 points Complete the cell below to fill out the word counts dictionary variable, word_counts keeps track of how many times a word type appears across the corpus. For instance, word counts("movie") should store the number 61492-the count of how many times the word movie appears in the corpus Q import glob import codecs word counts - Counter() # Counters are often useful for NLP in python for label in [POS_LABEL, NEG_LABEL): for directory in [TRAIN_DIR, TEST_DIR] : for fn in glob.glob(directory + "/" label + "/"txt"): doc - codecs.open(fn, 'r', 'utf8') open the file with UTF-8 encoding print(doc.Counter('movie')) pass [ if word counts["movie" wm 61492: print yay! there are a total instances of the word type movie corpus".Format(word_counts ["movie" 1)) brint mm. Something seems ofl. Double check your code) Start your search Saving... File Edit View Insert Runtime Tools Help + Code + Text Comment Shares RAMP E - Question 1.2 (5 points) Fill out the functions n_word_types, n_word_tokens in the Preprocessing Block. Note: you will have to rerun the Preprocessing Block cell every time you change its code for it to have any effect! 131 print ("there are word types in the corpus".Format(n word types (word_counts)) print ("there are (word tokens in the corpus".Format(n word tokens(word counts:))) What is the difference between word types and tokens? Why are the number of tokens much higher than the number of types? Answer in one or two lines here. Question 1.3 (5 points) Using the word counts dictionary you just created, make a new dictionary called sorted dict where the words are sorted according to their counts, in decending order. 11 IMPLEMENT ME! Now print the first 30 values from sorted_dict. 11 IMPLEMENT ME! 1 O Start your search ADEX 28 PM 220 HVN.PHU W File Edit View Insert Runtime Tools Help All changes saved Comment Share + Code + Text - Question 1.3 (5 points) Disk - Using the word_counts dictionary you just created, make a new dictionary called sorted_dict where the words are sorted according to their counts, in decending order: ] # IMPLEMENT ME! Now print the first 30 values from sorted_dict. O # IMPLEMENT ME! - Zipf's Law Question 1.4 (10 points) In this section, you will verify a key statistical property of text: Zi's Law. Zipf's Law describes the relations between the frequency rank of words and frequency value of words. For a word w, its frequency is inversely proportional to its rank: count = K- ram K is a constant, specific to the corpus and how words are being defined. What would this look like if you took the log of both sides of the equation? O Start your search 6:28 PM HWA2.1pynb File Edit View Insert Runtime Tools Help + Code + Text All changes saved Comment Share RAMP. Disk Question 1.4 (10 points) C In this section, you will verify a key statistical property of text: Zipf's Law. Zip's Law describes the relations between the frequency rank of words and frequency value of words. For a word w, its frequency is inversely proportional to its rank: count, = K rank K is a constant, specific to the corpus and how words are being defined. What would this look like if you took the log of both sides of the equation? Write your answer in one or two lines here. Therefore, if Zipf's Law holds, after sorting the words descending on frequency, word frequency decreases in an approximately linear fashion under a log-log scale. Now, please make such a log-log plot by plotting the rank versus frequency Hint: Make use of the sorted dictionary you just created. Use a scatter plot where the x-axis is the log(rank), and y-axis is log(frequency). You should get this information from word counts; for example, you can take the individual word counts and sort them. dict methods itens and/or values() may be useful. (Note that it doesn't really matter whether ranks start at 1 oro in terms of how the plot comes out.) You can check your results by comparing your plots to ones on Wikipedia, they should look qualitatively similar Please remember to label the meaning of the x-axis and y-axis. [1 import math eport operator X-11 O Start your search A x 8PM 240 Wispyno Edit View Insert Runtime Tools Help Comment Share File All changes saved RAM C Disk + Code + Text unei a vuyriuy Sudic. Now, please make such a log-log plot by plotting the rank versus frequency Hint: Make use of the sorted dictionary you just created. Use a scatter plot where the x-axis is the log(rank), and y-axis is log(frequency). You should get this information from word_counts; for example, you can take the individual word counts and sort them. dict methods .items() and/or values() may be useful. (Note that it doesn't really matter whether ranks start at 1 or 0 in terms of how the plot comes out.) You can check your results by comparing your plots to ones on Wikipedia, they should look qualitatively similar. Please remember to label the meaning of the x-axis and y-axis. [] import math import operator x = 0 y- X LABEL = "log(rank) Y_LABEL = "log(Frequency) implement mel you should fill the x and y arrays. Add your code here #running this cell should produce your plot below plt.scatter(x, y) plt.xlabel(X_LABEL) plt.ylabel (Y_LABEL) Part Two: Naive Bayes This section of the homework will walk you through coding a Naive Bayes classifier that can distinguish between positive and negative reviews (with some level of accuracy). 1001 Hue Tools Help All changes saved + Code + Text - - Question 1.1 (5 points) Complete the cell below to fill out the word_counts dictionary variable, word_counts keeps track of how many times a word type appears across the corpus. For instance, word_counts("movie") should store the number 61492 - the count of how many times the word movie appears in the corpus. import glob import codecs word_counts - Counter() # Counters are often useful for NLP in python for label in [POS_LABEL, NEG_LABEL): for directory in [TRAIN_DIR, TEST DIR]: for fn in glob.glob(directory + "/" + label + "/"txt"): doc - codecs.open(fn, 'r', 'utf8') # Open the file with UTF-8 encoding # IMPLEMENT ME pass U if word_counts["movie"] = 61492: print ("yay! there are t) total instances of the word type movie in the corpus".Format(word_counts("movie"))) else: print ("hmm. Something seems off. Double check your code") - Question 1.2 (5 points) Fill out the functions n word_types, n.word_tokens in the Preprocessing Block. Note: you will have to rerun the preprocessing Block cell every time you change its code for it to have any effect! ji + Code + Text [ if word_counts["movie" ] -- 61492: print (yayl there are 0 total instances of the word type movie in the corpus".Format(word_counts ["movie" 1) else: print ("hmm. Something seems off. Double check your code") o Question 1.2 (5 points) Fill out the functions n_word_types, n_word_tokens in the Preprocessing Block. Note: you will have to rerun the Preprocessing Block cell every time you change its code for it to have any effect! D print ("there are {} word types in the corpus".Format(n_word_types(word_counts))) print ("there are () word tokens in the corpus".Format(n_word_tokens(word_counts))) What is the difference between word types and tokens? Why are the number of tokens much higher than the number of types? Answer in one or two lines here. - Question 1.3 (5 points) Using the word counts dictionary you just created, make a new dictionary called sorted_dict where the words are sorted according to their counts, in decending order. [] # IMPLEMENT ME! print (r o nd tokensIr the corpus'.format(n_word_tokens(word_counts)>> What is the difference between word types and tokens? Why are the number of tokens much higher than the number of types? Answer in one or two lines here. - Question 1.3 (5 points) Using the word_counts dictionary you just created, make a new dictionary called sorted_dict where the words are sorted according to their counts, in decending order. O # IMPLEMENT ME! Now print the first 30 values from sorted_dict. [] # IMPLEMENT ME! - Zipf's Law Question 1.4 (10 points) In this section, you will verify a key statistical property of text: Zipf's Law. O lang systems. e Comput HWK2.ipynb File Edit View Insert Runtime Tools Help All changes saved a com + Code + Text Question 1.4 (10 points) In this section, you will verify a key statistical property of text: Zipf's Law. Zipf's Law describes the relations between the frequency rank of words and frequency value of words. For a word w, its frequency is inversely proportional to its rank: count = K- rank, K is a constant, specific to the corpus and how words are being defined. What would this look like if you took the log of both sides of the equation? Write your answer in one or two lines here. Therefore, if Zipf's Law holds, after sorting the words descending on frequency, word frequency decreases in an approximately linear fashion under a log-log scale. Now, please make such a log-log plot by plotting the rank versus frequency Hint Make use of the sorted dictionary you just created. Use a scatter plot where the x-axis is the log(rank), and y-axis is 109 liegen should get this information from word counts, for example, you can take the individual word counts and sort them, dictmemester and/or values() may be useful. (Note that it doesn't really matter whether ranks start at 1 or 0 in terms of how the plot comes out.) You can check your results by comparing your plots to ones on Wikipedia; they should look qualitatively similar Please remember to label the meaning of the x-axis and y-axis. File Edit View Insert Runtime Tools Help All changes saved + Code + Text under a log-log scale. Now, please make such a log-log plot by plotting the rank versus frequency Hint: Make use of the sorted dictionary you just created. Use a scatter plot where the x-axis is the log(rank), and y-axis is log(frequency). You should get this information from word_counts; for example, you can take the individual word counts and sort them. dict methods .items() and/or values() may be useful. (Note that it doesn't really matter whether ranks start at 1 or 0 in terms of how the plot comes out.) You can check your results by comparing your plots to ones on Wikipedia; they should look qualitatively similar. Please remember to label the meaning of the x-axis and y-axis. [] import math import operator x = [] y = [] X_LABEL = "log(rank)" Y_LABEL = "log(frequency)" # implement me! you should fill the x and y arrays. Add your code here #running this cell should produce your plot below plt.scatter(x, y) plt.xlabel(X_LABEL) plt.ylabel (Y_LABEL) Part Two: Naive Bayes Code + Text The following cell contains code that will be referred to as the Preprocessing Block from now on. It contains a function that tokenizes the document passed to it, and functions that return counts of word types and tokens. [21] ****** PREPROCESSING BLOCK #***** #**### DO NOT MODIFY THIS FUNCTION ##### def tokenize_doc(doc): Tokenize a document and return its bag-of-words representation. doc - a string representing a document. returns a dictionary mapping each word to the number of times it appears in doc. bow - defaultdict(float) tokens = doc.split() lowered_tokens = map(lambda t: t.lower(), tokens) for token in lowered tokens: bow[token] + 1.0 return dict(bow) # END FUNCTION def n word_types(word_counts): Implement Mel return a count of all word types in the corpus using information from word_counts for word in word list: die word countsdicteet (word counts, o print word counts) Start you O 121] #*****# END FUNCTION #***# def n_word_types(word_counts): Implement Me! return a count of all word types in the corpus using information from word_counts for word in word list: dict[word_counts] = dict.get(word_counts, e) + 1 print(word_counts) pass def n_word_tokens(word_counts): Implement Me! return a count of all word tokens in the corpus using information from word_counts pass This next block of code (referred to as Naive Bayes Block from now on) is something you will keep coming back to throughout the course of the assignment. There are several functions you need to implement here, that will be called in later parts of the assignment. Familiarize yourself with what each function does, as well as how everything comes together. O NAIVE BAYES BLOCK *** O Start your search Code + Text This next block of code (referred to as Naive Bayes Block from now on) is something you will keep coming back to throughout the course of the assignment. There are several functions you need to implement here, that will be called in later parts of the assignment. Familiarize yourself with what each function does, as well as how everything comes together. [1#****# NAIVE BAYES BLOCK ##**## class NaiveBayes: A Naive Bayes model for text classification, def __init__(self, path_to_data, tokenizer): # Vocabulary is a set that stores every word seen in the training data self.vocab = set() self.path to data = path to data self.tokenize doc - tokenizer self.train dir = os.path.join(path to data, "train") self.test dir = os. path.join(path to data, "test") # class total_doc_counts is a dictionary that maps a class (i.e., poses) to # the number of documents in the training set of that class self.class total doc counts = { POS LABEL: 0.0, NEG LABEL: 0.0 } # class total word counts is a dictionary that maps a class (i.e., poseg) to # the number of words in the training set in documents of that class self.class_total word_counts = { POS LABEL: 0., NEG LABEL: 0.0 } # classword_counts is a dictionary of dictionaries. It maps a class (i.. # poses) to a dictionary of word counts. For example: # self.class_word_counts(POS LABEL][awesome'] # stores the number of times the word 'awesome' appears in documents Start your search O 0 0 Top L ys saveu Comment RAME Disk - + class wiu LUULILS 13 GULLUQIY UI UIL LAVIGT es. El maps # poseg) to a dictionary of word counts. For example: # self.class_word_counts [POS_LABEL][ 'awesome'] # stores the number of times the word 'awesome' appears in documents # of the positive class in the training documents. self.class_word_counts = { POS_LABEL: defaultdict(float), NEG_LABEL: defaultdict(float) } def train_model(self): This function processes the entire training set using the global PATH variable above. It makes use of the tokenize_doc and update model functions you will implement. pos path = os.path.join(self.train dir, POS LABEL) neg_path = os.path.join(self.train dir, NEG LABEL), for (P, label) in [ (pos path, POS LABEL), (neg path, NEG LABEL) : for fin os.listdir(P): with open(os.path.join(p,f), 'r') as doc: content = doc.read() self.tokenize_and_update_model(content, label) self.report_statistics_after_training) def report_statistics_after_training (self): Report a number of statistics after training. print ("REPORTING CORPUS STATISTICS") print (NUMBER OF DOCUMENTS IN POSITIVE CLASS", self.class total doc counts POS LABEL print (NUMBER OF DOCUMENTS IN NEGATIVE CLASS", self.class total doc count SNEG LABEL 1), print "NUMBER OF TOKENS IN POSITIVE CLASS", self.class total word counts[POS LABEL DI Start your search ULIRE ..ipynb View Insert Runtime Tools Help All changes saved e Comment + Text IL YULE RAM O Disk C for (p, label) in C (pos_path, POS_LABEL), (neg path, NEG_LABEL) ); for f in os.listdir(): with open(os.path.join(p,f), 'r') as doc: content - doc.read() self.tokenize and update model(content, label) self.report_statistics after training() def report_statistics_after_training(self): Report a number of statistics after training. print ("REPORTING CORPUS STATISTICS") print ("NUMBER OF DOCUMENTS IN POSITIVE CLASS", self.class_total_doc_count S[POS LABEL 1) print ("NUMBER OF DOCUMENTS IN NEGATIVE CLASS", self.class_total_doc_count S[NEG LABEL)) print ("NUMBER OF TOKENS IN POSITIVE CLASS:", self.class total_word counts [POS LABEL 1), print ("NUMBER OF TOKENS IN NEGATIVE CLASS:", self.class total word_counts [NEG LABEL 1) print ("VOCABULARY SIZE: NUMBER OF UNIQUE WORDTYPES IN TRAINING CORPUS", len(self.vocab)) def update_model(self, bow, label): IMPLEMENT ME! Update internal statistics given a document represented as a bag-of-words bow - a map from words to their counts Label - the class of the document whose bag of words representation was input This function doesn't return anything but should update a number of internal statistics. Specifically, it updates: - the internal map the counts, per class, how many times each word was seen (self.class_word_counts) - the number of words seen for each label (self.class total word count) - the vocabulary seen so far (self.vocab) LJUSLINTUKAUDE frateport 15 BlackBoard E-mail | ECU & ECU Canvas NHL Handshake Chegg Turning Point Networking Book Ronnie Book Operating Systems. Computer Science. a HWK2.ipynb File Edit View Insert Runtime Tools Help All changes saved, Comment LSH + Code + Text Disk IMPLEMENT ME! Update internal statistics given a document represented as a bag-of-words bow - a map from words to their counts label - the class of the document whose bag-of-words representation was input This function doesn't return anything but should update a number of internal statistics. Specifically, it updates: - the internal map the counts, per class, how many times each word was seen (self.class word_counts) - the number of words seen for each label (self.class_total word_counts) - the vocabulary seen so far (self.vocab) - the number of documents seen of each label (self.class_total_doc counts) pass def tokenize_and_update_model(self, doc, label): Implement me! Tokenizes a document doc and updates internal count statistics. doc - a string representing a document. label - the sentiment of the document (either postive or negative) stop_word - a boolean flag indicating whether to stop word or not Make sure when tokenizing to lower case all of the tokens! pass colab.research.google.com/drive/lwtKNp9D2b3mn vyAK13_uQpEV.m5b7#scrollTo=A4Z2CKADPDCP BlackBoard E-mail ECU & ECU Canvas NHL H Handshake C Chegg Turning Point Networking Book Ronnie Book Operating Systems... Computer Science CSC 30 Comment Share HWK2.ipynb Edit View Insert Runtime Tools Help All changes saved ode + Text def tokenize_and_update_model(self, doc, label): RAM O Disk S . Implement me! Tokenizes a document doc and updates internal count statistics. doc - a string representing a document. label - the sentiment of the document (either postive or negative) stop word - a boolean flar indicating whether to stop word or not Make sure when tokenizing to lower case all of the tokens ! pass def top_n(self, label, n): Implement me! Returns the most frequent a tokens for documents with class Tabel'. pass def p_word_given_label(self, word, label): Implement me! Returns the probability of word given Label according to this MB sodel. T U D I VYANIS UPEV-5b/#scrolllo=A4Z2CKADPDCP Port 1 BlackBoard E-mail ECU ECU Canvas NHL Handshake C Chegg Turning Point Networking Book Ronnie Book Operating Systems Computer Science. CSC 3650 Hom HWK2.ipynb e Edit View Insert Runtime Tools Help All changes saved Comment Share I Code + Text RAM - pass Editing def top_n(self, label, n): Implement me! Returns the most frequent n tokens for documents with class 'label'. pass def p_word given_label(self, word, label): Implement me! Returns the probability of word given label according to this NB model. pass def word given_label_and_alpha(self, word, label, alpha), Implement me! Returns the probability of word given label wrt psuedo counts. alpha pseudocount parameter pass O Start your search D W Port BlackBoard E-mail ECU ECU Canvas NHL Handshake C Chegg Turning Point Networking Book Ronnie Book Operating Systems... Computer Science SCI 3650 Hom HWK2.ipynb le Edit View Insert Runtime Tools Help - Code + Text All changes saved Comment Share I BAM B . Editing Returns the probability of word given label according to this NB model. pass def p_word given_label_and_alpha(self, word, label, alpha): Implement me! Returns the probability of word given label writ psuedo counts alpha - pseudocount parameter pass def log_likelihood (self, bow, label, alpha): Implement me! Computes the log likelihood of a set of words given a label and pseudocount. bow a bag of words (i.e., a tokenized document) label - either the positive or negative label alpha - float; pseudocount parameter pass def log_prior(self, label): Implement met O Start your search LILUULJ Turning Point Networking Book Ronnie Book Operating System. Computer Science A CSCI 3650 HWK2.ipynb File Edit View Insert Runtime Tools Help + Code + Text All changes saved Comment Shares von B Edita pass def log prior(self, label): Implement me! Returns the log prior of a document having the class 'label'. pass def unnormalized log posterior(self, bow, label, alpha): Implement me! Computes the unnormalized log posterior (of doc being of class "label". bow - a bag of words (i.e., a tokenized document) pass def classify(self, bow, alpha): Implement me! Compares the unormalized log posterior for doc for both the positive and negative classes and returns the either POS LABEL or NEG LABEL (depending on which resulted in the higher unormalized log posterior) bow - a bag of words (i.e., a tokenized document) O Start your search -WR2.ipynb View Insert Runtime Tools Help Code + Text All changes saved Comment Share blick - Editin def classify(self, bow, alpha): Implement me! Compares the unnormalized log posterior for doc for both the positive and negative classes and returns the either POS LABEL or NEG_LABEL depending on which resulted in the higher unnormalized log posterior) bow - a bag of words (i.e., a tokenized document) pass def likelihood_ratio(self, word, alpha): Implement me! Returns the ratio of P(word[pos) to P(word neg). pass der evaluate_classifier_accuracy(self, alpha): DO NOT MODIFY THIS FUNCTION alpha - pseudocount parameter. This function should go through the test data, classify each instance and compute the accuracy of the classifier (the fraction of classifications the classifier gets right. Correct 2.0 total = 0. O Start your search HWR2.upynb e Edit View Insert Runtime Tools Help Comment Shares All changes saved Code + Text def likelihood_ratio(self, word, alpha): Ba B , Edie Implement me! Returns the ratio of P(word|pos) to P(word|neg). pass det evaluate classifier accuracy(self, alpha): DO NOT MODIFY THIS FUNCTION alpha - pseudocount parameter. This function should go through the test data, classify each instance and compute the accuracy of the classifier (the fraction of classifications the classifier gets right. correct - 0.0 total = . 5 pos_path-os-path.join(self.test_dir, POS_LABEL) neg_path - os.path.join(self.test_dir, NEG LABEL) for (o. label) in I (pos path, POS LABEL), (neg path, NEG LABEL) for fin os.listdir(): with open(os.path.join(p,f), 'r') as doc: content = doc.read() bow - self.tokenize_doc(content) if self.classify(bow, alpha) = label: correct 1.6 total 1.0 return 188 correct / total 22 HUN2. Edit View W Insert Runtime Tools Help All changes saved Comment Share X Code + Text RAM S Disk . Editi pass def evaluate_classifier_accuracy(self, alpha): DO NOT MODIFY THIS FUNCTION alpha - pseudocount parameter. This function should go through the test data, classify each instance and compute the accuracy of the classifier (the fraction of classifications the classifier gets right. correct = 0.0 total = 0.0 : pos path = os path.join(self.test dir, POS LABEL) neg path - OS-path.join(self.test_dir, NEG_LABEL) for (P, label) in I (pos path, POS LABEL), (neg path, NEG LABEL) for fin os.listdir(P): with open(os.path.join(p,f), 'r') as doc: content - doc.read() bow - self.tokenize doc(content) if self.classify(bow, alpha) -- label: correct 1.0 total 1.0 return 100 % correct / total Part One: Intro to NLP in Python: types, tokens and Zipf's law Start your search File Edit View Insert Runtime Tools Help All changes saved Comment + Code + Text Share Now we are going to look at the word types and word tokens in the corpus. Use the word counts dictionary variable to store the count of each word in the corpus. Use the tokenize_doc function to break documents into tokens. You should not modify tokenize_doc but make sure you understand what it is doing. - Question 1.1 (5 points) Complete the cell below to fill out the word counts dictionary variable. word counts keeps track of how many times a word type appears across the corpus. For instance, word_counts("movie") should store the number 61492 - the count of how many times the word movie appears in the corpus. [23] import glob import codecs word counts - Counter() # Counters are often useful for NLP in python for label in [POS_LABEL, NEG_LABEL): for directory in [TRAIN_DIR, TEST_DIR]: for fn in glob.glob(directory + "/" label + "/"txt"): doc = codecs.open(fn, 'r', 'utf8') # Open the file with UTF-8 encoding print (doc.Counter('movie')) pass Traceback (most recent call last) Sobo -23 Ada 440015> in () 1 Ort glob 2 Import codecs word counts Counter Counters are often useful for NLP in python O Start your search D ox 627 PM 2A/ Comment Shares Edit View Insert Runtime Tools Help Code + Text RAM 2 . Disk En Now we are going to look at the word types and word tokens in the corpus. Use the word counts dictionary variable to store the count of each word in the corpus. Use the tokenize_doc function to break documents into tokens. You should not modify tokenize_doc but make sure you understand what it is doing. Question 1.1 (5 points Complete the cell below to fill out the word counts dictionary variable, word_counts keeps track of how many times a word type appears across the corpus. For instance, word counts("movie") should store the number 61492-the count of how many times the word movie appears in the corpus Q import glob import codecs word counts - Counter() # Counters are often useful for NLP in python for label in [POS_LABEL, NEG_LABEL): for directory in [TRAIN_DIR, TEST_DIR] : for fn in glob.glob(directory + "/" label + "/"txt"): doc - codecs.open(fn, 'r', 'utf8') open the file with UTF-8 encoding print(doc.Counter('movie')) pass [ if word counts["movie" wm 61492: print yay! there are a total instances of the word type movie corpus".Format(word_counts ["movie" 1)) brint mm. Something seems ofl. Double check your code) Start your search Saving... File Edit View Insert Runtime Tools Help + Code + Text Comment Shares RAMP E - Question 1.2 (5 points) Fill out the functions n_word_types, n_word_tokens in the Preprocessing Block. Note: you will have to rerun the Preprocessing Block cell every time you change its code for it to have any effect! 131 print ("there are word types in the corpus".Format(n word types (word_counts)) print ("there are (word tokens in the corpus".Format(n word tokens(word counts:))) What is the difference between word types and tokens? Why are the number of tokens much higher than the number of types? Answer in one or two lines here. Question 1.3 (5 points) Using the word counts dictionary you just created, make a new dictionary called sorted dict where the words are sorted according to their counts, in decending order. 11 IMPLEMENT ME! Now print the first 30 values from sorted_dict. 11 IMPLEMENT ME! 1 O Start your search ADEX 28 PM 220 HVN.PHU W File Edit View Insert Runtime Tools Help All changes saved Comment Share + Code + Text - Question 1.3 (5 points) Disk - Using the word_counts dictionary you just created, make a new dictionary called sorted_dict where the words are sorted according to their counts, in decending order: ] # IMPLEMENT ME! Now print the first 30 values from sorted_dict. O # IMPLEMENT ME! - Zipf's Law Question 1.4 (10 points) In this section, you will verify a key statistical property of text: Zi's Law. Zipf's Law describes the relations between the frequency rank of words and frequency value of words. For a word w, its frequency is inversely proportional to its rank: count = K- ram K is a constant, specific to the corpus and how words are being defined. What would this look like if you took the log of both sides of the equation? O Start your search 6:28 PM HWA2.1pynb File Edit View Insert Runtime Tools Help + Code + Text All changes saved Comment Share RAMP. Disk Question 1.4 (10 points) C In this section, you will verify a key statistical property of text: Zipf's Law. Zip's Law describes the relations between the frequency rank of words and frequency value of words. For a word w, its frequency is inversely proportional to its rank: count, = K rank K is a constant, specific to the corpus and how words are being defined. What would this look like if you took the log of both sides of the equation? Write your answer in one or two lines here. Therefore, if Zipf's Law holds, after sorting the words descending on frequency, word frequency decreases in an approximately linear fashion under a log-log scale. Now, please make such a log-log plot by plotting the rank versus frequency Hint: Make use of the sorted dictionary you just created. Use a scatter plot where the x-axis is the log(rank), and y-axis is log(frequency). You should get this information from word counts; for example, you can take the individual word counts and sort them. dict methods itens and/or values() may be useful. (Note that it doesn't really matter whether ranks start at 1 oro in terms of how the plot comes out.) You can check your results by comparing your plots to ones on Wikipedia, they should look qualitatively similar Please remember to label the meaning of the x-axis and y-axis. [1 import math eport operator X-11 O Start your search A x 8PM 240 Wispyno Edit View Insert Runtime Tools Help Comment Share File All changes saved RAM C Disk + Code + Text unei a vuyriuy Sudic. Now, please make such a log-log plot by plotting the rank versus frequency Hint: Make use of the sorted dictionary you just created. Use a scatter plot where the x-axis is the log(rank), and y-axis is log(frequency). You should get this information from word_counts; for example, you can take the individual word counts and sort them. dict methods .items() and/or values() may be useful. (Note that it doesn't really matter whether ranks start at 1 or 0 in terms of how the plot comes out.) You can check your results by comparing your plots to ones on Wikipedia, they should look qualitatively similar. Please remember to label the meaning of the x-axis and y-axis. [] import math import operator x = 0 y- X LABEL = "log(rank) Y_LABEL = "log(Frequency) implement mel you should fill the x and y arrays. Add your code here #running this cell should produce your plot below plt.scatter(x, y) plt.xlabel(X_LABEL) plt.ylabel (Y_LABEL) Part Two: Naive Bayes This section of the homework will walk you through coding a Naive Bayes classifier that can distinguish between positive and negative reviews (with some level of accuracy)


![[POS_LABEL, NEG_LABEL): for directory in [TRAIN_DIR, TEST DIR]: for fn in glob.glob(directory](https://dsd5zvtm8ll6.cloudfront.net/si.experts.images/questions/2024/09/66f928eb06e0c_97066f928ea69653.jpg)
![word_counts["movie"] = 61492: print ("yay! there are t) total instances of the](https://dsd5zvtm8ll6.cloudfront.net/si.experts.images/questions/2024/09/66f928ee02d6e_97366f928ed53771.jpg)
![if word_counts["movie" ] -- 61492: print (yayl there are 0 total instances](https://dsd5zvtm8ll6.cloudfront.net/si.experts.images/questions/2024/09/66f928f3cfc38_97966f928f32eaaa.jpg)