

Question: Parallel computing Problem 1 - Chunk Matrix Multiply - Consider the Chunk Matrix multiplication depicted in the diagram below, where example chunks distributed are shown











Parallel computing

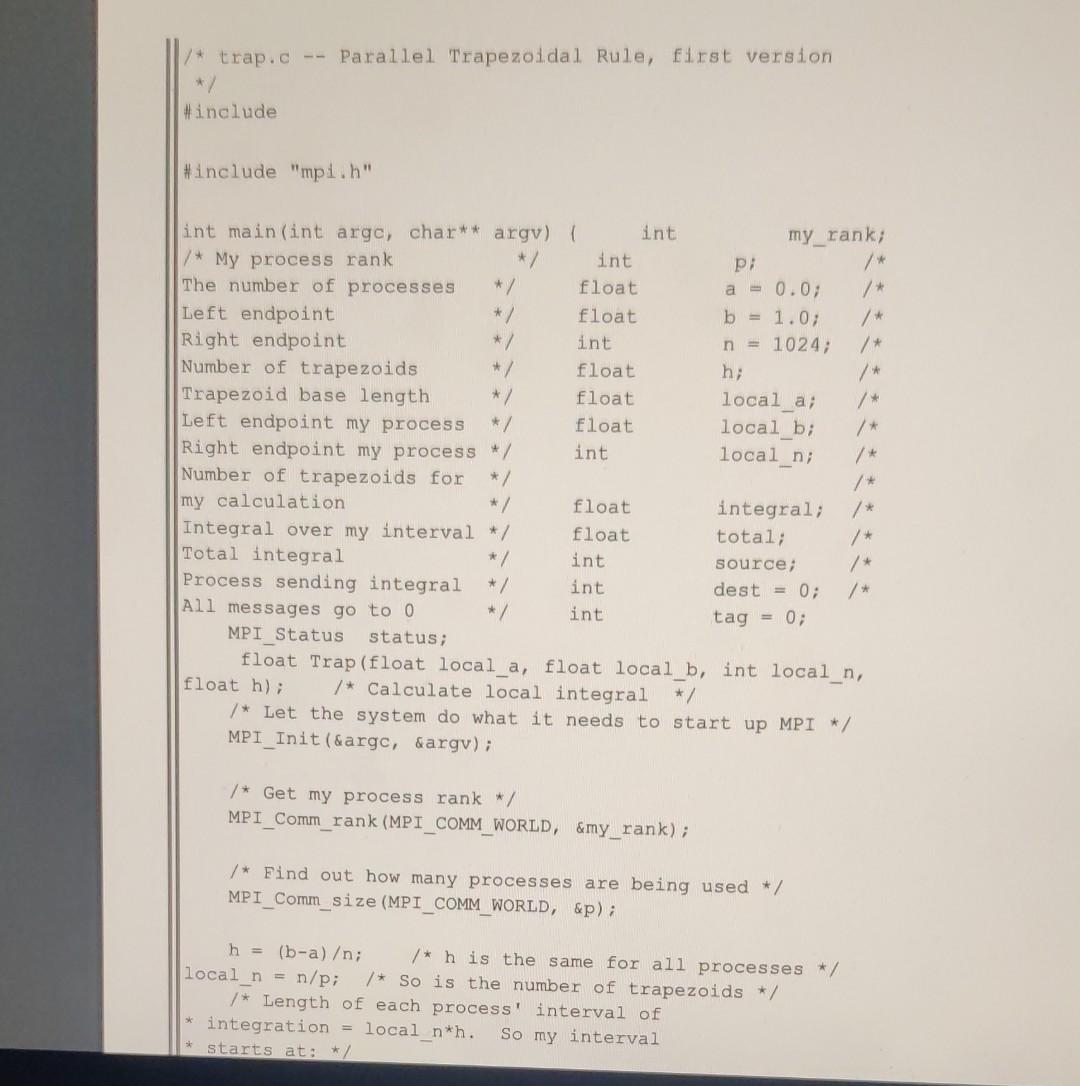
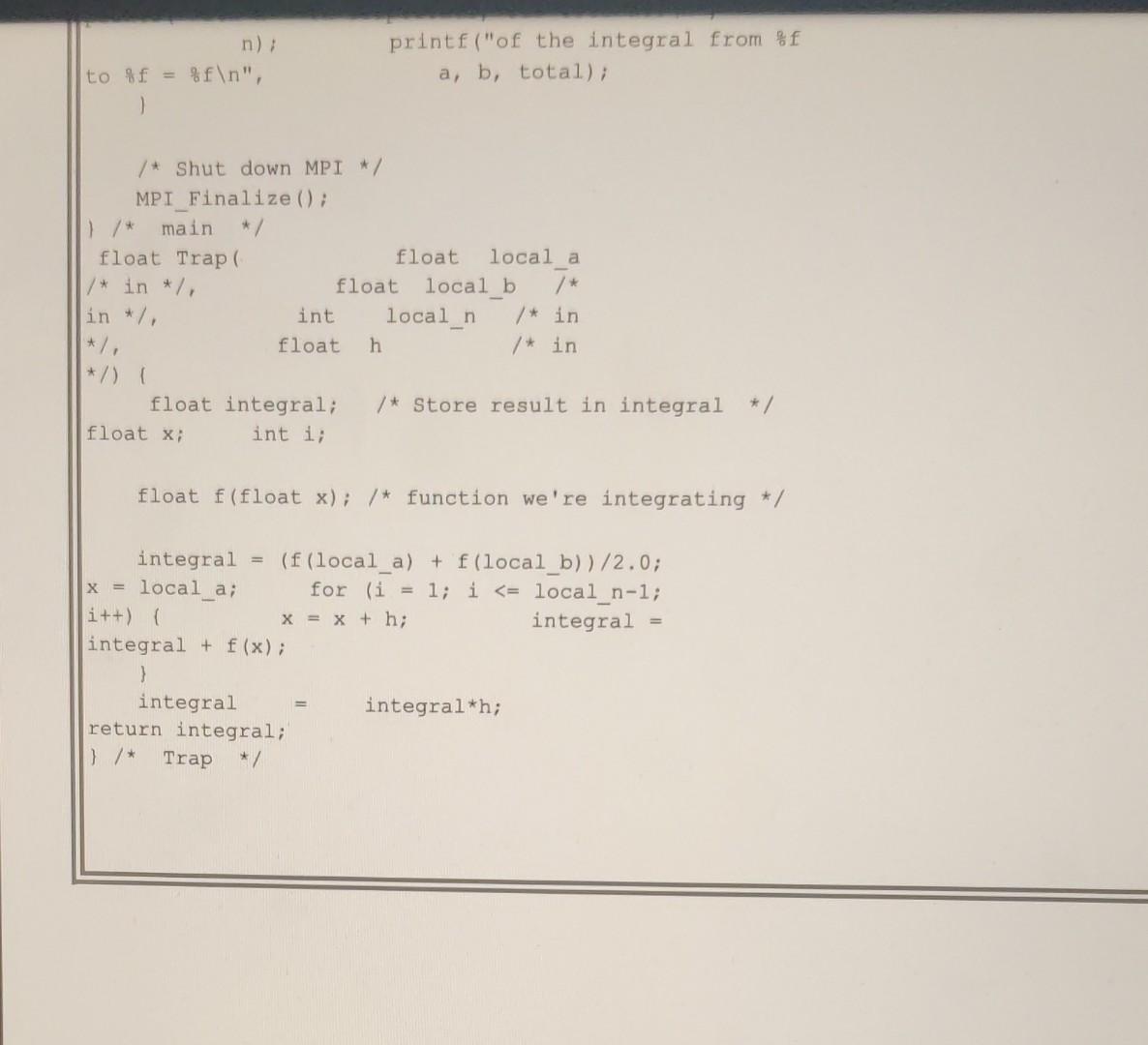
Problem 1 - Chunk Matrix Multiply - Consider the Chunk Matrix multiplication depicted in the diagram below, where example chunks distributed are shown with shading in the diagram (unshaded diagrams are similarly distributed). Problem 1.1 - Write expressions, using values from the A and B matrices (ie. A(1,i) and B(1,j) to show the expressions that would be computed and the results for the two positions indicated in the C matrix, labeling your answers Box1 and Box2. Be sure to show in detail each A(1,j) and B(1,j) in your expressions. Box1: Box2: A(1,0)B(0,2)+A(1,1)B(1,2)+A(1,2)B(2,2)+A(1,3)B(3,2)=670A(3,0)B(0,1)+A(3,1)B(1,1)+A(3,2)B(2,1)+A(3,3)B(3,1)=1412 Problem 1.2 - Briefly describe advantages and disadvantages of Matrix Chunk Distribution, compared to a distribution by row and column and when you would use a Chunk approach instead of Row and Column. Matrix Chunk Distribution is used to reduce calculations of matrices, column-row expansions and in computer science applications. It is also used in VLSI chip design. The Strassen algorithm is used for faster multiplication and the hamming encoding is used for error detection in data transmissions. The concept of partitioning brings useful advantages using its greater flexibility. The partitioning can also be considered as a data management tool that organizes the transfer of information between main memory and the auxiliary devices. Also, in sparse matrix technology, partitioning plays an important role because many algorithms are designed primarily for matrices of numbers that can be generalized to operate on matrices of matrices. Most algorithms are blockable. A major software development of blocked algorithms for linear algebra has been conducted. For example, in the solution of differential equations by the difference and the variational methods, are abundant. Such codes have been rewritten as block methods to use the small memory and the large ssd on cray supercomputers in a better way. These kinds of examples have shown that blocking is advantageous for squeezing the best possible performance out of the advanced architectures. But, a blocked code is much more difficult to write and to understand as compared to a point code. Writing it is a big error-prone job. It introduces block size parameters that need to be adjusted for each computer and each algorithm even when they have nothing to do with the problem being solved. Unfortunately, not having blocked code causes poor performance on even the most powerful computers available. Problem 1.3 - How would the sizes of the matrices involved affect whether you would use a Chunk Multiply approach or Row and Column? The time complexity for row and column is O(N3). We can use chunk multiply so it would be O(M3). Where M
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts