

Question: Problem 2: Decision Trees for Spam Classification (30 points) We'll use the same data as in our earlier homework: In order to reduce my email
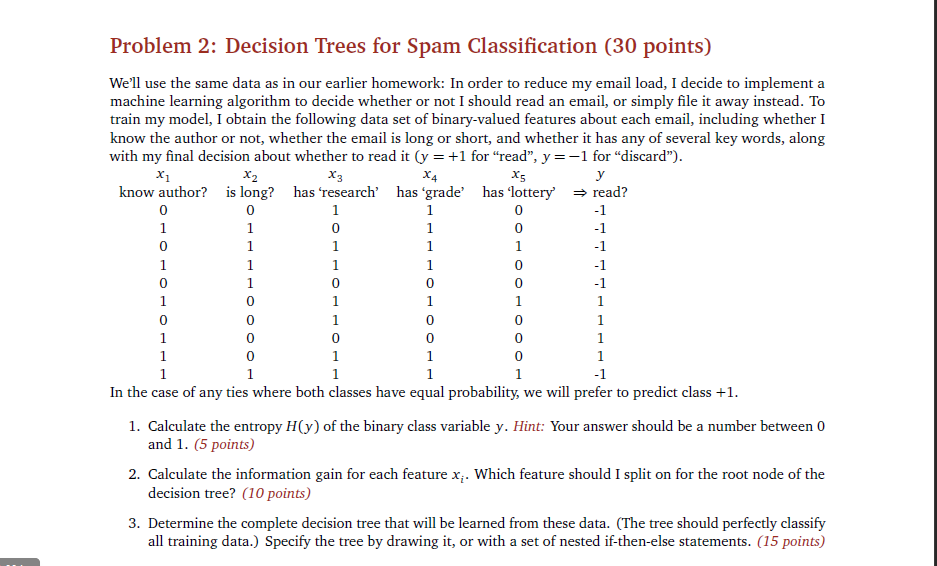
Problem 2: Decision Trees for Spam Classification (30 points) We'll use the same data as in our earlier homework: In order to reduce my email load, I decide to implement a machine learning algorithm to decide whether or not I should read an email, or simply file it away instead. To train my model, I obtain the following data set of binary-valued features about each email, including whether I know the author or not, whether the email is long or short, and whether it has any of several key words, along with my final decision about whether to read it(y = +1 for "read", y =-1 for "discard") know author? is long? has 'research, has 'grade, has lottery' read? 0 0 0 0 0 0 In the case of any ties where both classes have equal probability, we will prefer to predict class +1 1. Calculate the entropy H(y) of the binary class variable y. Hint: Your answer should be a number between 0 2. Calculate the information gain for each feature x. Which feature should I split on for the root node of the 3. Determine the complete decision tree that will be learned from these data. (The tree should perfectly classify and 1. (5 points) decision tree? (10 points) all training data.) Specify the tree by drawing it, or with a set of nested if-then-else statements. (15 points) Problem 2: Decision Trees for Spam Classification (30 points) We'll use the same data as in our earlier homework: In order to reduce my email load, I decide to implement a machine learning algorithm to decide whether or not I should read an email, or simply file it away instead. To train my model, I obtain the following data set of binary-valued features about each email, including whether I know the author or not, whether the email is long or short, and whether it has any of several key words, along with my final decision about whether to read it(y = +1 for "read", y =-1 for "discard") know author? is long? has 'research, has 'grade, has lottery' read? 0 0 0 0 0 0 In the case of any ties where both classes have equal probability, we will prefer to predict class +1 1. Calculate the entropy H(y) of the binary class variable y. Hint: Your answer should be a number between 0 2. Calculate the information gain for each feature x. Which feature should I split on for the root node of the 3. Determine the complete decision tree that will be learned from these data. (The tree should perfectly classify and 1. (5 points) decision tree? (10 points) all training data.) Specify the tree by drawing it, or with a set of nested if-then-else statements. (15 points)
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts