

Question: Please write Python code in an original and efficient manner. It should be both original and capable of working efficiently. import numpy import pandas class
Please write Python code in an original and efficient manner. It should be both original and capable of working efficiently.
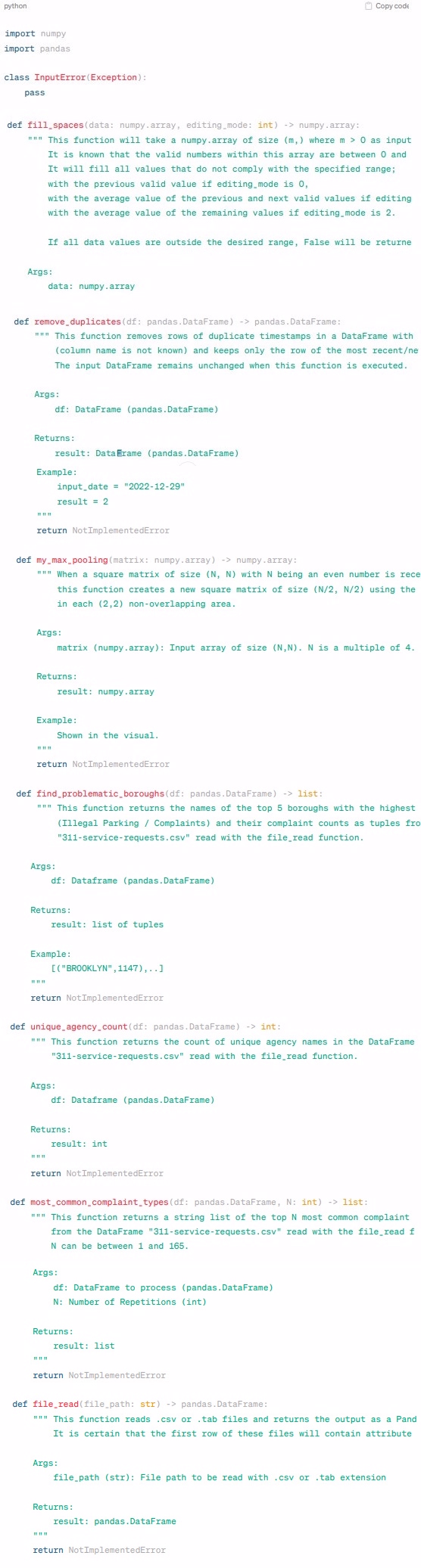
import numpy
import pandas
class InputErrorException:
pass
def fillspacesdata: numpy.array, editingmode: int numpy.array:
This function will take a numpy.array of size m where m as input.
It is known that the valid numbers within this array are between and
It will fill all values that do not comply with the specified range;
with the previous valid value if editingmode is
with the average value of the previous and next valid values if editingmode is
with the average value of the remaining values if editingmode is
If all data values are outside the desired range, False will be returned.
Args:
data: numpy.array
Returns:
result: numpy.array or bool False
Example:
data: numpy.array
editingmode:
result: numpy.array
editingmode:
result: numpy.array
editingmode:
result: numpy.array
return NotImplementedError
def removeduplicatesdf: panclass InputErrorException:
pass
def fillspacesdata: numpy.array, editingmode: int numpy.array:
This function will take a numpy.array of size where as input
It is known that the valid numbers within this array are between and
It will fill all values that do not comply with the specified range;
with the previous valid value if editingmode is
with the average value of the previous and next valid values if editing
with the average value of the remaining vadas.DataFrame pandas.DataFrame:
This function removes rows of duplicate timestamps in a DataFrame with timestamps in its first column
column name is not known and keeps only the row of the most recentnewest timestamp in the DataFrame.
The input DataFrame remains unchanged when this function is executed.
Args:
df: DataFrame pandasDataFrame
Returns:
result: DataFrame pandasDataFrame
Example:
Shown in the visual.
return NotImplementedError
def daysuntilendofyearinputdate: str int:
This function returns the number of days left until the end of the year when a date in the format of YYYYMMDD is received.
The current day is not counted.
Args:
inputdate: str
Returns:
result: int
Example:
inputdate
result
return NotImplementedError
def mymaxpoolingmatrix: numpy.array numpy.array:
When a square matrix of size N N with N being an even number is received as input,
this function creates a new square matrix of size N N using the maximum number
in each nonoverlapping area.
Args:
matrix numpyarray: Input array of size NN N is a multiple of
Returns:
result: numpy.array
Example:
Shown in the visual.
return NotImplementedError
def findproblematicboroughsdf: pandas.DataFrame list:
This function returns the names of the top boroughs with the highest number of illegal parking complaints
Illegal Parking Complaints and their complaint counts as tuples from the DataFrame
servicerequests.csv read with the fileread function.
Args:
df: Dataframe pandasDataFrame
Returns:
result: list of tuples
Example:
BROOKLYN
return NotImplementedError
def uniqueagencycountdf: pandas.DataFrame int:
This function returns the count of unique agency names in the DataFrame
servicerequests.csv read with the fileread function.
Args:
df: Dataframe pandasDataFrame
Returns:
result: int
return NotImplementedError
def mostcommoncomplainttypesdf: pandas.DataFrame, N: int list:
This function returns a string list of the top N most common complaint types
from the DataFrame servicerequests.csv read with the fileread function.
N can be between and
Args:
df: DataFrame to process pandasDataFrame
N: Number of Repetitions int
Returns:
result: list
return NotImplementedError
def filereadfilepath: str pandas.DataFrame:
This function reads csv or tab files and returns the output as a Pandas DataFrame.
It is certain that the first row of these files will contain attribute names.
Args:
filepath str: File path to be read with csv or tab extension
Returns:
result: pandas.DataFrame
return NotImplementedError
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock