

Question: package hashTables; //hash.java //demonstrates hash table with linear probing //to run this program: C:>java HashTableApp import java.io.*; import java.util.Scanner; //////////////////////////////////////////////////////////////// class Word { // (could


package hashTables;
//hash.java
//demonstrates hash table with linear probing
//to run this program: C:>java HashTableApp
import java.io.*;
import java.util.Scanner;
////////////////////////////////////////////////////////////////
class Word
{ // (could have more data)
private String word; // data item (key)
private String definition;
public Word next;//references the next word that hashed to the same
index - seperate chaining
//--------------------------------------------------------------
public Word(String word, String definition) // constructor
{
this.word = word;
this.definition = definition;
}
//--------------------------------------------------------------
public String getWord()
{
return word;
}
//--------------------------------------------------------------
} // end class DataItem
////////////////////////////////////////////////////////////////
class HashTable
{
private Word[] hashArray; // array holds hash table
private int arraySize;
private Word nonItem; // for deleted items
public static int countSC_Collisions = 0;
// -------------------------------------------------------------
public HashTable(int size) // constructor
{
arraySize = size;
hashArray = new Word[arraySize];
nonItem = new Word("nonitem", "nondefinition"); //
deleted item key is -1
}
// -------------------------------------------------------------
//the word is our key
public int hashFunc(String key) {
return Math.abs(key.hashCode()) % arraySize;
}
//seperate chaining insert
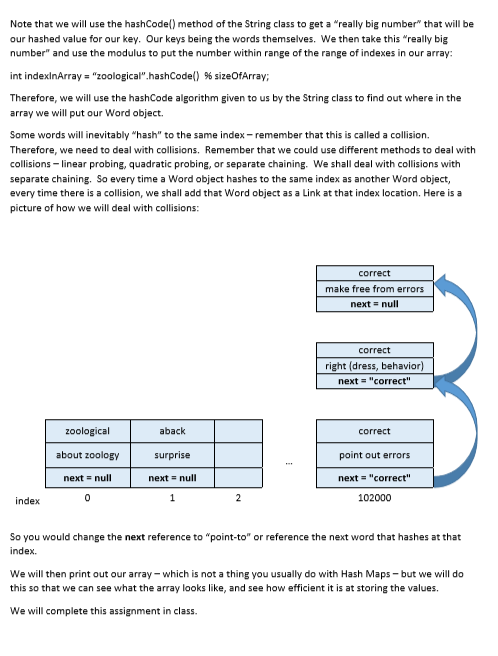
public void insert(Word item) {// insert a DataItem
String key = item.getWord(); // extract key
int hashVal = hashFunc(key); // hash the key
//insert the new Word object at that index if it is an
open spot
if(hashArray[hashVal] == null) {
hashArray[hashVal] = item;
return;
}
//if the index is not null - meaning their is another
Word at that index
//then move along the chain until the next
reference is null, then
//insert the new Word at that next reference
Word current = hashArray[hashVal] ;
while (current.next != null) {
current = current.next;
countSC_Collisions++;
}
current.next = item;
}
//display the seperate chaining hashtable
public void displaySCTable() {
for(int i = 0; i
if(hashArray[i] == null)
System.out.println("**");
else {
Word current = hashArray[i];
do {
System.out.print(current.getWord() + ": ");
current = current.next;
} while (current != null);
System.out.println();//skip to the next
line
}//end if
}//end for
}//end display
/*linear probing
public void displayTable()
{
System.out.print("Table: ");
for(int j=0; j { if(hashArray[j] != null) System.out.print(hashArray[j].getKey() + " "); else System.out.print("** "); } System.out.println(""); } // ------------------------------------------------------------- public int hashFunc(int key) { return key % arraySize; // hash function } // ------------------------------------------------------------- //using linear probing public void insert(DataItem item) // insert a DataItem // (assumes table not full) { int key = item.getKey(); // extract key int hashVal = hashFunc(key); // hash the key // until empty cell or -1, while(hashArray[hashVal] != null && hashArray[hashVal].getKey() != -1) { ++hashVal; // go to next cell hashVal %= arraySize; // wraparound if necessary } hashArray[hashVal] = item; // insert item } // end insert() // ------------------------------------------------------------- public DataItem delete(int key) // delete a DataItem { int hashVal = hashFunc(key); // hash the key while(hashArray[hashVal] != null) // until empty cell, { // found the key? if(hashArray[hashVal].getKey() == key) { DataItem temp = hashArray[hashVal]; // save item hashArray[hashVal] = nonItem; // delete item return temp; // return item } ++hashVal; // go to next cell hashVal %= arraySize; // wraparound if necessary } return null; // can't find item } // end delete() // ------------------------------------------------------------- public DataItem find(int key) // find item with key { int hashVal = hashFunc(key); // hash the key while(hashArray[hashVal] != null) // until empty cell, { // found the key? if(hashArray[hashVal].getKey() == key) return hashArray[hashVal]; // yes, return item ++hashVal; // go to next cell hashVal %= arraySize; // wraparound if necessary } return null; // can't find item } // ------------------------------------------------------------- * * */ } // end class HashTable //////////////////////////////////////////////////////////////// class HashTableApp { public static void main(String[] args) { //read in the words from the dictionary.txt //make a new Word object //insert it into the hash table HashTable ourHashTable = new HashTable(116437); Scanner input = null; try { input = new Scanner(new File("dictionary.txt")); } catch (FileNotFoundException e) { System.out.println("cannot find the file"); e.printStackTrace(); } while(input.hasNext()) { String word = input.next(); String def = input.nextLine(); //make a new Word object Word newWord = new Word(word, def); //insert it into the hash table ourHashTable.insert(newWord); } //print the hash table ourHashTable.displaySCTable(); System.out.println(HashTable.countSC_Collisions); System.out.println(HashTable.countSC_Collisions/48041.0 * 100); } /* public static void main(String[] args) throws IOException { DataItem aDataItem; int aKey, size, n, keysPerCell; // get sizes System.out.print("Enter size of hash table: "); size = getInt(); System.out.print("Enter initial number of items: "); n = getInt(); keysPerCell = 10; // make table HashTable theHashTable = new HashTable(size); for(int j=0; j { aKey = (int)(java.lang.Math.random() * keysPerCell * size); aDataItem = new DataItem(aKey); theHashTable.insert(aDataItem); } while(true) // interact with user { System.out.print("Enter first letter of "); System.out.print("show, insert, delete, or find: "); char choice = getChar(); switch(choice) { case 's': theHashTable.displayTable(); break; case 'i': System.out.print("Enter key value to insert: "); aKey = getInt(); aDataItem = new DataItem(aKey); theHashTable.insert(aDataItem); break; case 'd': System.out.print("Enter key value to delete: "); aKey = getInt(); theHashTable.delete(aKey); break; case 'f': System.out.print("Enter key value to find: "); aKey = getInt(); aDataItem = theHashTable.find(aKey); if(aDataItem != null) { System.out.println("Found " + aKey); } else System.out.println("Could not find " + aKey); break; default: System.out.print("Invalid entry "); } // end switch } // end while } // end main() //-------------------------------------------------------------- public static String getString() throws IOException { InputStreamReader isr = new InputStreamReader(System.in); BufferedReader br = new BufferedReader(isr); String s = br.readLine(); return s; } //-------------------------------------------------------------- public static char getChar() throws IOException { String s = getString(); return s.charAt(0); } //------------------------------------------------------------- public static int getInt() throws IOException { String s = getString(); return Integer.parseInt(s); } //-------------------------------------------------------------- * */ } // end class HashTableApp ////////////////////////////////////////////////////////////////
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts