

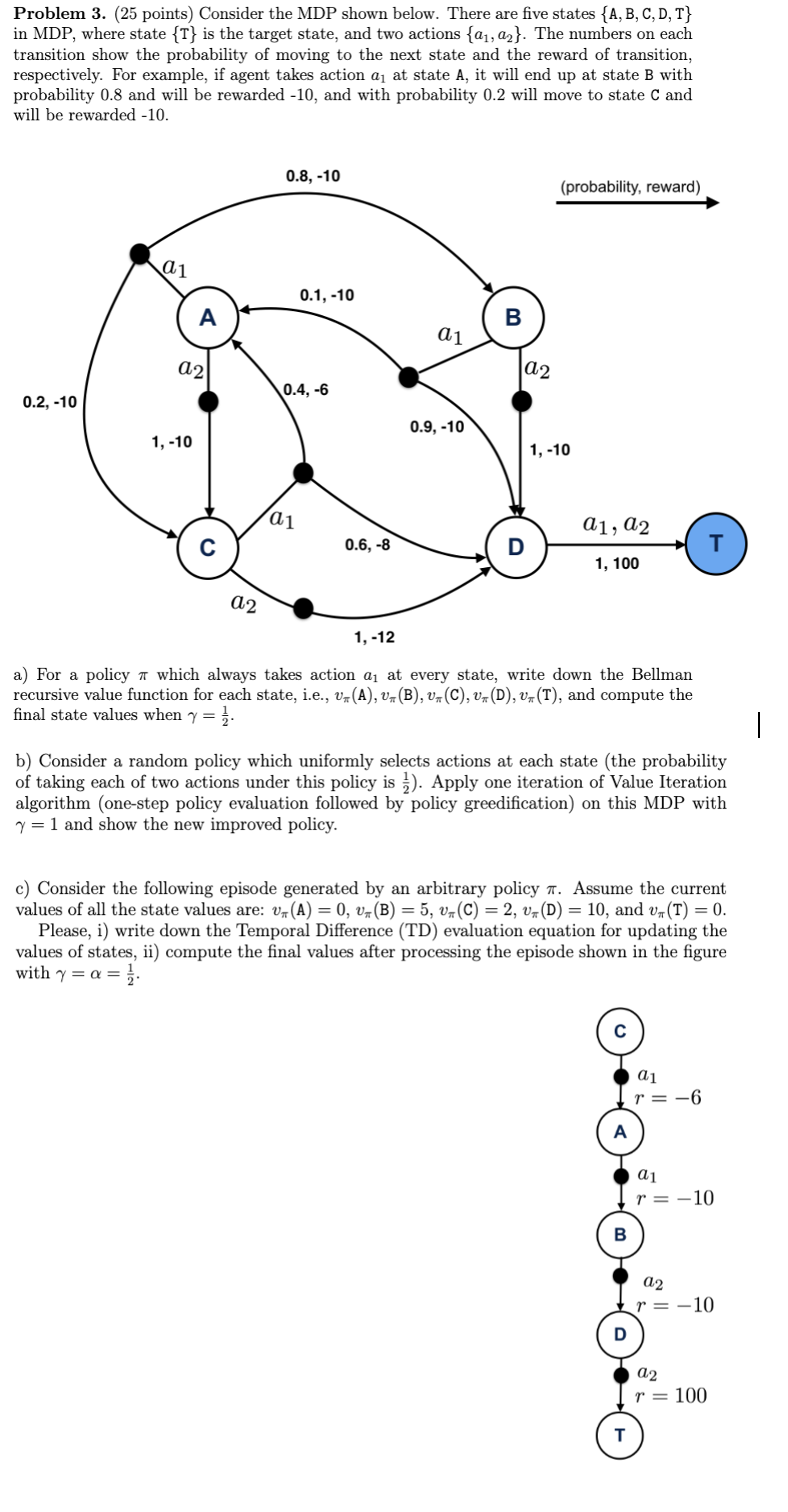
Question: Problem 3 . ( 2 5 points ) Consider the MDP shown below. There are five states { A , B , C , D
Problem points Consider the MDP shown below. There are five states in MDP where state is the target state, and two actions The numbers on each transition show the probability of moving to the next state and the reward of transition, respectively. For example, if agent takes action at state A it will end up at state B with probability and will be rewarded and with probability will move to state and will be rewarded
a For a policy which always takes action at every state, write down the Bellman recursive value function for each state, ie and compute the final state values when
b Consider a random policy which uniformly selects actions at each state the probability of taking each of two actions under this policy is Apply one iteration of Value Iteration algorithm onestep policy evaluation followed by policy greedification on this MDP with and show the new improved policy.
c Consider the following episode generated by an arbitrary policy Assume the current values of all the state values are: and
Please, i write down the Temporal Difference TD evaluation equation for updating the values of states, ii compute the final values after processing the episode shown in the figure with
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock