

Question: Please refer to the following textbook: Distributed and Cloud Computing 1st edition From Parallel Processing to the Internet of Things ISBN: 0123858801 ISBN-13: 9780123858801 Authors:Kai

Please refer to the following textbook:
Distributed and Cloud Computing 1st edition
From Parallel Processing to the Internet of Things
ISBN:
0123858801
ISBN-13:
9780123858801
Authors:Kai Hwang Jack Dongarra Geoffrey Fox Geoffrey C Fox
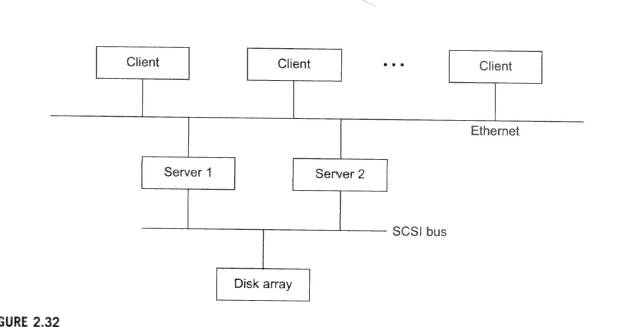
Problem 2.14 Consider in Figure 2.32 a server-client cluster with an active-takeover configuration between two identical servers. The servers share a disk via a SCSI bus. The clients (PCs or workstations) and the Ethernet are fail-free. When a server fails, its workload is switched to the surviving server a. Assume that each server has an MTTF of 200 days and an MTTR of five days. The disk has an MTTF of 800 days and an MTTR of 20 days. In addition, each server is shut down for maintenance for one day every week, during which time that server is considered unavailable Only one server is shut down for maintenance at a time. The failure rates cover both natural failures and scheduled maintenance. The SCSI bus has a failure rate of 2 percent. The servers and the disk fail independently. The disk and SCSI bus have no scheduled shutdown. The client machine will never fail. availability of the two servers? available simultaneously. What are the possible single points of failure in this cluster? 1. The servers are considered available if at least one server is available. What is the combined 2. In normal operation, the cluster must have the SCSI bus, the disk, and at least one server b. The cluster is considered unacceptable if both servers fail at the same time. Furthermore, the cluster is declared unavailable when either the SCSI bus or the disk is down. Based on the aforementioned conditions, what is the system availability of the entire cluster? c. Under the aforementioned failure and maintenance conditions, propose an improved architecture to eliminate all single points of failure identified in Part (a) Problem 2.14 Consider in Figure 2.32 a server-client cluster with an active-takeover configuration between two identical servers. The servers share a disk via a SCSI bus. The clients (PCs or workstations) and the Ethernet are fail-free. When a server fails, its workload is switched to the surviving server a. Assume that each server has an MTTF of 200 days and an MTTR of five days. The disk has an MTTF of 800 days and an MTTR of 20 days. In addition, each server is shut down for maintenance for one day every week, during which time that server is considered unavailable Only one server is shut down for maintenance at a time. The failure rates cover both natural failures and scheduled maintenance. The SCSI bus has a failure rate of 2 percent. The servers and the disk fail independently. The disk and SCSI bus have no scheduled shutdown. The client machine will never fail. availability of the two servers? available simultaneously. What are the possible single points of failure in this cluster? 1. The servers are considered available if at least one server is available. What is the combined 2. In normal operation, the cluster must have the SCSI bus, the disk, and at least one server b. The cluster is considered unacceptable if both servers fail at the same time. Furthermore, the cluster is declared unavailable when either the SCSI bus or the disk is down. Based on the aforementioned conditions, what is the system availability of the entire cluster? c. Under the aforementioned failure and maintenance conditions, propose an improved architecture to eliminate all single points of failure identified in Part (a)
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts