

Question: Part 1 pls Problem 1. Consider the MDP with the transition model, reward function, and V0 as given in the Tables 1,2 , and 3
 Part 1 pls
Part 1 pls
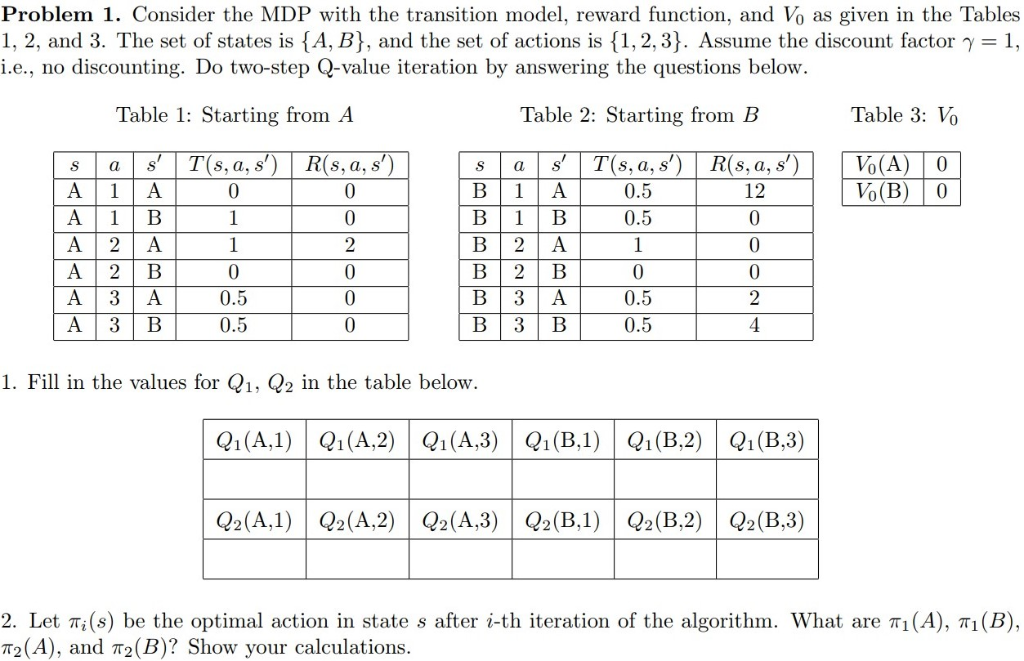
Problem 1. Consider the MDP with the transition model, reward function, and V0 as given in the Tables 1,2 , and 3 . The set of states is {A,B}, and the set of actions is {1,2,3}. Assume the discount factor =1, i.e., no discounting. Do two-step Q-value iteration by answering the questions below. Table 1: Starting from A Table 2: Starting from B Table 3: V0 1. Fill in the values for Q1,Q2 in the table below. 2. Let i(s) be the optimal action in state s after i-th iteration of the algorithm. What are 1(A),1(B), 2(A), and 2(B) ? Show your calculations
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock